My AI Portfolio — Evidence of Daily AI Work | Original
I don’t just talk about AI — I use it every day, at scale. This post is a visual portfolio of my AI effort: the tools I’ve built, the tokens I’ve consumed, and the certifications I’ve earned.
🖥️ LLM Training & Inference — My Hardware Setup
Built my machine learning workstation in 2023 and have been training and learning ever since.
Hardware experience:
| GPU | VRAM | Experience | Where |
|---|---|---|---|
| NVIDIA RTX 4070 | 12 GB | 3 years | Home workstation |
| NVIDIA H200 | 141 GB | 3 months | RunPod / DigitalOcean |
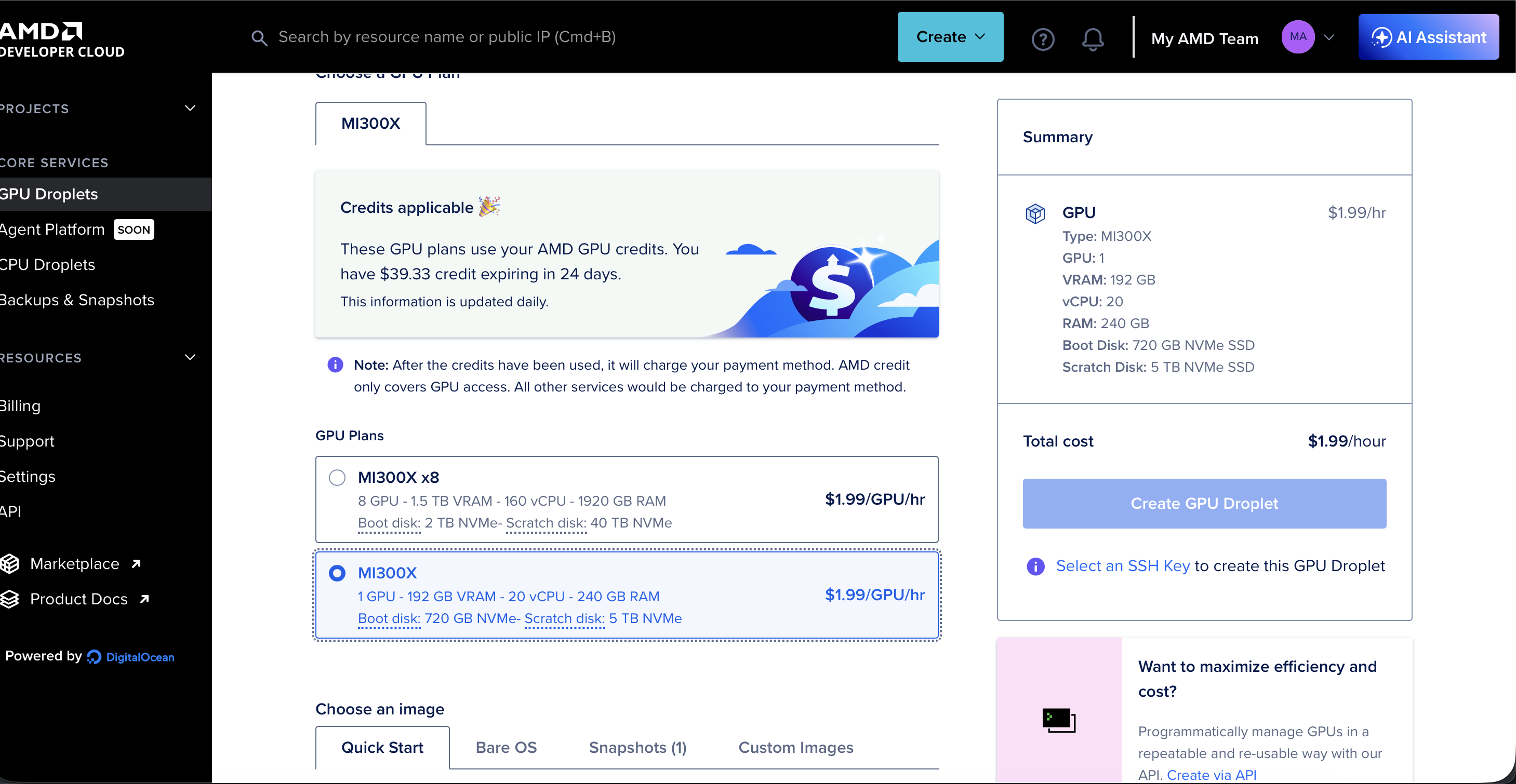
| AMD MI300X | 192 GB HBM3 | 3 months | AMD Developer Cloud |
What I’ve trained:
- GPT-2 124M from scratch on FineWeb dataset (nanoGPT) — on RTX 4070, H200, and MI300X.
- GPT-2 760M from scratch on AMD MI300X (192 GB HBM3) — exploring nanochat, DeepSeek v4 MoE.
- Various experiments on hyperparameter tuning, learning rate schedules, and dataset preprocessing.
The workstation:

AMD Developer Cloud — MI300X 192GB HBM3:
🧠 Enhanced nanoGPT — My Fork
Forked karpathy/nanoGPT and extended it with additional dataset pipelines, scaled training configs, and inline shape annotations for learning. 45 commits, Nov 2025 – Apr 2026.
New dataset pipelines:
| Dataset | Path | Description |
|---|---|---|
| FineWeb-Edu | data/fineweb/ |
HuggingFace FineWeb-Edu (10B+ tokens). Shard-based loading, chunked processing, incremental train/val splits. |
| OpenWebText 10k | data/openwebtext_10k/ |
Quick 10k-subset for fast iteration. |
| Wikipedia Local | data/wikipedia_local/ |
Tokenize local plain-text dump directly (no HuggingFace download). |
Training configs added:
| Config | Target | Notes |
|---|---|---|
train_fineweb.py |
125M on FineWeb | Tuned for RTX 4070 12 GB (n_embd=384, dropout=0.1). |
train_fineweb1_5b.py |
1.5B on FineWeb | For H200 80 GB. |
train_fineweb_gpt3.py |
GPT-3 style 10B tokens | Shard-based loader, wider schedule. |
train_fineweb_760m.py |
760M on FineWeb | For MI300X 192 GB HBM3. |
train_gpt2_200m.py |
GPT-2 200M | General-purpose mid-size config. |
train_gpt2_200m_smoke.py |
Smoke test | Quick 200M sanity check (~few min). |
Model changes:
- Inline tensor shape comments throughout
model.pyforward passes (CausalSelfAttention, MLP, GPT) — shows exact shapes at every step with concrete GPT-2 XL examples, e.g.# x: (B, T, C) e.g. (1, 5, 1600). Useful for understanding the transformer data flow.
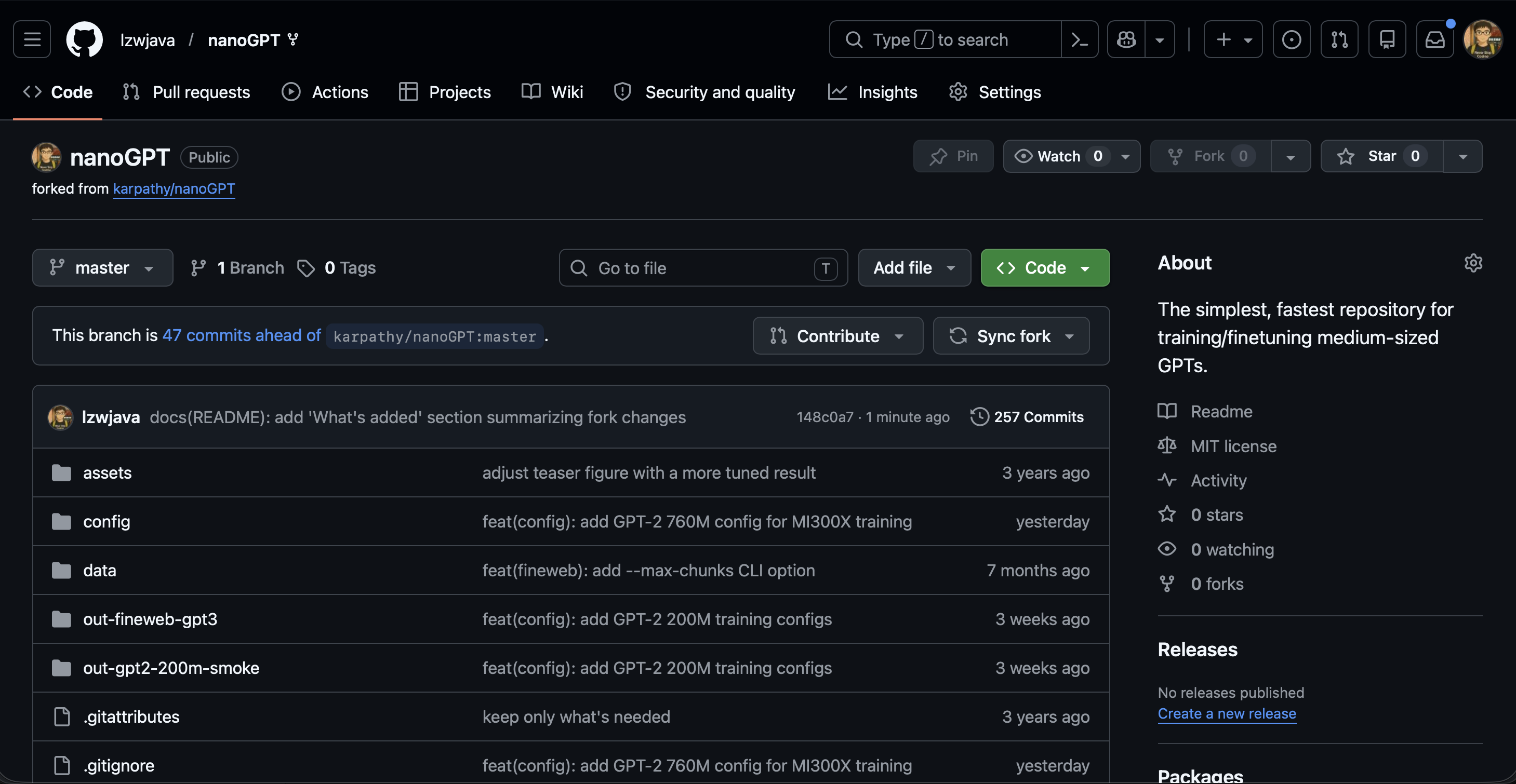
GitHub: lzwjava/nanoGPT
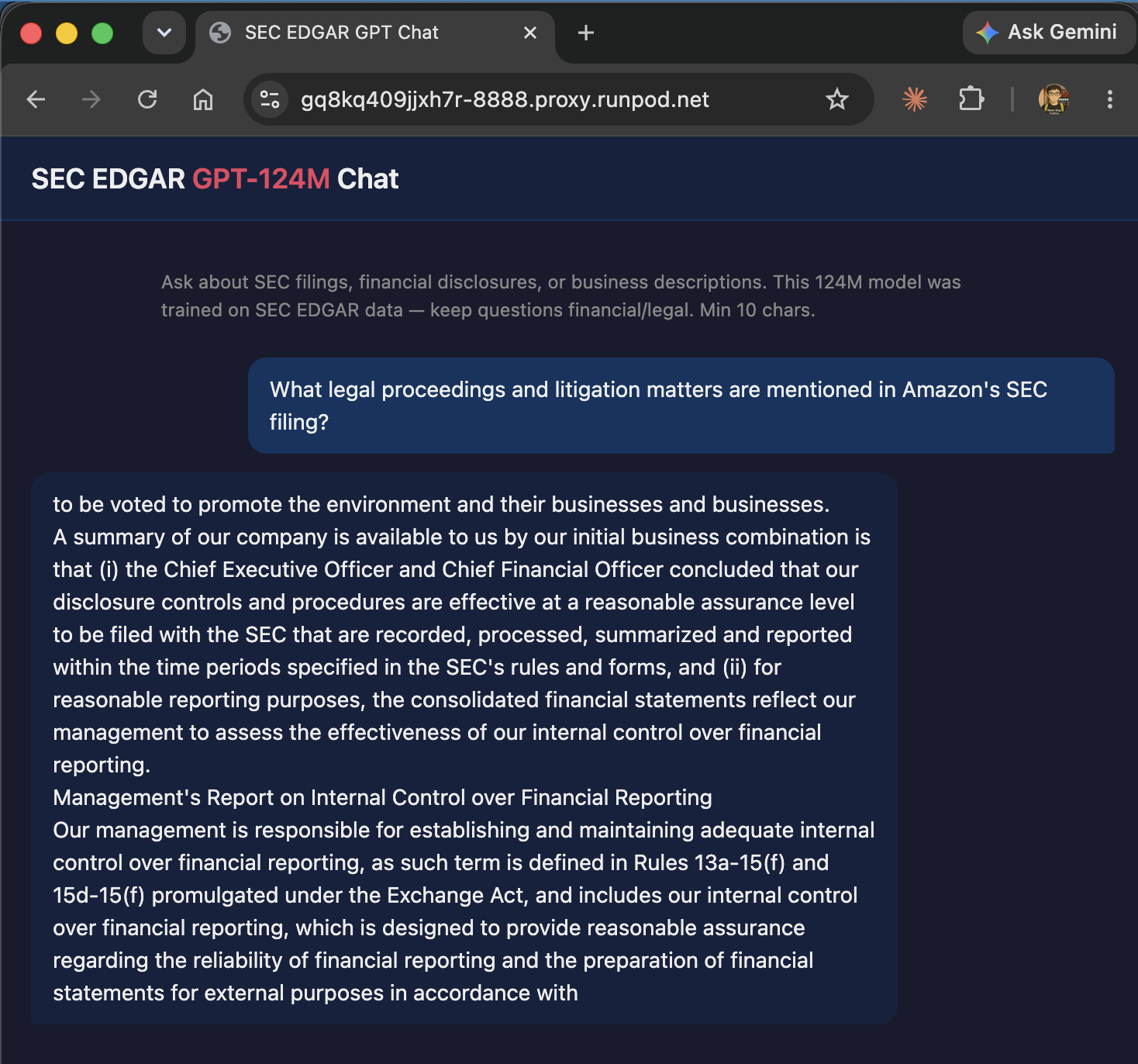
📝 SEC-EDGAR-GPT — GPT-2 (124M) Trained from Scratch on SEC Filings
Trained a 124M-parameter GPT-2 from scratch on 1.55B tokens of SEC EDGAR financial filings (10-K, 10-Q, and other corporate disclosures) — trained for ~8 hours on a single RTX 4070 (12 GB VRAM), converging to a validation loss of 2.28.
The model generates convincing SEC boilerplate — risk factors, MD&A sections, business descriptions — and is deployed for interactive chat via a FastAPI server on RunPod.
Built the entire project — model training, paper, chatbot, and website — in 3 days using Hermes Agent, demonstrating how AI agents make LLM research accessible.
Shared inside a global bank, the project garnered 200+ views internally. A principal engineer left a comment calling it “nice”. Also, inspired by a friend’s work on recurrent transformers, this project got me thinking about treating financial tokens differently from natural language tokens to improve generation accuracy.
Code: github.com/lzwjava/sec-edgar-gpt · Paper: sec-edgar-gpt.pdf · Model: Hugging Face · Chat: sec-edgar-gpt.lzwjava.workers.dev
📊 LLM API Usage — The Numbers
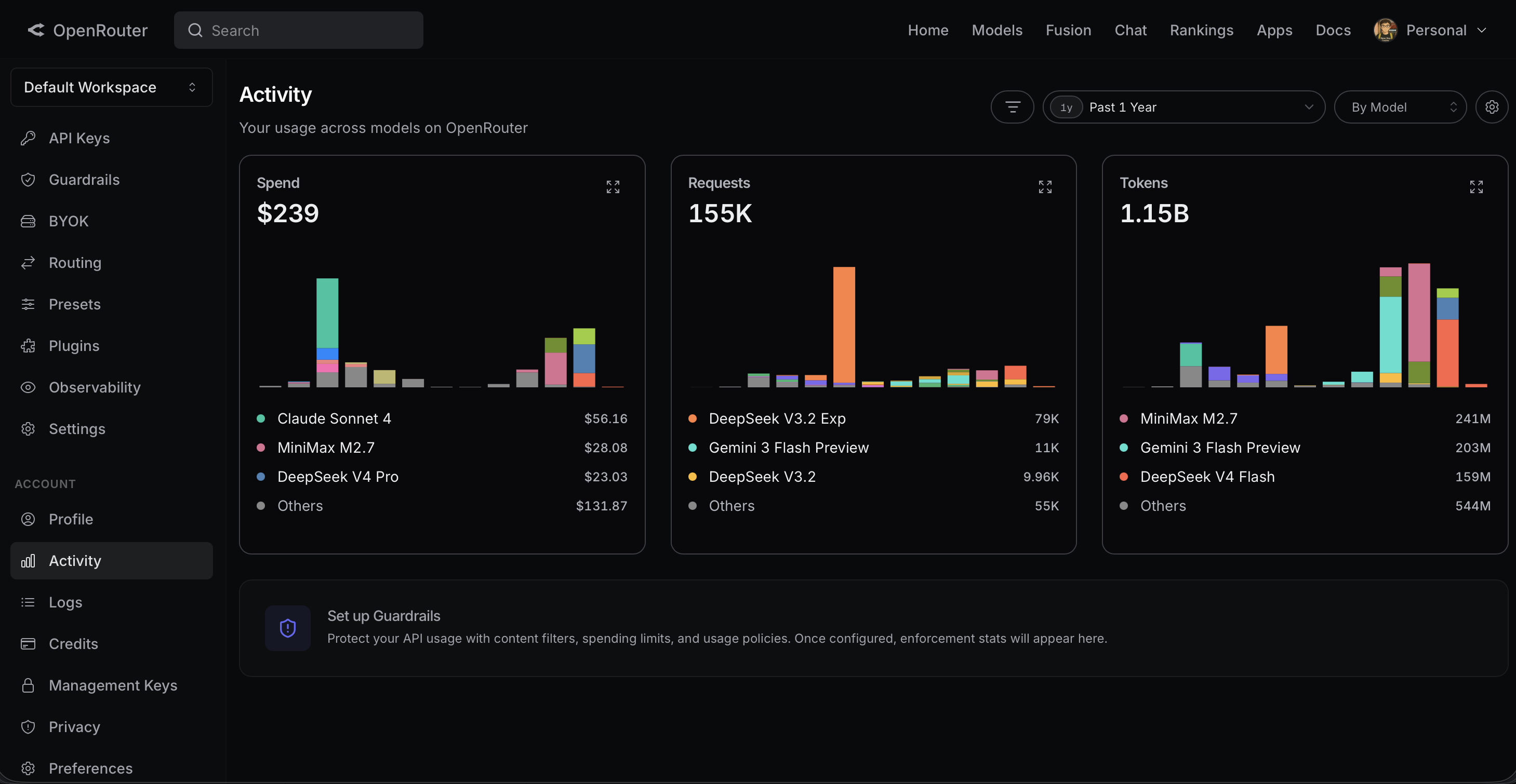
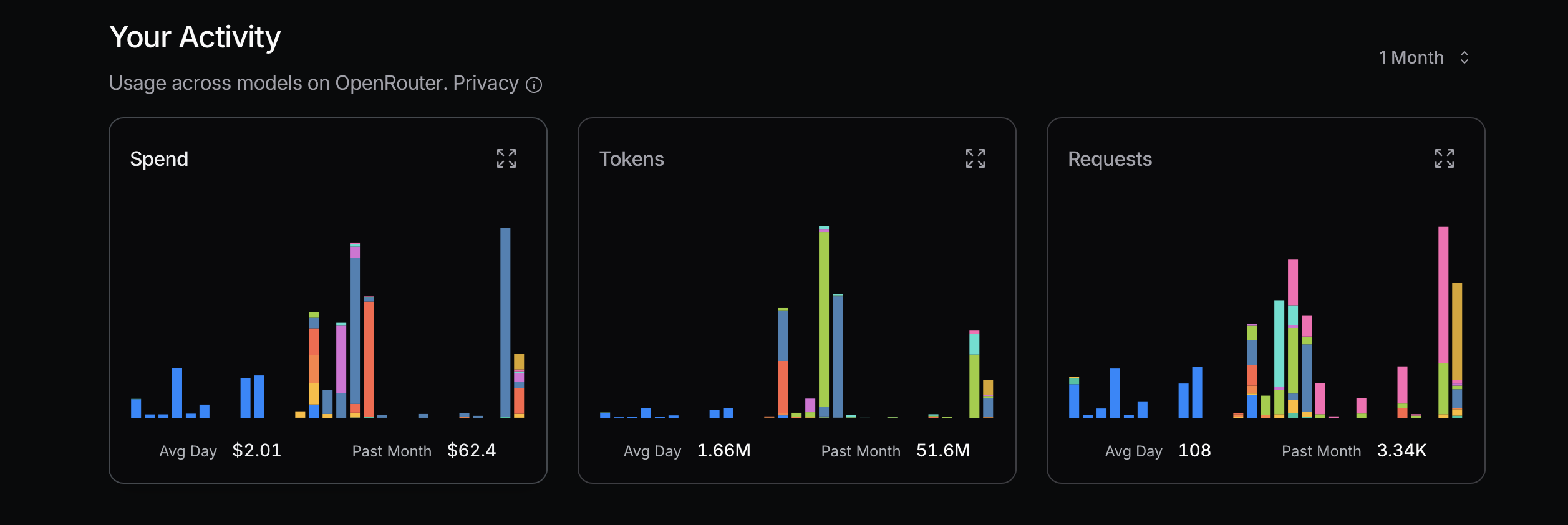
OpenRouter — Past Year
1.15B tokens consumed, $239 spend, 155K API requests across multiple models.
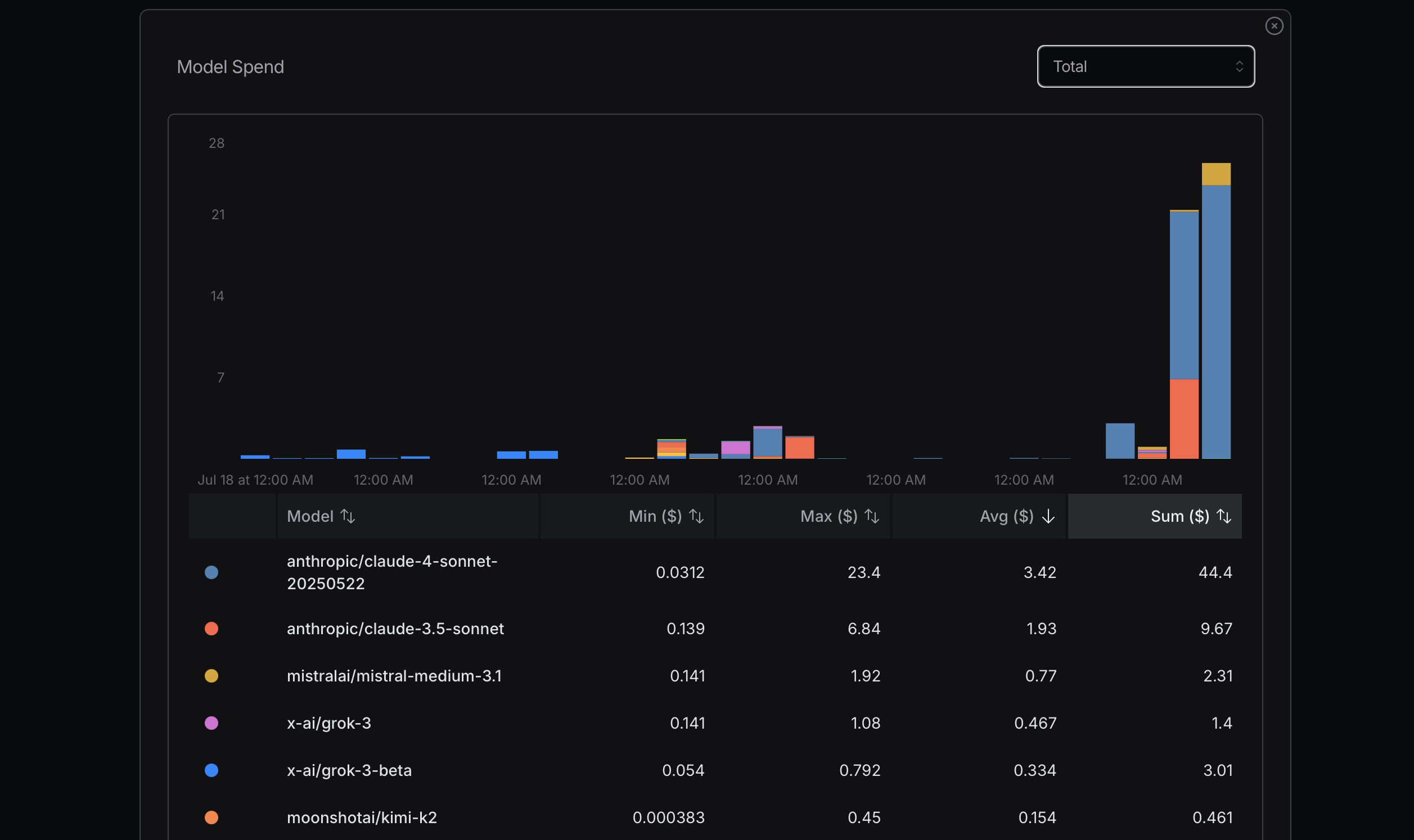
Claude API via SSSAICode — April 2026
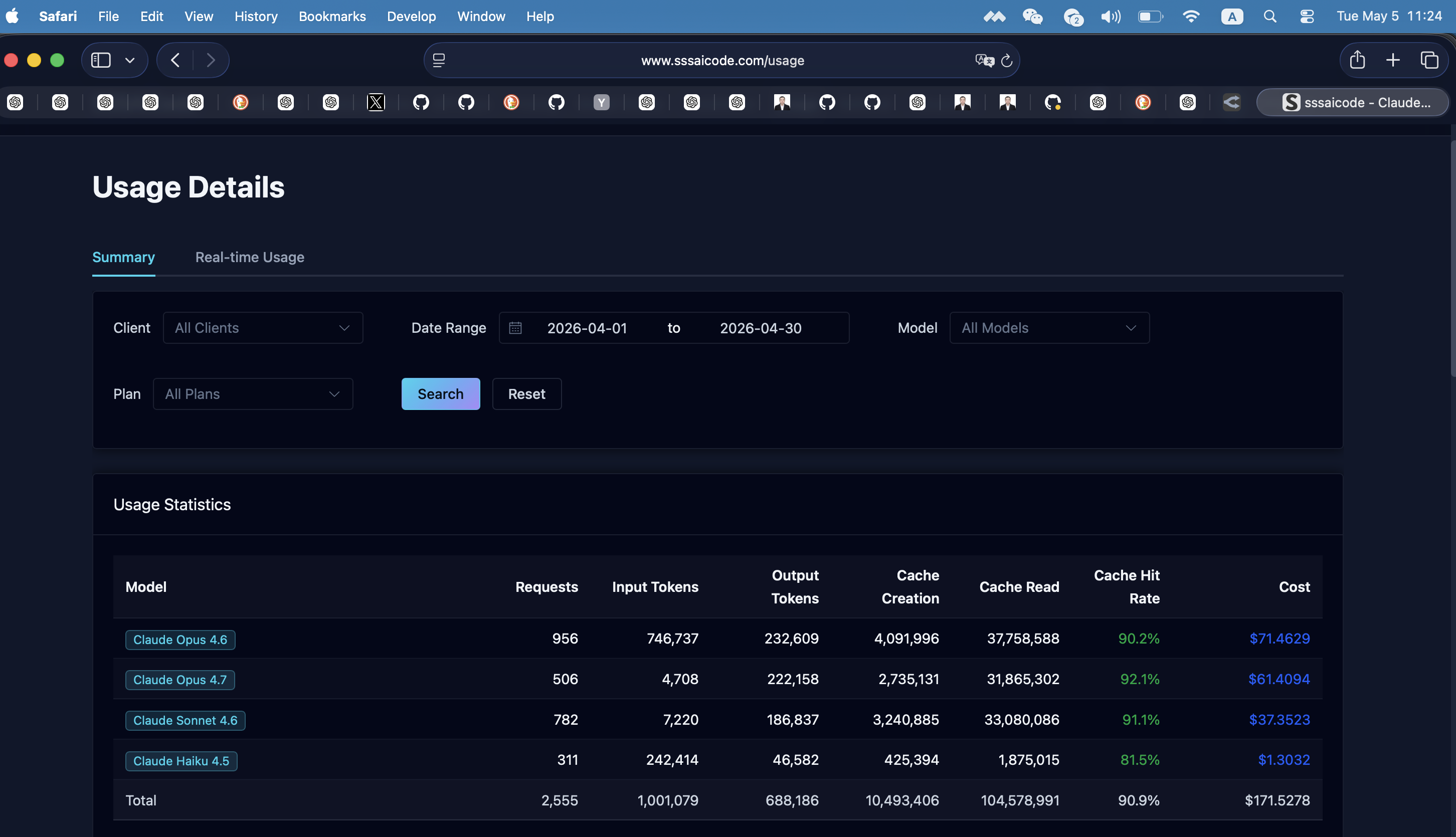
$171.53 in one month. 2,555 requests. 115M+ tokens. 90.9% cache hit rate.
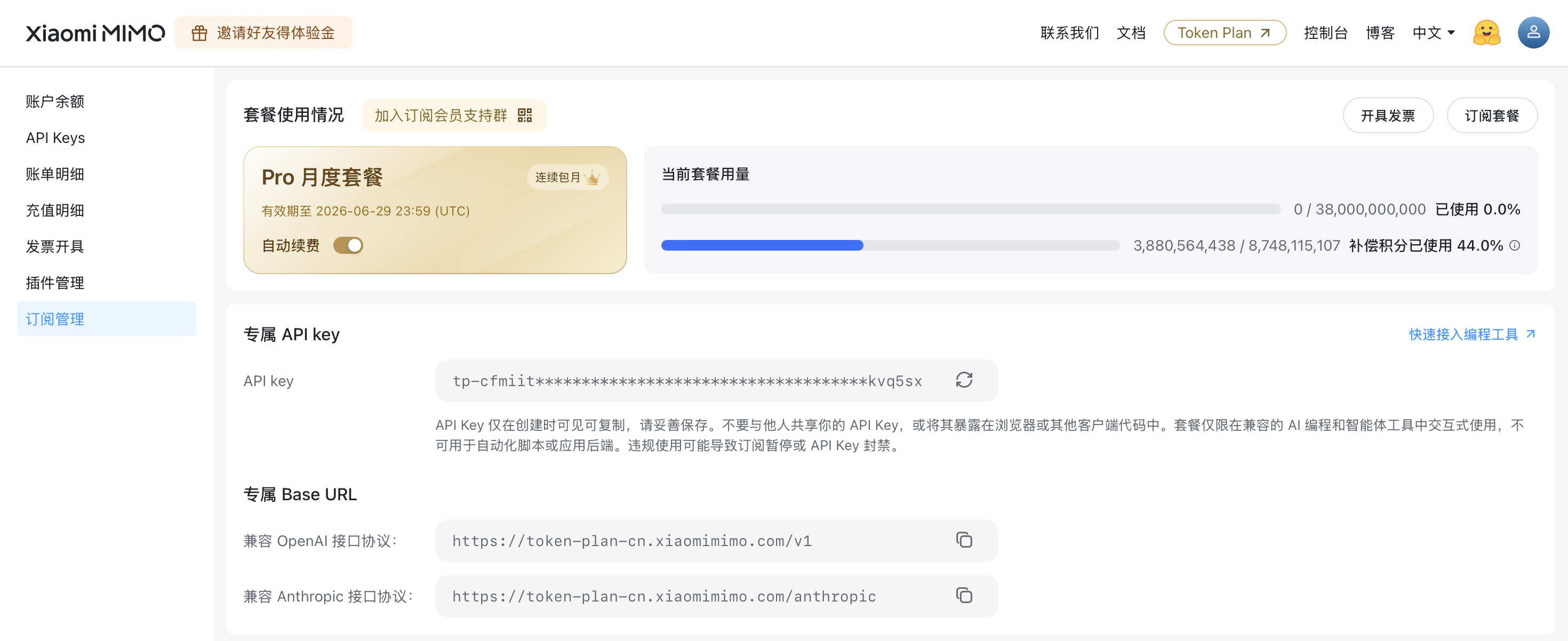
Xiaomi MIMO Subscription — 1.25 Billion Tokens Used
Pro Monthly Plan with 38B main quota + 8.75B compensation quota (~4.6B free credit). 1.25B tokens consumed across May–June 2026.
Monthly Token Usage Breakdown
| Month | Model | Total Tokens | Input (Cache Hit) | Input (Cache Miss) | Output | Requests |
|---|---|---|---|---|---|---|
| 2026-06 | mimo-v2.5 | 285,179 | 36,416 | 143,556 | 105,207 | 78 |
| 2026-06 | mimo-v2.5-pro | 734,873,374 | 710,036,672 | 21,617,131 | 3,219,571 | 10,704 |
| 2026-05 | mimo-v2.5 | 91,203 | 5,312 | 52,908 | 32,983 | 27 |
| 2026-05 | mimo-v2.5-pro | 508,851,211 | 488,291,136 | 17,725,731 | 2,834,344 | 8,649 |
| 2026-05 | mimo-v2-pro | 3,571,328 | 3,021,568 | 539,357 | 10,403 | 167 |
Monthly totals: May 2026: 512.5M tokens (8,843 requests) · June 2026: 735.2M tokens (10,782 requests)
mimo-v2.5-pro dominates usage (~96% of total). Cache hit rate ~96.7% on mimo-v2.5-pro keeps costs efficient. June shows 43.5% growth over May in token volume.
Summary
| Platform | Tokens | Period | Cost |
|---|---|---|---|
| OpenRouter | 1.15B | Past year | $239 |
| SSSAICode (Claude) | 115M+ | April 2026 | $171.53 |
| Xiaomi MIMO | 1.25B | May–Jun 2026 | Free 4.6B credit |
| Others (GitHub Copilot, etc.) | 500M | Past year | — |
| Total | ~3.0B+ | Past year | — |
🏢 Enterprise AI Usage — HSBC Bank
At HSBC Bank (via TEKsystems), I built an autonomous AI agent layer on top of GitHub Copilot to automate scripting, logging, documentation, and testing.
What I built:
- 20 customized AI agents — dedicated prompts and contexts for different tech stacks and workflows.
- 400 reusable Copilot-written scripts — automation for common tasks across Java, Spring, Python, Angular, and DevOps tooling.
- 1,100 Copilot-written guides — documentation generated and validated via LLM outputs with caching and validation.
- ~70 test cases auto-generated via Copilot API — covering Spring Filters, Python unittest, JSON truncation, prompt engineering, and regional endpoints.
Results:
- Ranked top 6% in Copilot usage across the entire enterprise, measured by premium requests.
- Earned a Contribution Award for the high-profile AIPlayer project.
- Joined HSBC’s internal AI community.

🎤 AI Talk at HSBC — From Neural Networks to Agents
Gave a technical talk to 80 participants at HSBC Bank — senior consultants, specialists, associate directors, software engineers, and contractors.
Talk: “From Neural Networks to Agents” — a journey from the simplest neural network (y = wx) through MNIST, Transformers, GPT, nanoGPT, to building personal AI agents.
What I covered:
- Neural networks from first principles — forward pass, backpropagation, gradient descent
- Transformer architecture — Q/K/V attention, multi-head attention, positional encoding
- GPT internals — tokenization, embedding, training, generation
- nanoGPT — training GPT-2 from scratch on H200/RTX 4070
- LLM agents — Claude Code, OpenClaw, Hermes, tool calling, agent loops
- Real numbers — 1B tokens consumed, H200 at $3.44/hr, where money actually goes
- My path — 3 years from reading about Q/K/V to training models from scratch
Feedback:
- A junior engineer said: “You are the person I want to be” — the talk opened his mind to what’s possible with AI
- Senior engineers appreciated the first-principles approach — no hype, just math and code
- Multiple follow-up conversations about training, agents, and career direction
Slides: Built with Claude Code & Marp, from my public AI response notes.
Slides (Marp): PDF
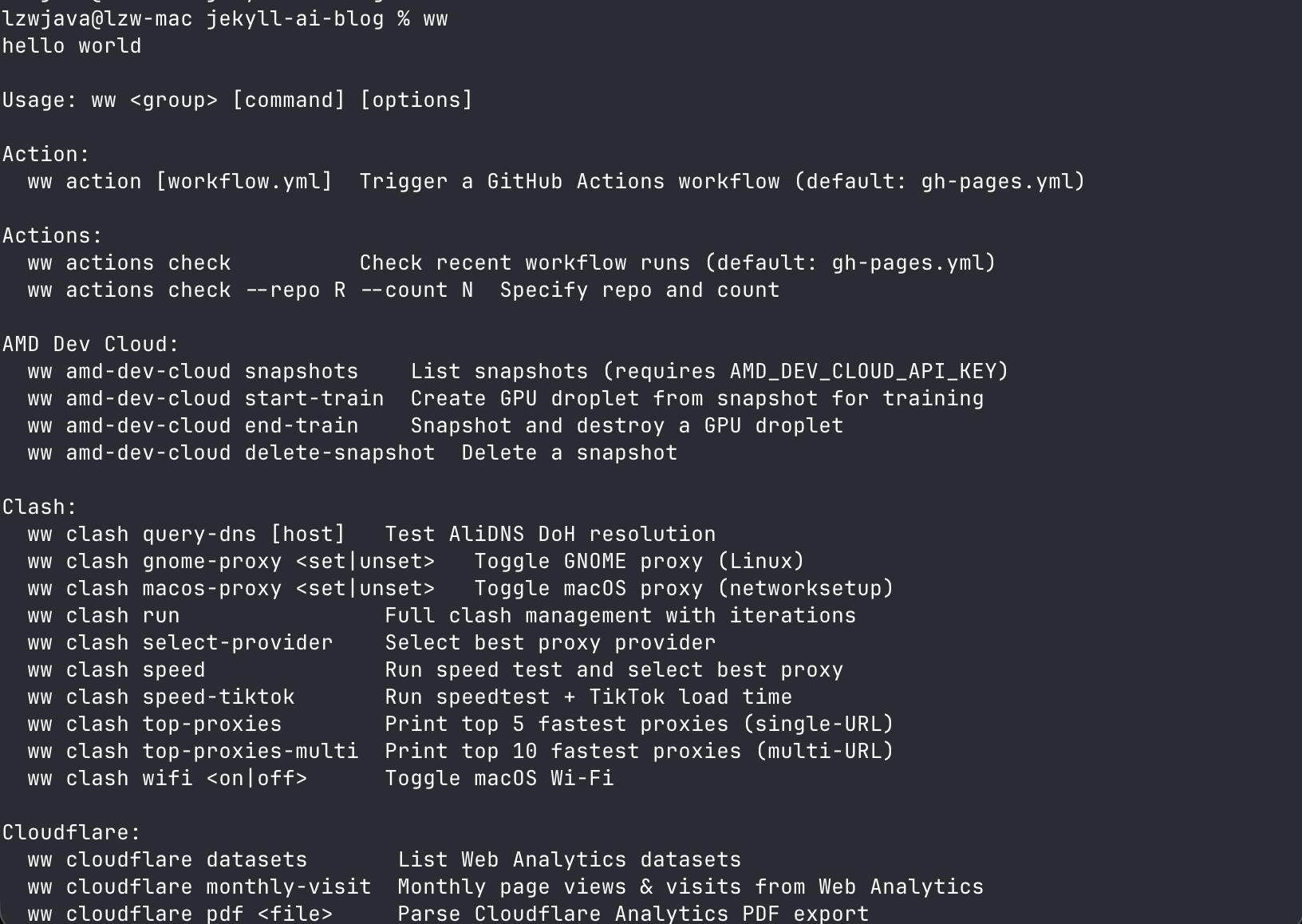
🛠️ ww — Cross-Platform CLI Toolkit
ww is my flagship CLI toolkit — 255+ commits, 10+ command groups, cross-platform (macOS + Linux). It covers git workflows with AI commit messages, note management, image/PDF processing, web search, GitHub Copilot chat, system utilities, and LLM-powered helpers.
lzwjava@lzw-mac ww % uv run ww --help
Usage: ww <group> [command] [options]
Action:
ww action [workflow.yml] Trigger a GitHub Actions workflow
AMD Dev Cloud:
ww amd-dev-cloud snapshots List snapshots
ww amd-dev-cloud start-train Create GPU droplet for training
ww amd-dev-cloud end-train Snapshot and destroy a GPU droplet
Copilot:
ww copilot auth Authenticate via GitHub OAuth
ww copilot chat Chat with a Copilot model
Git:
ww git gpa Git pull --all for all repos
ww git squash <n> Squash last n commits
ww git amend-push Amend last commit and force push
LLM:
ww llm compare <prompt> Compare multiple LLM responses
ww llm query <question> Query local RAG documents
Note:
ww note Clipboard to note (fast capture)
ww note process Drain the note queue
ww note watch Auto-process daemon
Screenshot:
ww screenshot Capture and create a note
ww screenshot interact-note Interactive screenshot note
255+ commits. 10+ command groups. Cross-platform (macOS + Linux).
GitHub: lzwjava/ww
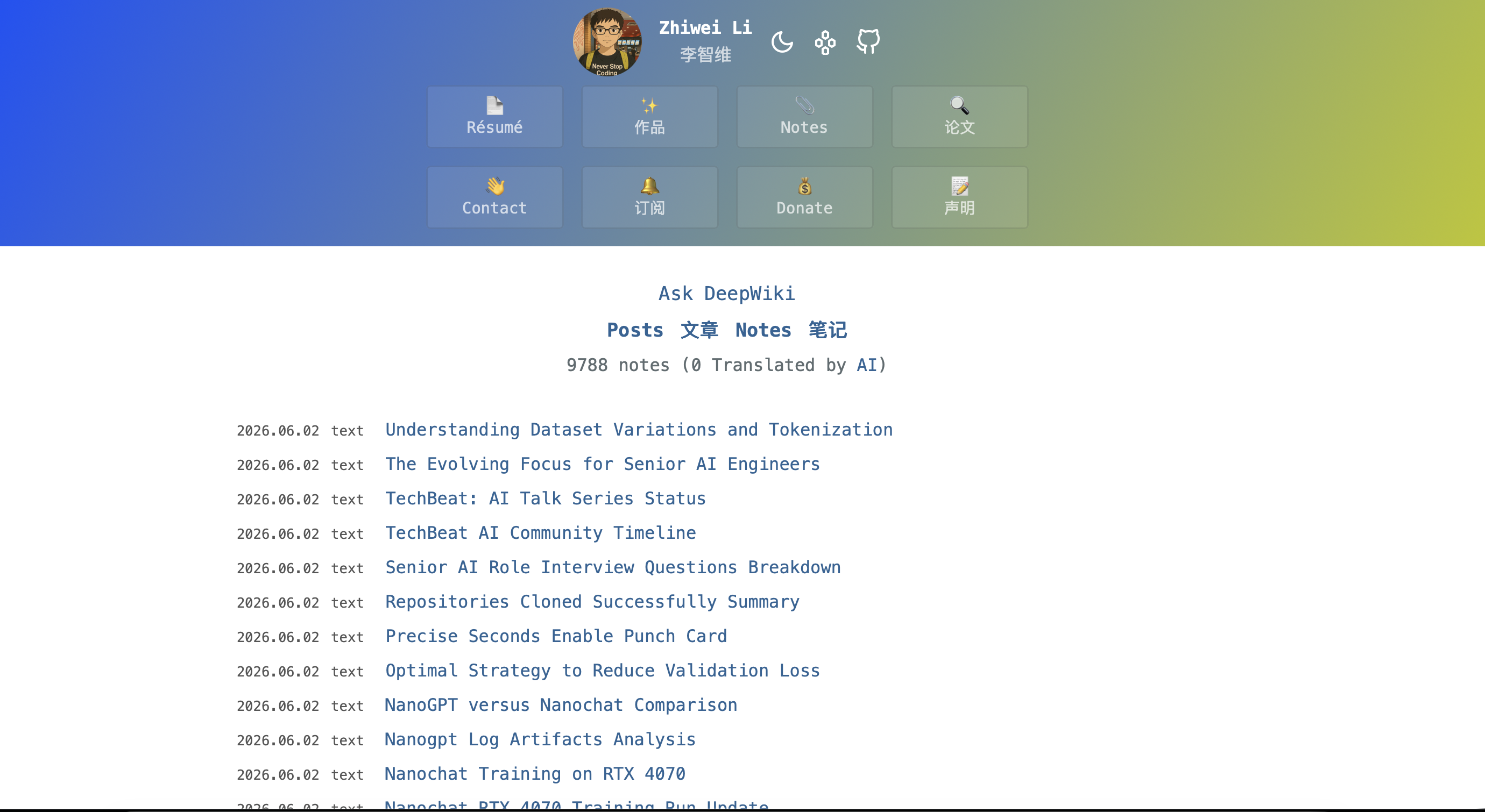
📝 jekyll-ai-blog — AI-Powered Blog Platform
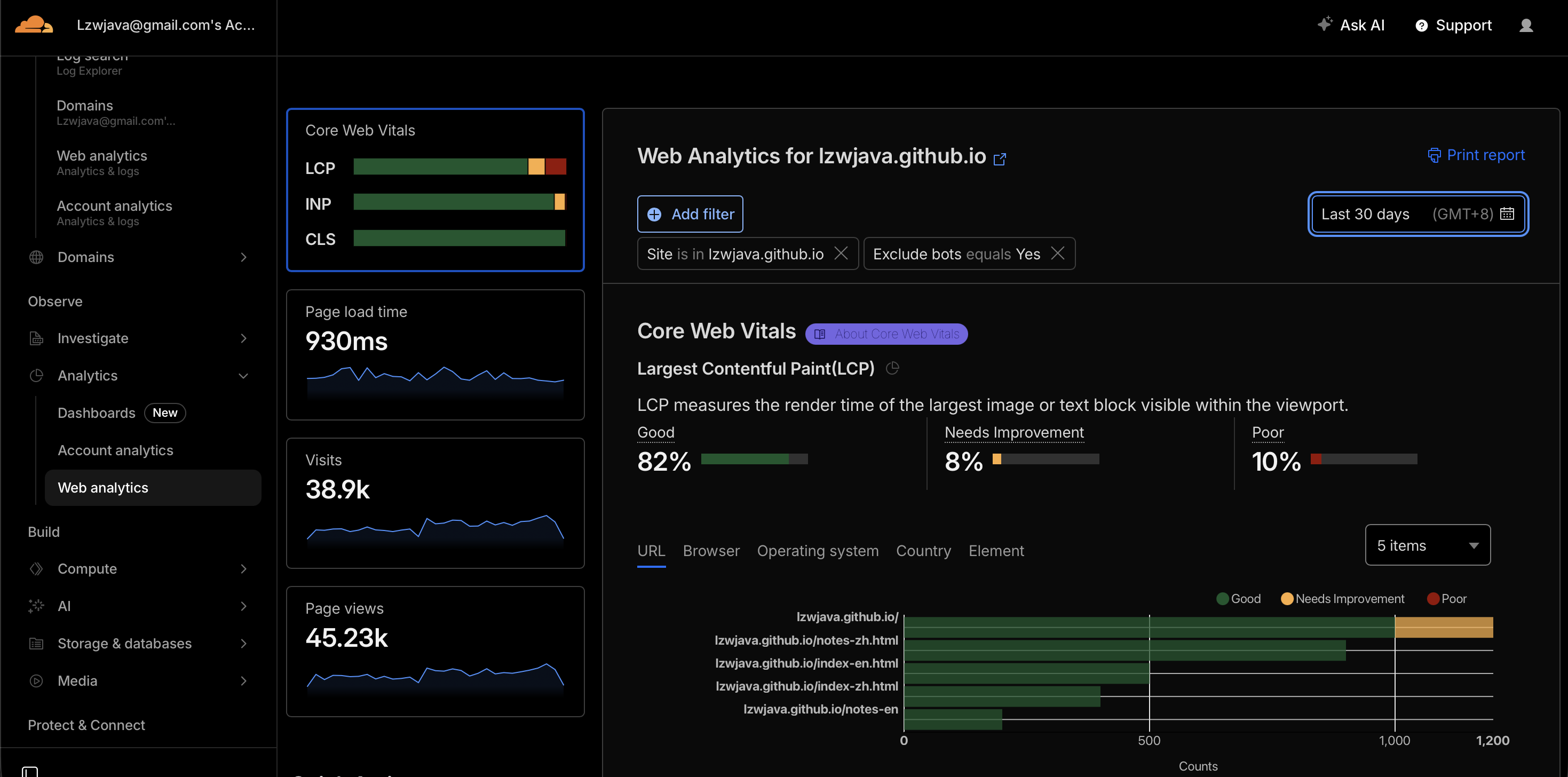
jekyll-ai-blog is the source for lzwjava.github.io — a Jekyll blog enhanced with AI-powered automation. 10,000+ English posts, 10,000+ Chinese posts, 9,700+ AI answer notes. ~70,000 page views in the past month (Cloudflare Analytics).
lzwjava@lzw-mac jekyll-ai-blog % ls README.md
README.md
What makes it different from a standard Jekyll blog:
- AI-Powered Translation — LLM-based translation pipeline expands every post to multiple languages automatically via GitHub Actions.
- Google Cloud Text-to-Speech — Audio versions of posts generated automatically for accessibility.
- XeLaTeX PDF/EPUB Generation — High-quality print-ready PDFs and ebook exports from Markdown source.
- GitHub Actions CI/CD — Automated building, testing, translation, and deployment workflows.
- 8,000+ AI Answer Notes — Knowledge base built from daily LLM-assisted research, searchable on the blog.
- MathJax, Night Mode, RSS, Bilingual Content — Standard features enhanced with custom CSS and theme.
Scale:
| Metric | Count |
|---|---|
| English posts | 10,264 |
| Chinese posts | 10,259 |
| AI answer notes | 9,794 |
| Python scripts | 323 |
| ML scripts | 191 |
| Page views (past month) | ~70,000 |
GitHub: lzwjava/jekyll-ai-blog
🌳 Tree_Of_Thought — Worked with a High School Student on Tree-of-Thought Reasoning
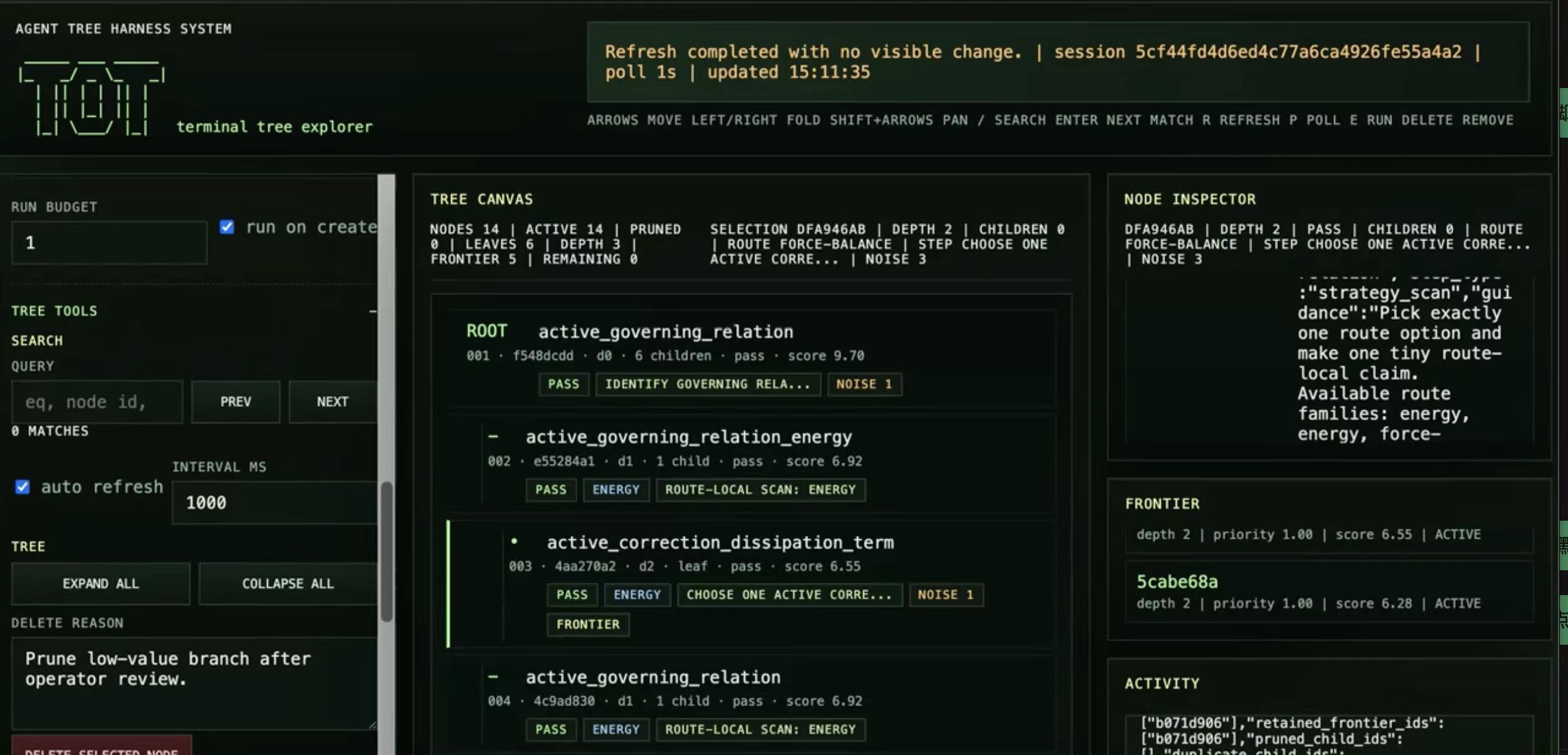
Tree_Of_Thought is a friend’s project — an external Tree-of-Thought reasoning system for physics-heavy problem solving. Instead of relying on a model’s hidden chain-of-thought in one opaque completion, it turns reasoning into an explicit, inspectable, controllable tree with live state, scoring, pruning, and deterministic tool support.
The system combines a FastAPI service for long-lived reasoning sessions, a browser UI for inspecting and pruning branches, a node-level FSM and tree scheduler, a SymPy-backed skill layer for exact symbolic computation, and multi-model routing for planning, modeling, review, and evaluation.
My contribution (1 PR): Added an OpenAI-compatible requester and python-dotenv config so the system can connect to any OpenAI-compatible endpoint (local or cloud).
Context: I mentor a high school student who built this system. During a meeting, he walked me through the full architecture — the reasoning tree, the FSM-based review, the route-local incremental refinement. I introduced him to AI PhD researchers and helped him think about research direction. He’s now exploring physics problem-solving with LLMs, using tools like Codex (GPT-5.4) and building multi-agent collaborative coding systems.
GitHub: Cerynitius/Tree_Of_Thought
🤖 iclaw — Terminal AI Agent (REPL)
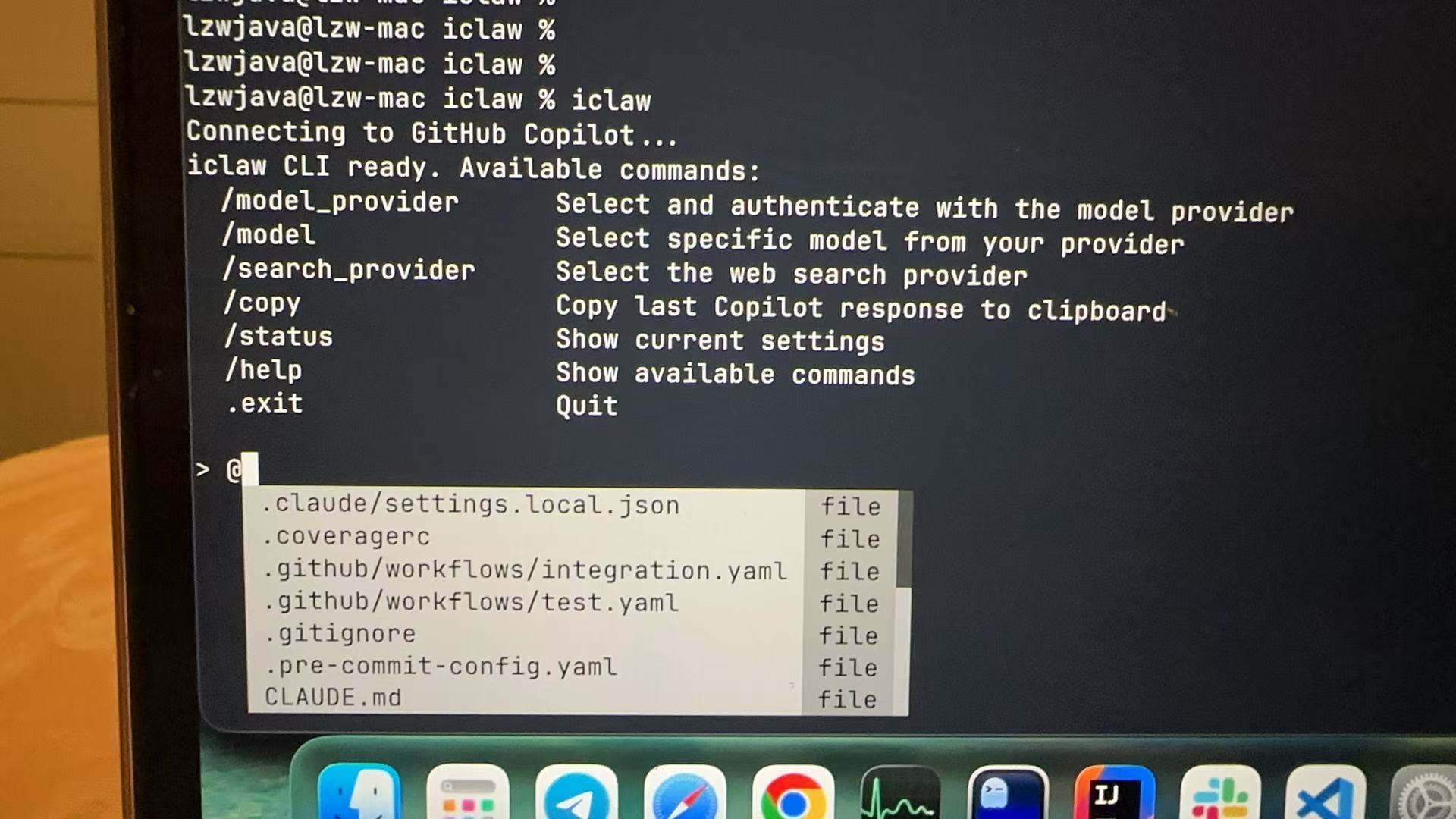
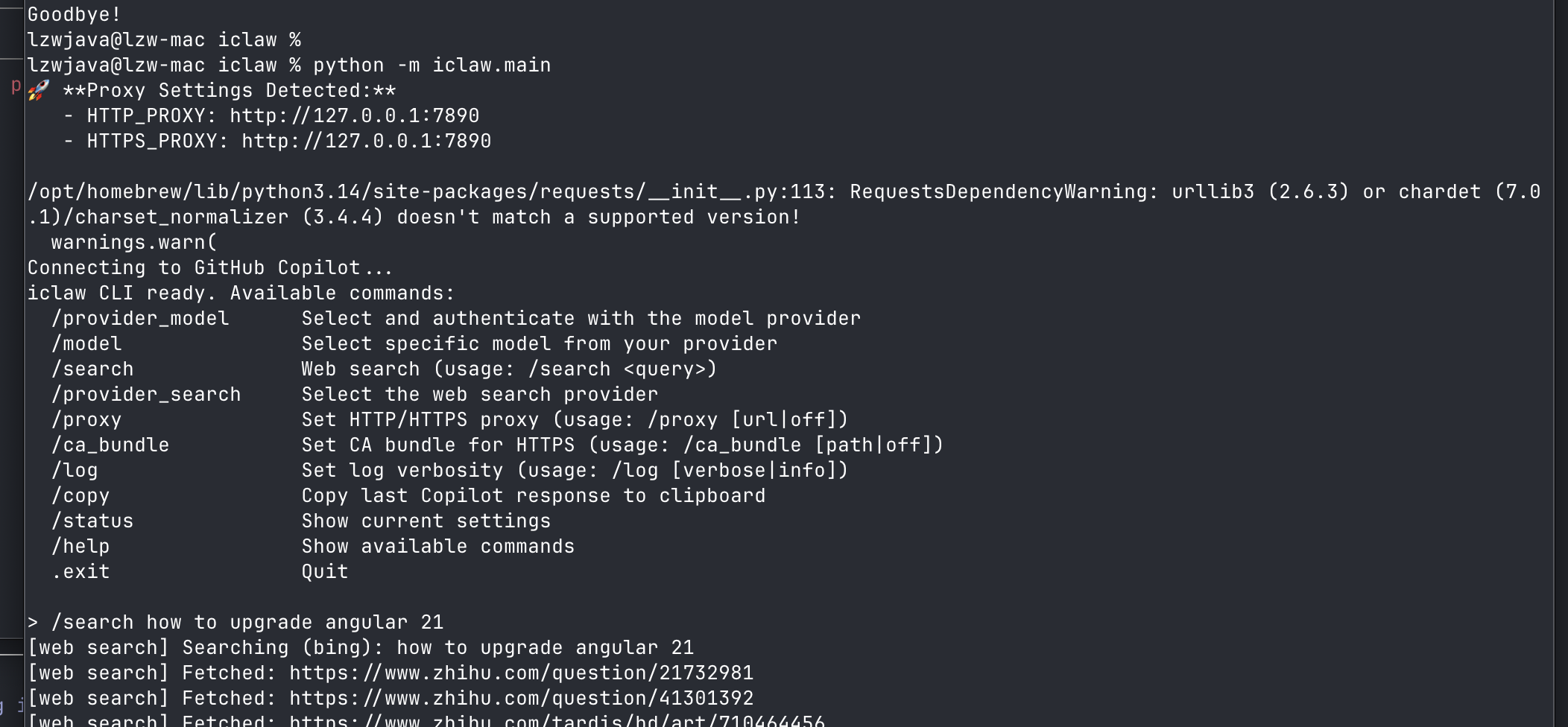
iclaw is a terminal AI agent that codes, searches, and runs commands autonomously — works on personal machines and locked-down enterprise ones. A minimal openclaw implementation, built as a plain Python CLI with no browser extensions or IDE plugins, powered by GitHub Copilot.
lzwjava@lzw-mac iclaw % iclaw
██ █████ ██ █████ ██ ██
██ ██ ██ ██ ██ ██ ██
██ ██ ██ ███████ ██ █ ██
██ ██ ██ ██ ██ ██████
██ █████ ███████ ██ ██ ███ ██
Available commands:
/provider_model Select and authenticate with the model provider
/model Select specific model from your provider
/search Web search (usage: /search <query>)
/provider_search Select the web search provider
/proxy Set HTTP/HTTPS proxy (usage: /proxy [url|off])
/ca_bundle Set CA bundle for HTTPS (usage: /ca_bundle [path|off])
/log Set log verbosity (usage: /log [verbose|info])
/copy Copy last Copilot response to clipboard
/read Print file contents to terminal (usage: /read <path>)
/clear Clear conversation history
/compact Compact conversation history using LLM
/export Export full conversation history to JSON file
/status Show current settings
/help Show available commands
/exit Quit the REPL.
Key features:
- Multi-turn conversations with GitHub Copilot or OpenRouter in your terminal.
- Multiple Model Providers: GitHub Copilot (OAuth device flow) and OpenRouter (API key).
- Native Tool Calling: The model autonomously invokes web search, executes shell commands, and edits files — no human in the loop.
- Multiple Search Providers: DuckDuckGo, Startpage, Bing, and Tavily.
- Enterprise-friendly: No IDE plugins or browser extensions required. Works behind corporate firewalls with proxy and CA bundle support.
- Default model: GPT-5.2.
GitHub: lzwjava/iclaw
⚙️ zz — Dataset Processing & Training Utilities
zz is a toolkit for ML training pipelines — dataset download, tokenization, extraction, and inference utilities. Used during GPT-2 124M training runs on RunPod H200, DigitalOcean H100, and home RTX 4070. Also hosted on Hugging Face.
lzwjava@lzw-mac zz % tree -L 1
scripts/
download/ # Dataset download scripts (FineWeb, Wikimedia, HF mirrors)
extract/ # Data extraction, tokenization, and renaming
analysis/ # Training duration and metric evaluation
deepseek/ # LLM inference scripts (DeepSeek-V2-Lite)
logs/ # Training logs and outputs
datasets/ # Downloaded dataset storage
Key capabilities:
- FineWeb download — Plan and download shards to hit a token budget (10B, 100B+ tokens), resumable with progress tracking.
- hf-mirror.com support — wget scripts for China access when HuggingFace is blocked.
- Parquet extraction — Memory-safe iteration via pyarrow iter_batches.
- Tokenization — Convert raw text to training-ready formats.
- Training analysis — Duration calculation, metric evaluation from training logs.
- DeepSeek inference — LLM inference scripts for DeepSeek-V2-Lite.
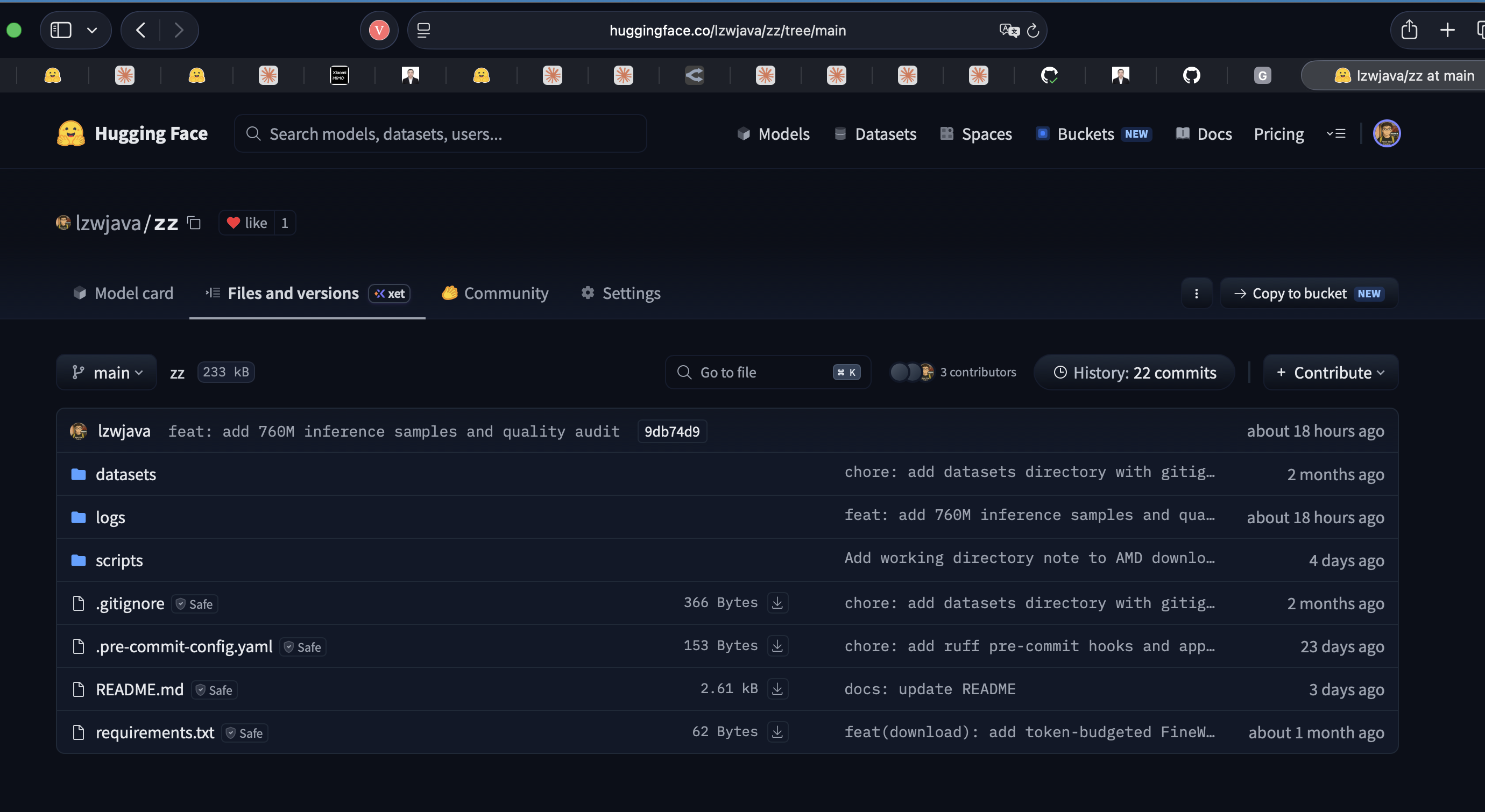
GitHub: lzwjava/zz · Hugging Face: lzwjava/zz
🎓 Certificates
Machine Learning Specialization — DeepLearning.AI & Stanford University
Completed Nov 2023. Three courses: Supervised Machine Learning, Advanced Learning Algorithms, Unsupervised Learning, Recommenders, Reinforcement Learning.

Deep Learning Specialization — DeepLearning.AI
Completed Dec 2023. Five courses: Neural Networks, Hyperparameter Tuning, Structuring ML Projects, CNNs, Sequence Models.

- GitHub: https://github.com/lzwjava
- Blog: https://lzwjava.github.io