我的AI作品集——日常AI工作的证据 | 原创,AI翻译
我不只是谈论AI——我每天都在大规模使用它。这篇文章是我AI工作的视觉作品集:我构建的工具、消耗的token以及获得的认证。
🖥️ LLM训练与推理——我的硬件配置
2023年搭建了我的机器学习工作站,并从此开始训练和学习。
硬件经验:
| GPU | 显存 | 经验时长 | 使用平台 |
|---|---|---|---|
| NVIDIA RTX 4070 | 12 GB | 3年 | 家庭工作站 |
| NVIDIA H200 | 141 GB | 3个月 | RunPod / DigitalOcean |
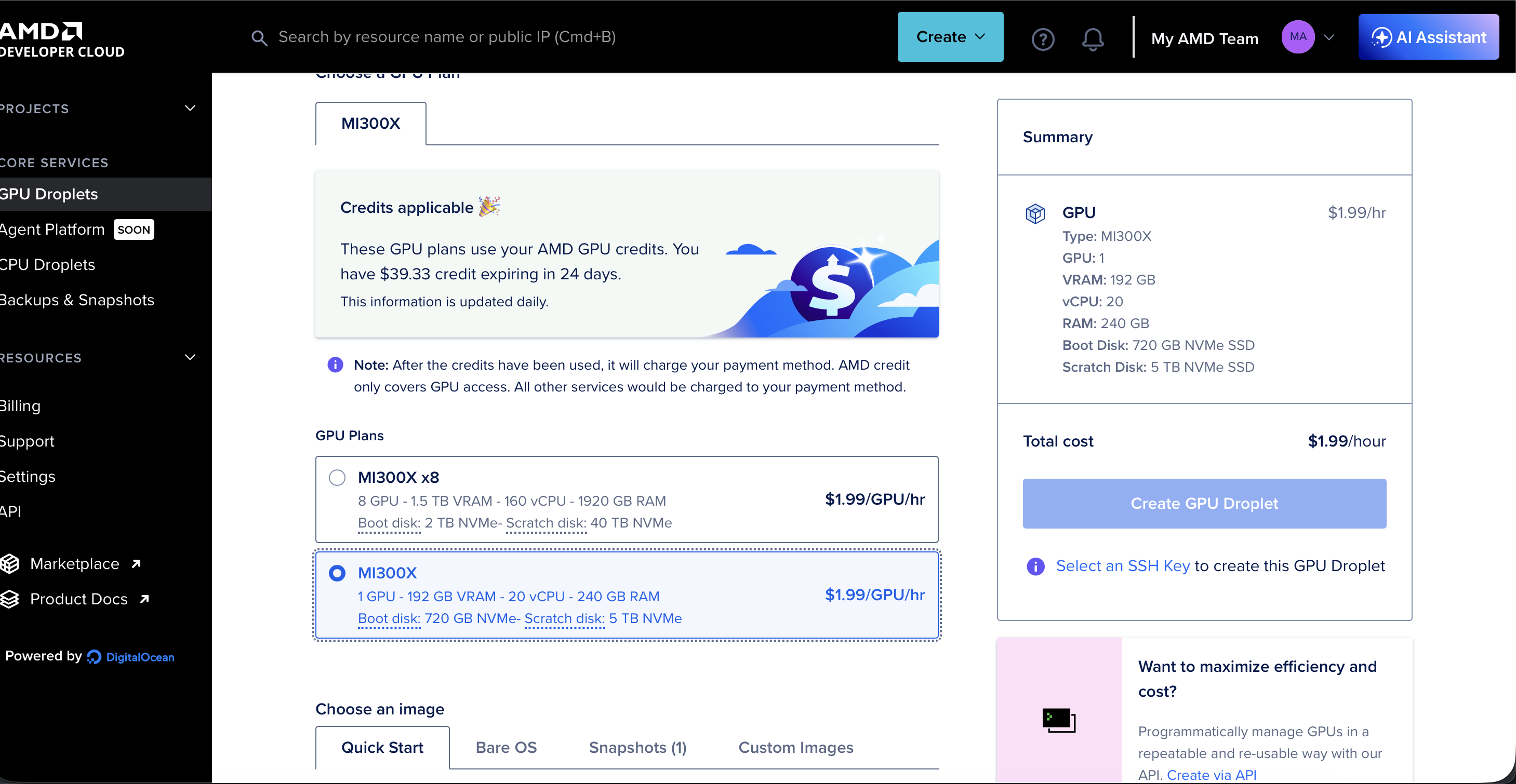
| AMD MI300X | 192 GB HBM3 | 3个月 | AMD Developer Cloud |
我训练过的内容:
- GPT-2 124M 从零开始在FineWeb数据集上训练(nanoGPT)—— 在RTX 4070、H200和MI300X上。
- GPT-2 760M 从零开始在AMD MI300X(192 GB HBM3)上训练——探索nanochat、DeepSeek v4 MoE。
- 各种超参数调整、学习率调度和数据集预处理的实验。
工作站:

AMD Developer Cloud —— MI300X 192GB HBM3:
🏋️ 训练运行总结
| # | 模型 | 框架 | 参数量 | 硬件 | 步数 | 状态 |
|---|---|---|---|---|---|---|
| 1 | FineWeb 125M run1 | nanoGPT | 124M | RTX 4070 | 20K | 完成 |
| 2 | FineWeb 125M run2 | nanoGPT | 124M | RTX 4070 | 6K | 完成 |
| 3 | FineWeb 125M run3 | nanoGPT | 124M | RTX 4070 | 11K | 完成 |
| 4 | OpenWebText 125M | nanoGPT | 124M | RTX 4070 | 6K | 完成 |
| 5 | FineWeb 125M MI300X | nanoGPT | 124M | MI300X | 750 | 冒烟测试 |
| 6 | FineWeb 760M | nanoGPT | 760M | MI300X | 76K/445K | 提前停止 |
| 7 | fineweb-edu-d12 | nanochat | 286M | RTX 4070 | 10K | 基础预训练完成 |
| 8 | rtx4070-d12-chinchilla | nanochat | 286M | RTX 4070 | 87K | 完全完成 |
| 9 | code-sec-fineweb-d12 | nanochat | 286M | H200? | 50K | 完成 |
| 10 | code-sec-sft | nanochat | ~140M | H200? | 8,985 | 完成 |
| 11 | codeparrot-d12 | nanochat | 286M | RTX 4070 | ? | 仅脚本 |
| 12 | Notes SFT (Qwen3-4B) | trl/peft | 4B | RTX 4070 | ? | 仅脚本 |
| 13 | SPGISpeech (Whisper) | transformers | varies | ? | ? | 仅脚本 |
🧠 增强版nanoGPT —— 我的分支
Fork了karpathy/nanoGPT并扩展了额外的数据集流水线、大规模训练配置以及用于学习的内联形状注释。45个提交,2025年11月 – 2026年4月。
新增数据集流水线:
| 数据集 | 路径 | 描述 |
|---|---|---|
| FineWeb-Edu | data/fineweb/ |
HuggingFace FineWeb-Edu(10B+ tokens)。基于分片的加载、分块处理、增量训练/验证集划分。 |
| OpenWebText 10k | data/openwebtext_10k/ |
快速10k子集用于快速迭代。 |
| Wikipedia Local | data/wikipedia_local/ |
直接对本地纯文本dump进行token化(无需HuggingFace下载)。 |
新增训练配置:
| 配置 | 目标 | 备注 |
|---|---|---|
train_fineweb.py |
FineWeb上125M | 针对RTX 4070 12 GB调优(n_embd=384, dropout=0.1)。 |
train_fineweb1_5b.py |
FineWeb上1.5B | 适用于H200 80 GB。 |
train_fineweb_gpt3.py |
GPT-3风格10B tokens | 基于分片的加载器,更宽的调度。 |
train_fineweb_760m.py |
FineWeb上760M | 适用于MI300X 192 GB HBM3。 |
train_gpt2_200m.py |
GPT-2 200M | 通用中型配置。 |
train_gpt2_200m_smoke.py |
冒烟测试 | 快速200M sanity检查(约几分钟)。 |
模型改动:
- 内联张量形状注释 遍布
model.py的前向传播(CausalSelfAttention, MLP, GPT)—— 每一步都显示精确形状,并附有具体的GPT-2 XL示例,例如# x: (B, T, C) e.g. (1, 5, 1600)。有助于理解transformer数据流。
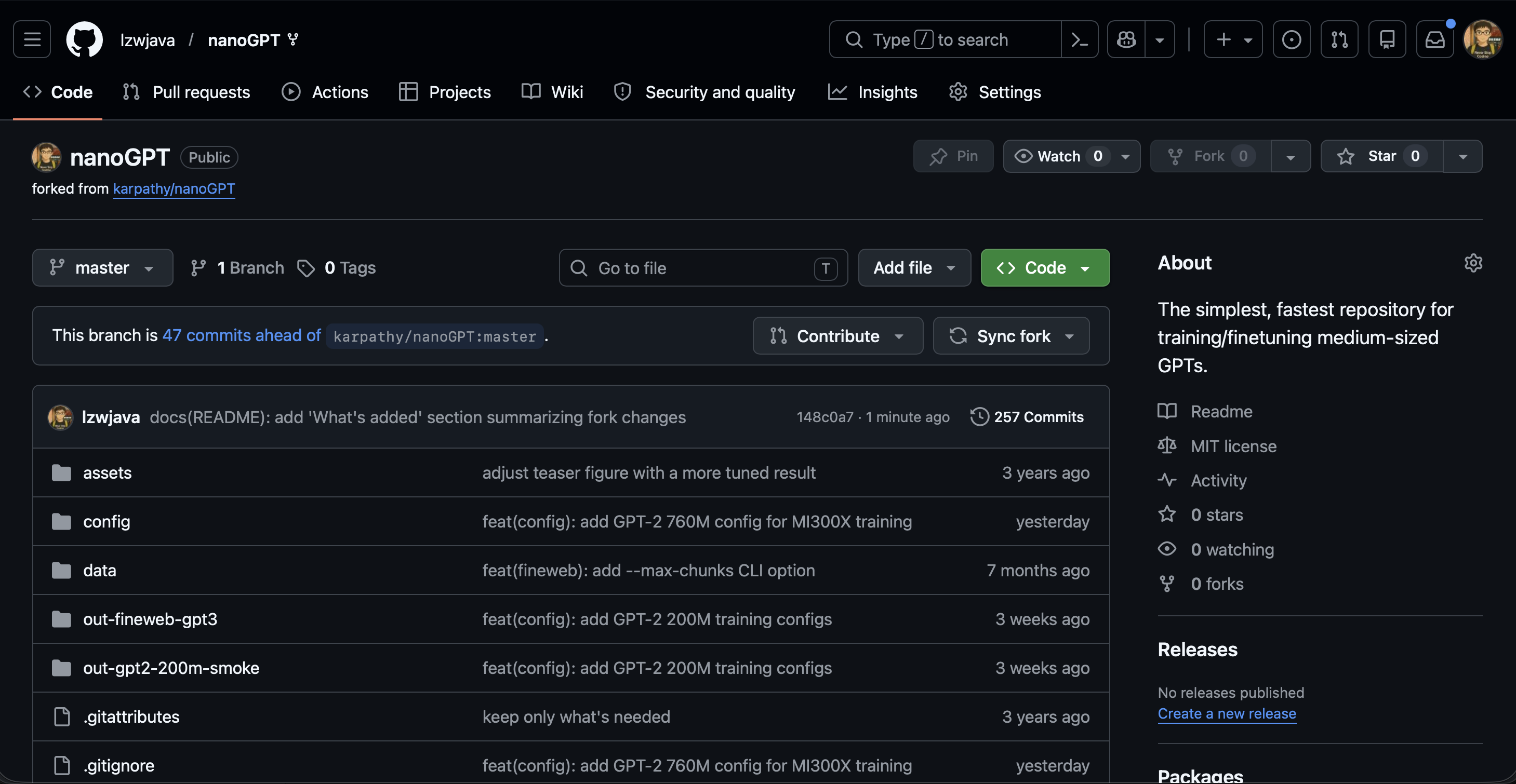
GitHub: lzwjava/nanoGPT
📝 SEC-EDGAR-GPT —— 从零在SEC文件上训练的GPT-2(124M)
在1.55B tokens的SEC EDGAR财务文件(10-K、10-Q及其他公司披露)上从零训练了一个124M参数的GPT-2 —— 在单个RTX 4070(12 GB显存)上训练约8小时,验证损失收敛至2.28。
该模型能生成令人信服的SEC标准文本——风险因素、MD&A章节、业务描述——并通过RunPod上的FastAPI服务器部署为交互式聊天。
整个项目——模型训练、论文、聊天机器人和网站——在3天内使用Hermes Agent构建,展示了AI代理如何让LLM研究变得触手可及。
在一个全球银行内部分享后,项目获得了200+次内部浏览。一位首席工程师留下评论称其为”nice”。此外,受一位朋友关于递归transformer工作的启发,这个项目让我开始思考如何将金融token与自然语言token区别对待,以提高生成准确性。
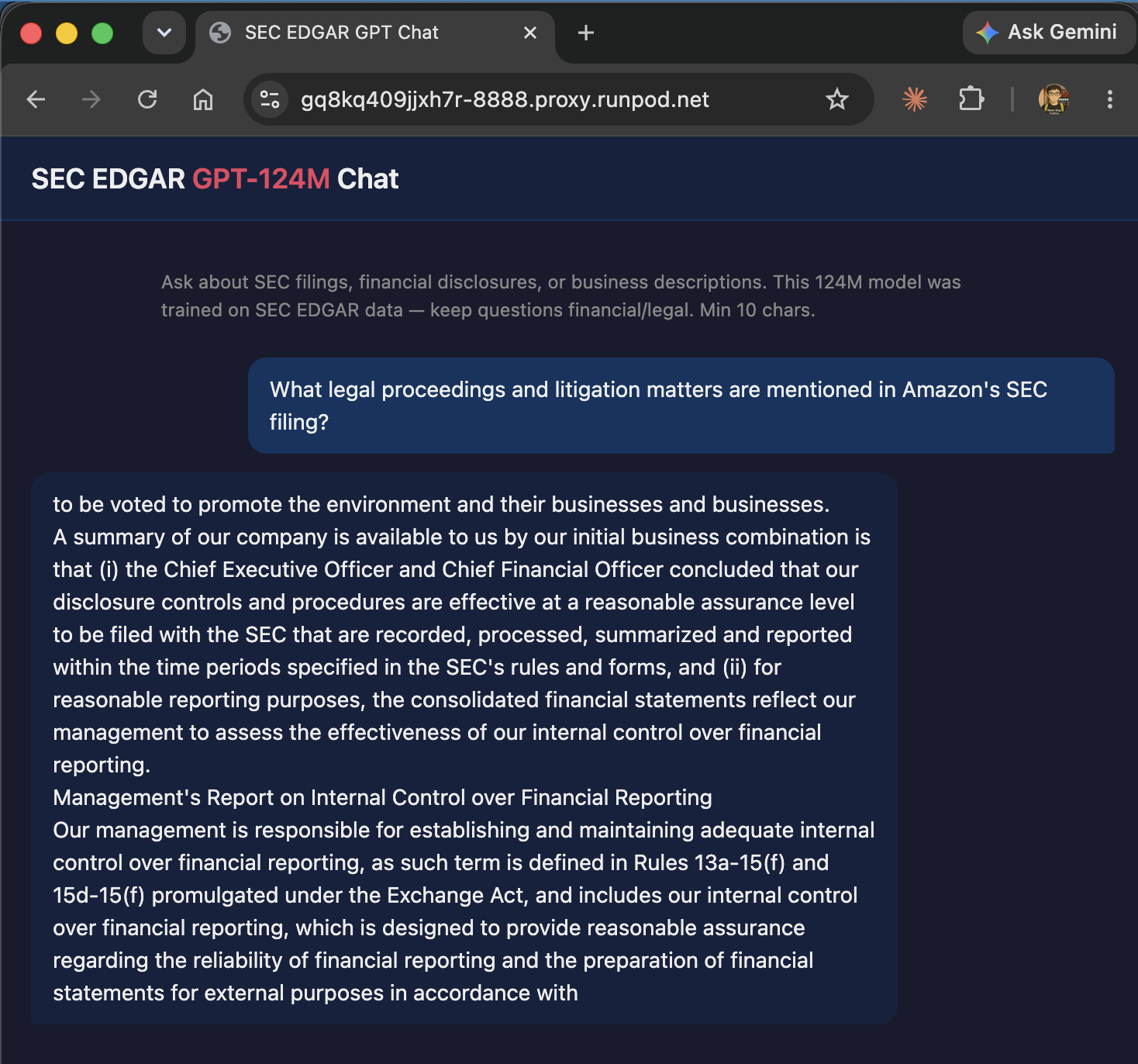
代码: github.com/lzwjava/sec-edgar-gpt · 论文: sec-edgar-gpt.pdf · 模型: Hugging Face · 聊天: sec-edgar-gpt.lzwjava.workers.dev
📊 LLM API使用量 —— 数据
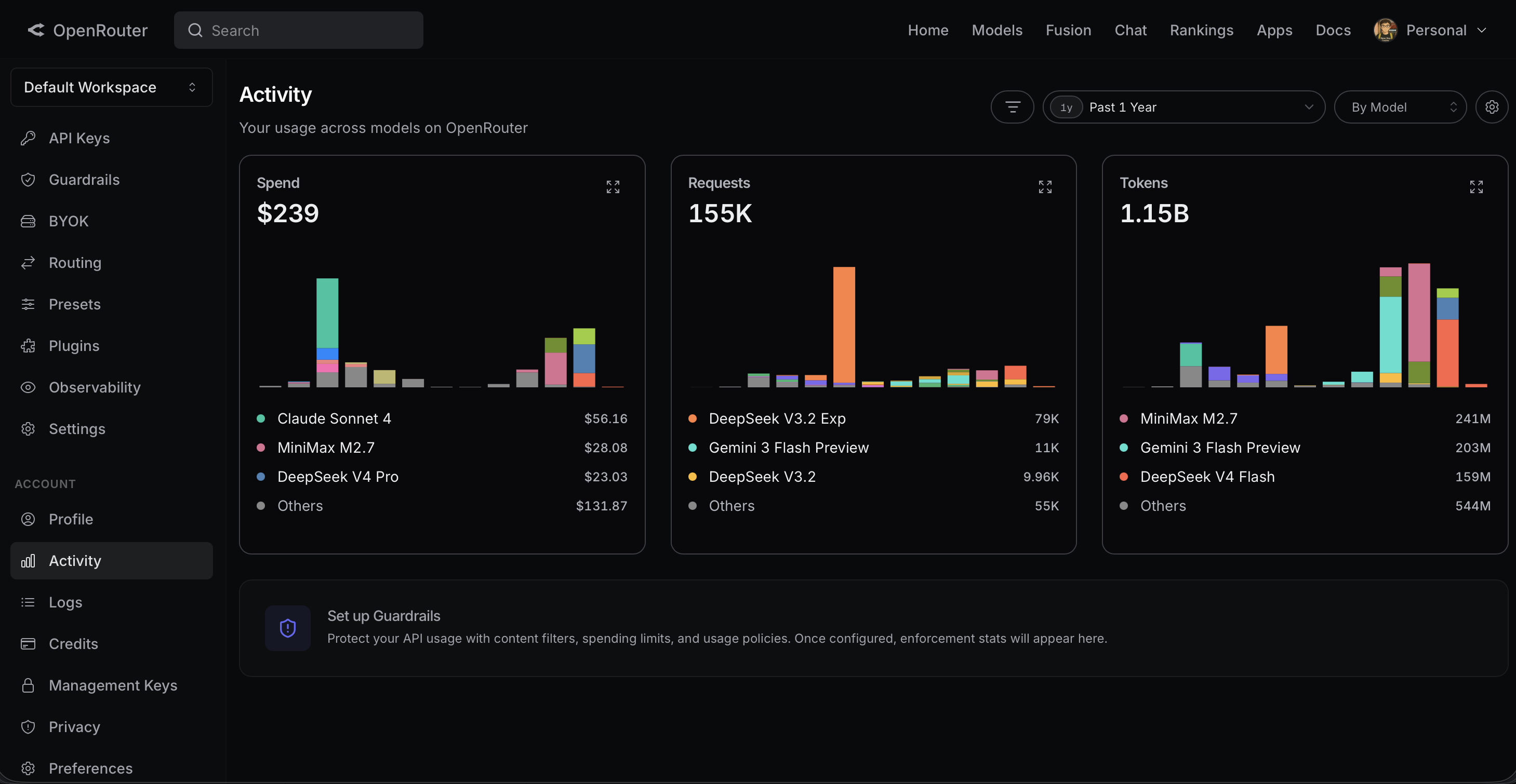
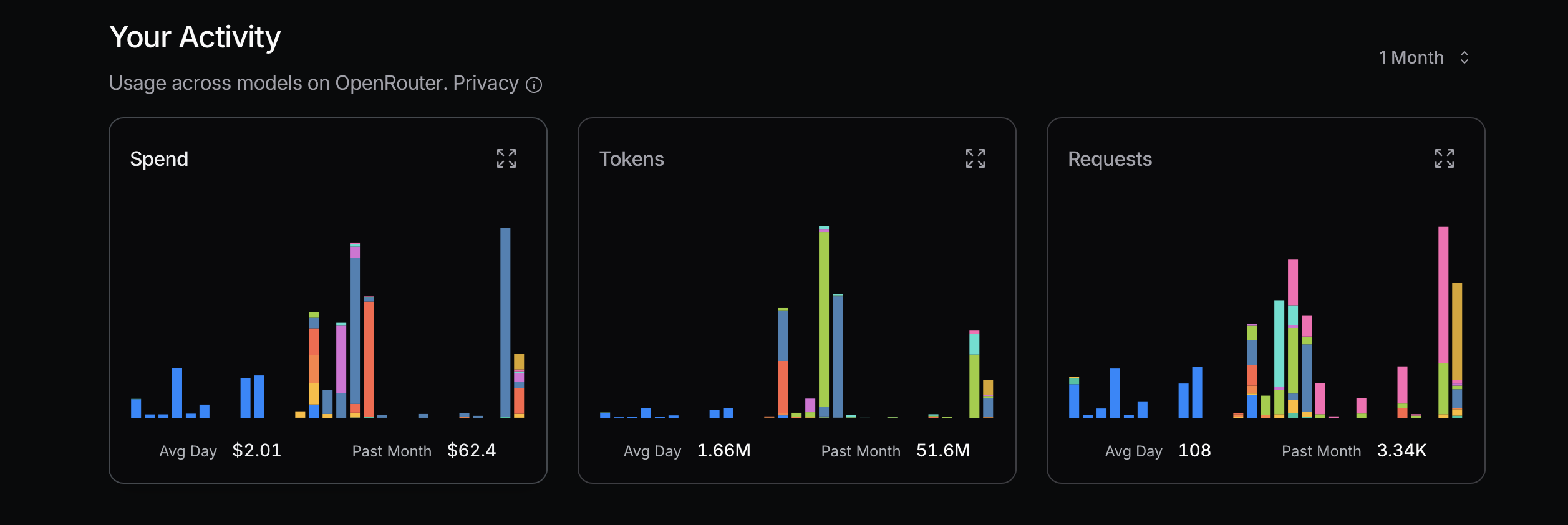
OpenRouter —— 过去一年
消耗了1.15B tokens,花费$239,155K次API请求,涵盖多个模型。
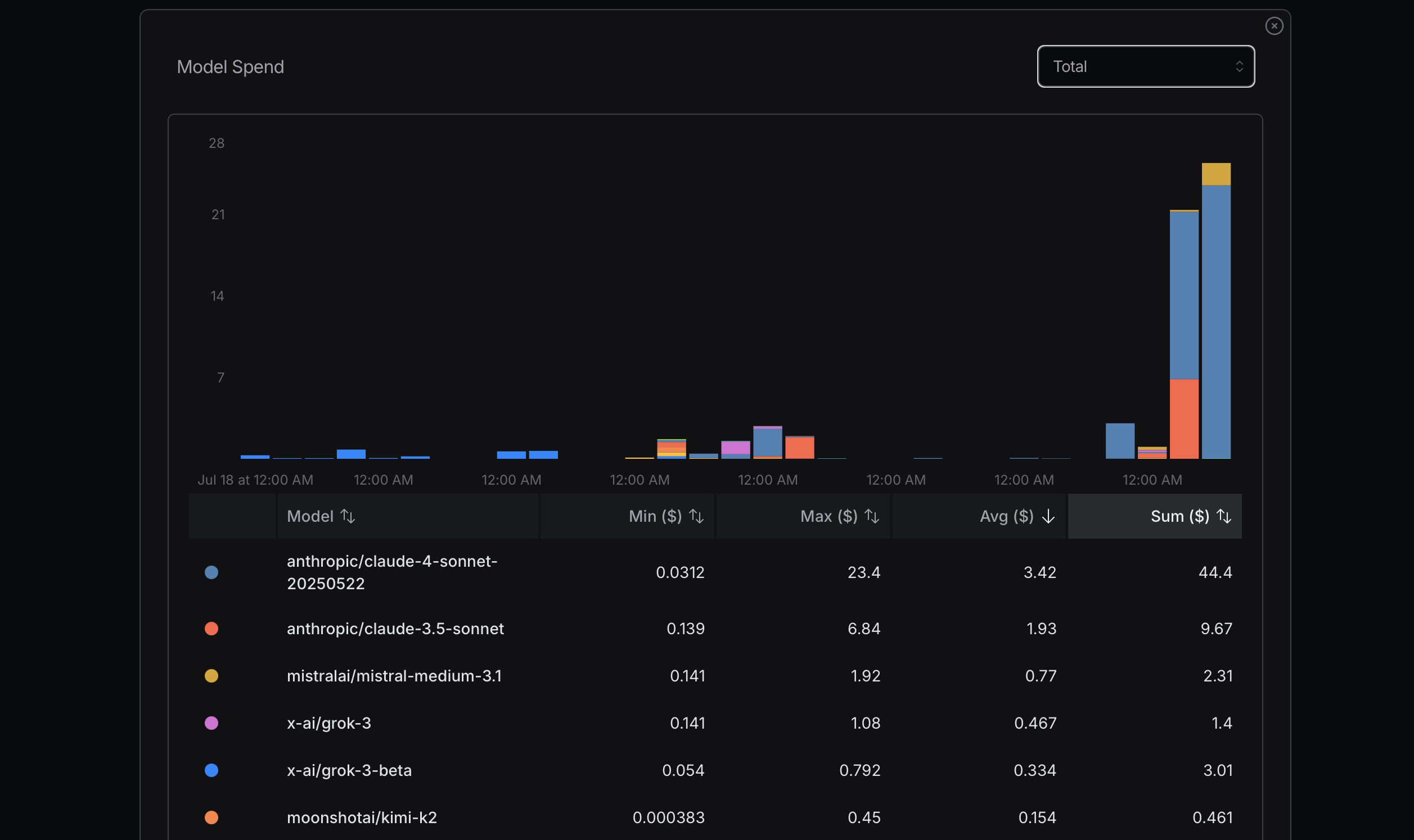
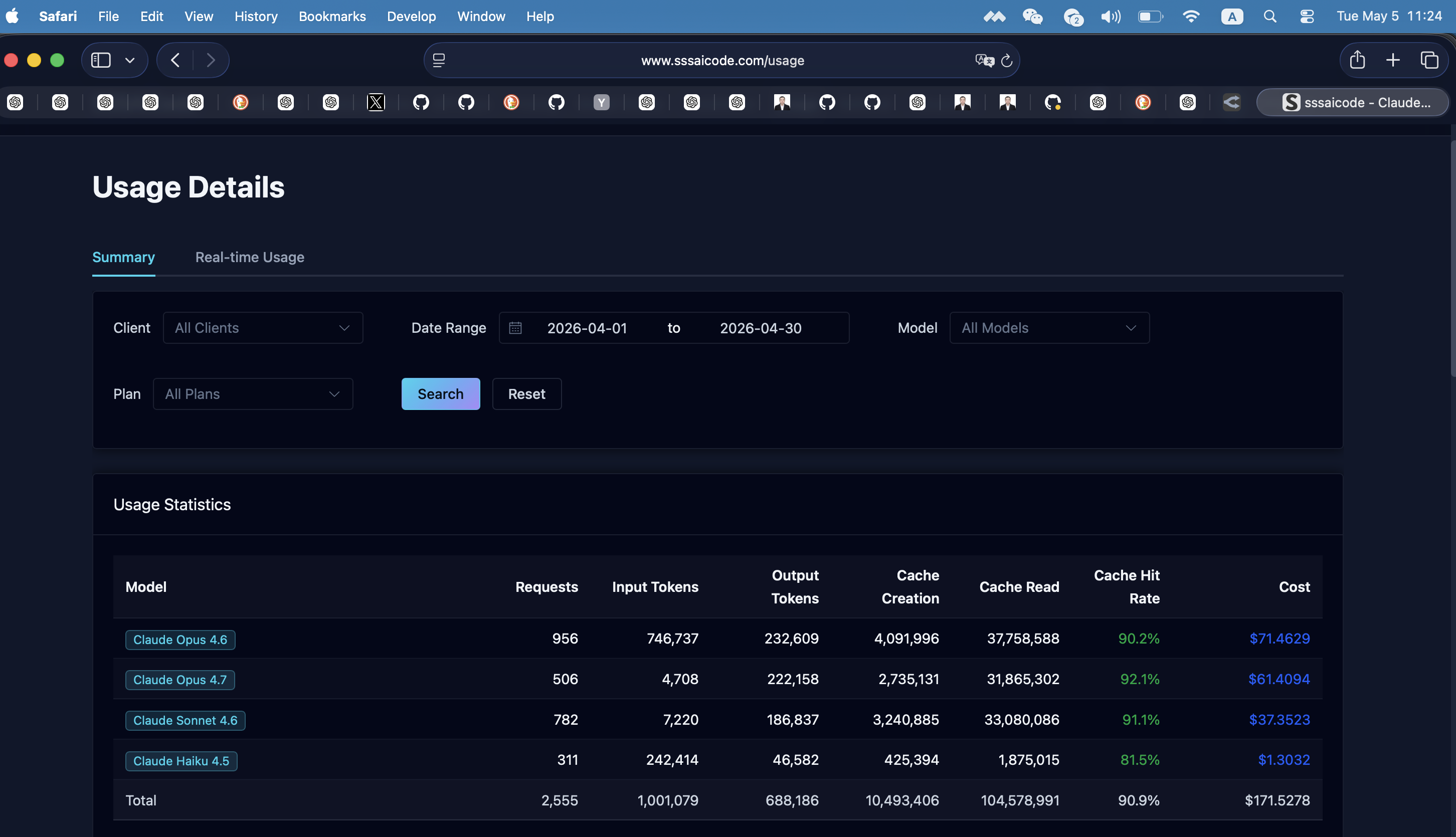
通过SSSAICode使用Claude API —— 2026年4月
一个月内花费$171.53。2,555次请求。1.15亿+ tokens。90.9%缓存命中率。
小米MIMO订阅 —— 使用12.5亿Tokens
Pro月度套餐,38B主配额 + 8.75B补偿配额(约4.6B免费额度)。2026年5月至6月期间消耗12.5亿tokens。
月度Token使用明细
| 月份 | 模型 | 总Tokens | 输入(缓存命中) | 输入(缓存未命中) | 输出 | 请求数 |
|---|---|---|---|---|---|---|
| 2026-06 | mimo-v2.5 | 285,179 | 36,416 | 143,556 | 105,207 | 78 |
| 2026-06 | mimo-v2.5-pro | 734,873,374 | 710,036,672 | 21,617,131 | 3,219,571 | 10,704 |
| 2026-05 | mimo-v2.5 | 91,203 | 5,312 | 52,908 | 32,983 | 27 |
| 2026-05 | mimo-v2.5-pro | 508,851,211 | 488,291,136 | 17,725,731 | 2,834,344 | 8,649 |
| 2026-05 | mimo-v2-pro | 3,571,328 | 3,021,568 | 539,357 | 10,403 | 167 |
月度总计: 2026年5月:5.125亿tokens(8,843次请求)· 2026年6月:7.352亿tokens(10,782次请求)
mimo-v2.5-pro占主导(约总使用量的96%)。mimo-v2.5-pro缓存命中率约96.7%,保持成本高效。6月token量较5月增长43.5%。
总结
| 平台 | Tokens | 时间段 | 费用 |
|---|---|---|---|
| OpenRouter | 1.15B | 过去一年 | $239 |
| SSSAICode (Claude) | 1.15亿+ | 2026年4月 | $171.53 |
| 小米MIMO | 1.25B | 2026年5-6月 | 免费4.6B额度 |
| 其他(GitHub Copilot等) | 5亿 | 过去一年 | — |
| 总计 | 约30亿+ | 过去一年 | — |
🏢 企业AI使用 —— 在一家英国环球银行
在一家英国环球银行(通过一家全球IT外包公司),我在GitHub Copilot之上构建了一个自主AI代理层,用于自动化脚本编写、日志记录、文档编写和测试。
我构建的内容:
- 20个定制化AI代理 —— 针对不同技术栈和工作流程的专用提示词和上下文。
- 400个由Copilot编写的可复用脚本 —— 自动化常见任务,涵盖Java、Spring、Python、Angular和DevOps工具。
- 1,100份由Copilot编写的指南 —— 通过LLM输出生成并验证的文档,带有缓存和验证机制。
- 约70个自动生成的测试用例 —— 通过Copilot API生成,涵盖Spring Filters、Python unittest、JSON截断、提示词工程和区域端点。
成果:
- 在整个企业范围内,按高级请求量排名,Copilot使用量位列前6%。
- 因高知名度项目AIPlayer获得贡献奖。
- 加入银行内部AI社区。

🎤 AI讲座 —— 从神经网络到智能体
在一家英国环球银行向80位参与者进行了技术演讲——包括高级顾问、专家、副总监、软件工程师和合同工。
讲座: “从神经网络到智能体” —— 从最简单的神经网络(y = wx)出发,经过MNIST、Transformer、GPT、nanoGPT,到构建个人AI代理的旅程。
我涵盖的内容:
- 神经网络基本原理 —— 前向传播、反向传播、梯度下降
- Transformer架构 —— Q/K/V注意力、多头注意力、位置编码
- GPT内部机制 —— 分词、嵌入、训练、生成
- nanoGPT —— 在H200/RTX 4070上从零训练GPT-2
- LLM智能体 —— Claude Code、OpenClaw、Hermes、工具调用、智能体循环
- 真实数据 —— 10亿tokens消耗,H200每小时$3.44,钱到底花在哪里
- 我的路径 —— 从阅读Q/K/V到从零训练模型,历时3年
反馈:
- 一位初级工程师说:“你就是我想成为的人” —— 这次演讲让他看到了AI的可能性
- 高级工程师赞赏从第一性原理出发的方法 —— 没有炒作,只有数学和代码
- 后续多次关于训练、智能体和职业方向的讨论
幻灯片: 使用Claude Code & Marp构建,基于我的公开AI回复笔记。
幻灯片 (Marp):PDF
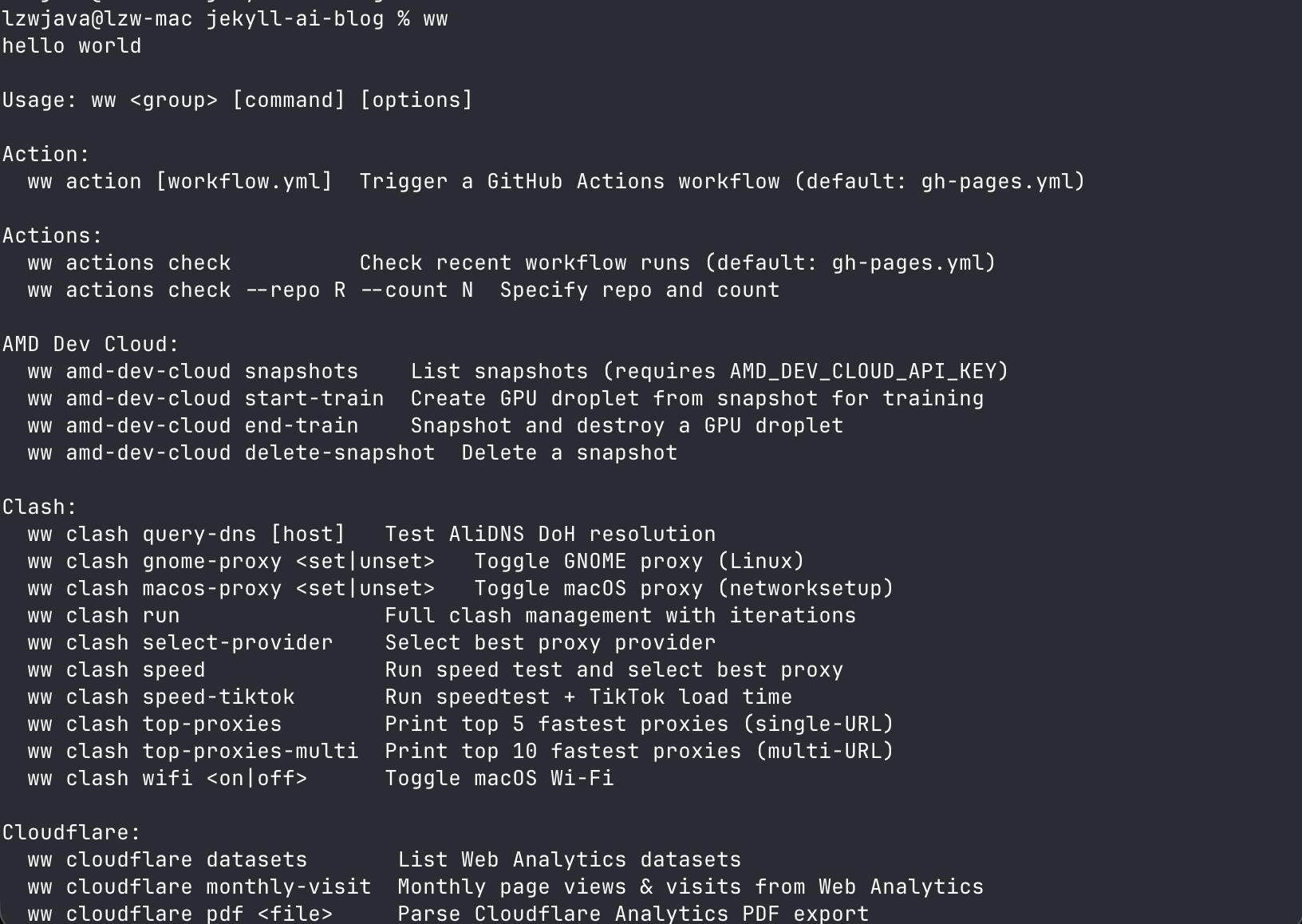
🛠️ ww —— 跨平台CLI工具包
ww 是我的旗舰CLI工具包 —— 255+次提交,10+个命令组,跨平台(macOS + Linux)。涵盖带有AI提交消息的git工作流、笔记管理、图像/PDF处理、网页搜索、GitHub Copilot聊天、系统工具和LLM辅助功能。
lzwjava@lzw-mac ww % uv run ww --help
Usage: ww <group> [command] [options]
Action:
ww action [workflow.yml] 触发一个 GitHub Actions 工作流
AMD Dev Cloud:
ww amd-dev-cloud snapshots 列出快照
ww amd-dev-cloud start-train 创建 GPU 实例用于训练
ww amd-dev-cloud end-train 对 GPU 实例进行快照并销毁
Copilot:
ww copilot auth 通过 GitHub OAuth 进行认证
ww copilot chat 与 Copilot 模型对话
Git:
ww git gpa 对所有仓库执行 git pull --all
ww git squash <n> 压缩最近 n 个提交
ww git amend-push 修改最近提交并强制推送
LLM:
ww llm compare <prompt> 比较多个 LLM 的响应
ww llm query <question> 查询本地 RAG 文档
Note:
ww note 剪贴板内容到笔记(快速捕获)
ww note process 清空笔记队列
ww note watch 自动处理守护进程
Screenshot:
ww screenshot 捕获截图并创建笔记
ww screenshot interact-note 交互式截图笔记
255+ 次提交。10+ 个命令组。跨平台(macOS + Linux)。
GitHub: lzwjava/ww
📝 jekyll-ai-blog —— AI驱动的博客平台
jekyll-ai-blog 是 lzwjava.github.io 的源代码 —— 一个通过AI自动化增强的Jekyll博客。10,000+篇英文文章,10,000+篇中文文章,9,700+条AI回答笔记。过去一个月约70,000次页面浏览量(Cloudflare Analytics)。
lzwjava@lzw-mac jekyll-ai-blog % ls README.md
README.md
它与标准Jekyll博客的不同之处:
- AI驱动的翻译 —— 基于LLM的翻译流水线,通过GitHub Actions自动将每篇文章扩展到多种语言。
- Google Cloud Text-to-Speech —— 自动生成文章音频版本,提升可访问性。
- XeLaTeX PDF/EPUB生成 —— 从Markdown源生成高质量的可打印PDF和电子书导出。
- GitHub Actions CI/CD —— 自动化构建、测试、翻译和部署工作流。
- 8,000+条AI回答笔记 —— 基于日常LLM辅助研究构建的知识库,可在博客上搜索。
- MathJax、夜间模式、RSS、双语内容 —— 标准功能通过自定义CSS和主题增强。
规模:
| 指标 | 数量 |
|---|---|
| 英文文章 | 10,264 |
| 中文文章 | 10,259 |
| AI回答笔记 | 9,794 |
| Python脚本 | 323 |
| 机器学习脚本 | 191 |
| 页面浏览量(过去一个月) | ~70,000 |
GitHub: lzwjava/jekyll-ai-blog
🌳 Tree_Of_Thought —— 与一名高中生合作研究思维树推理
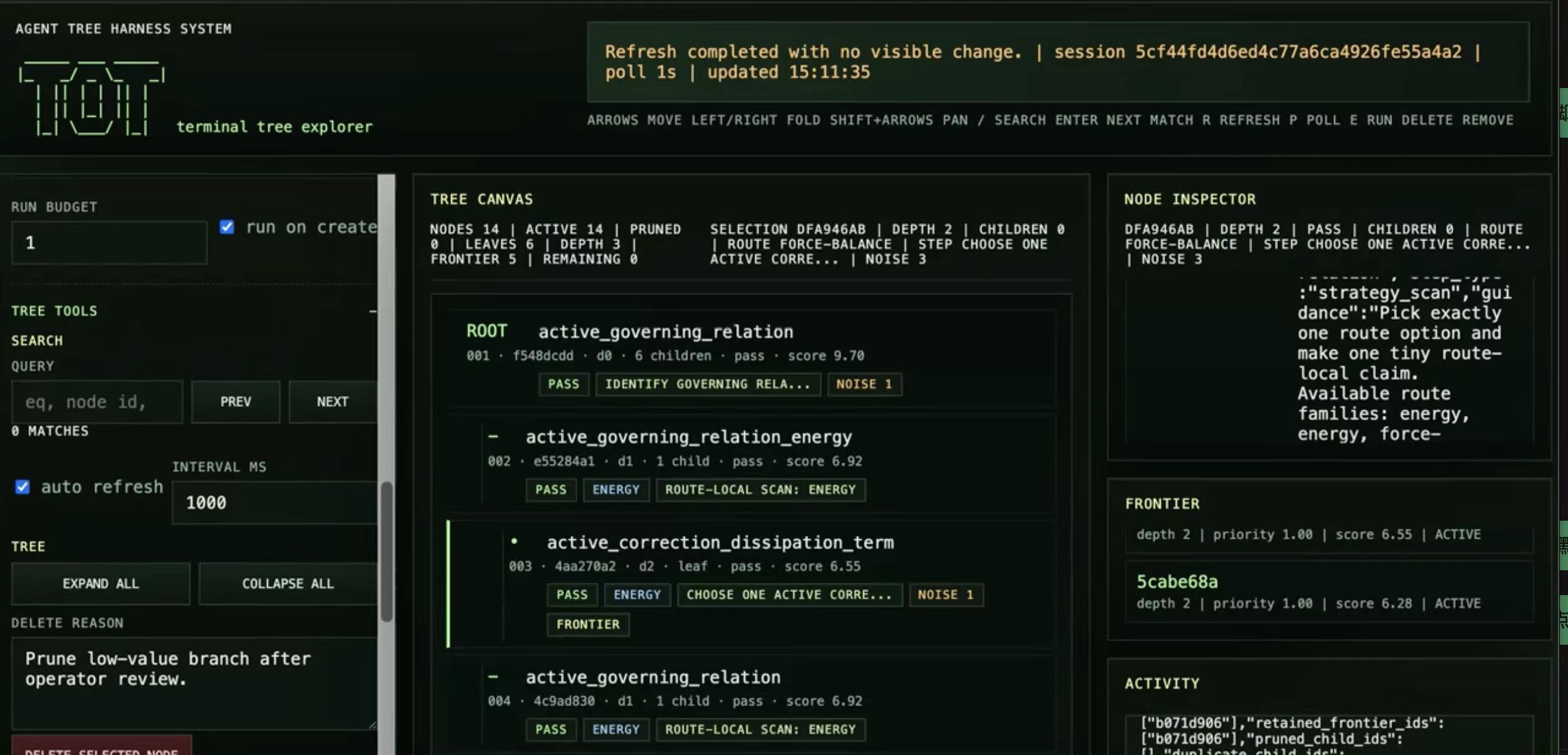
Tree_Of_Thought 是一个朋友的项目 —— 一个用于物理密集型问题求解的外部思维树推理系统。它不依赖模型在一个不透明的完成中隐藏的思维链,而是将推理转化为显式、可检查、可控制的树,具有实时状态、评分、剪枝和确定性工具支持。
该系统结合了用于长时间推理会话的FastAPI服务、用于检查和剪枝分支的浏览器UI、节点级FSM和树调度器、用于精确符号计算的SymPy支持技能层,以及用于规划、建模、审查和评估的多模型路由。
我的贡献(1个PR): 添加了一个兼容OpenAI的请求器和python-dotenv配置,使系统能够连接到任何兼容OpenAI的端点(本地或云端)。
背景: 我指导一名高中生,他构建了这个系统。在一次会议中,他向我展示了完整的架构——推理树、基于FSM的审查、路由局部增量优化。我将他介绍给AI博士研究员,并帮助他思考研究方向。他现在正在探索使用LLM解决物理问题,使用Codex (GPT-5.4)等工具,并构建多智能体协作编码系统。
GitHub: Cerynitius/Tree_Of_Thought
🤖 iclaw —— 终端AI智能体(REPL)
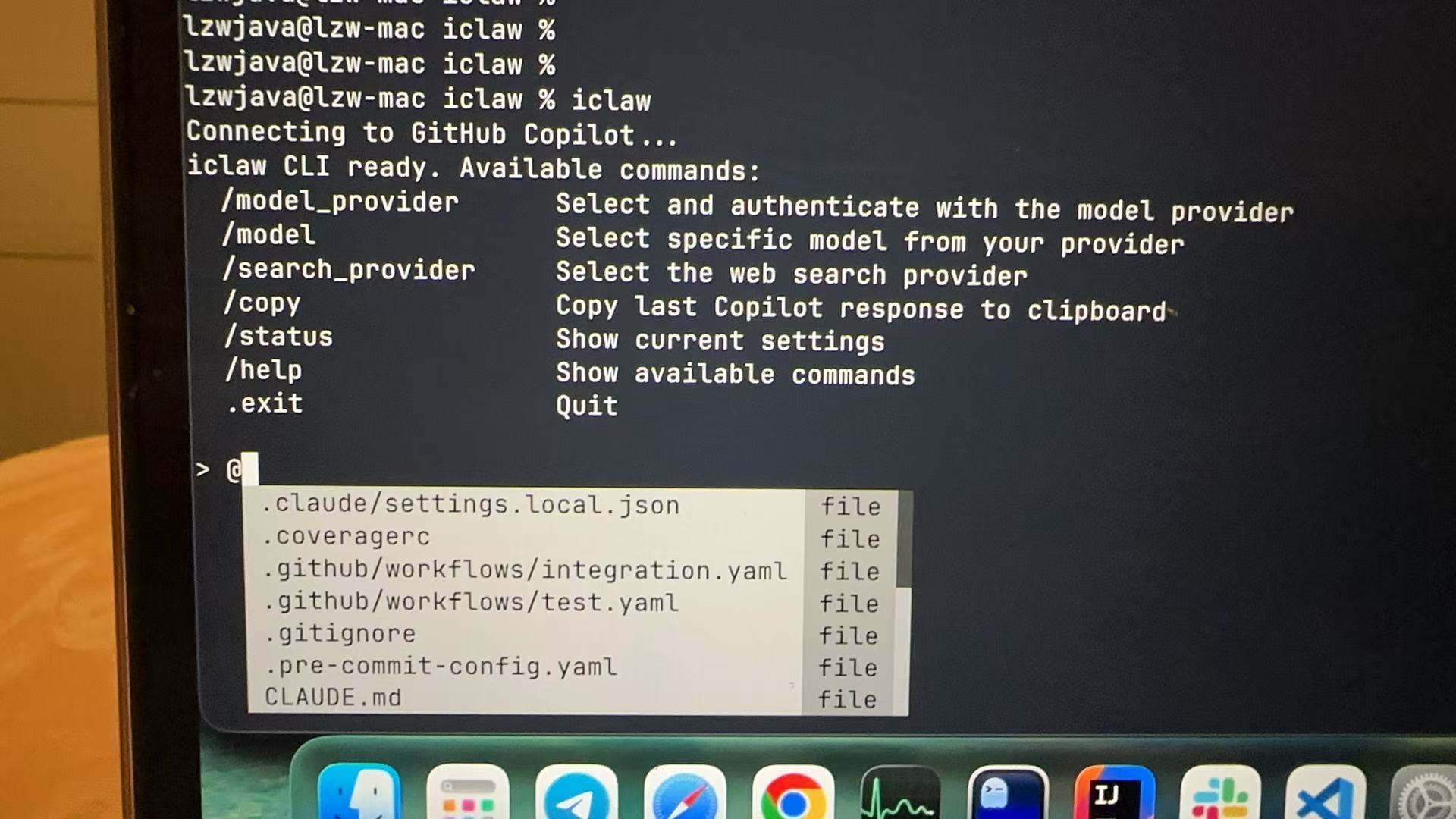
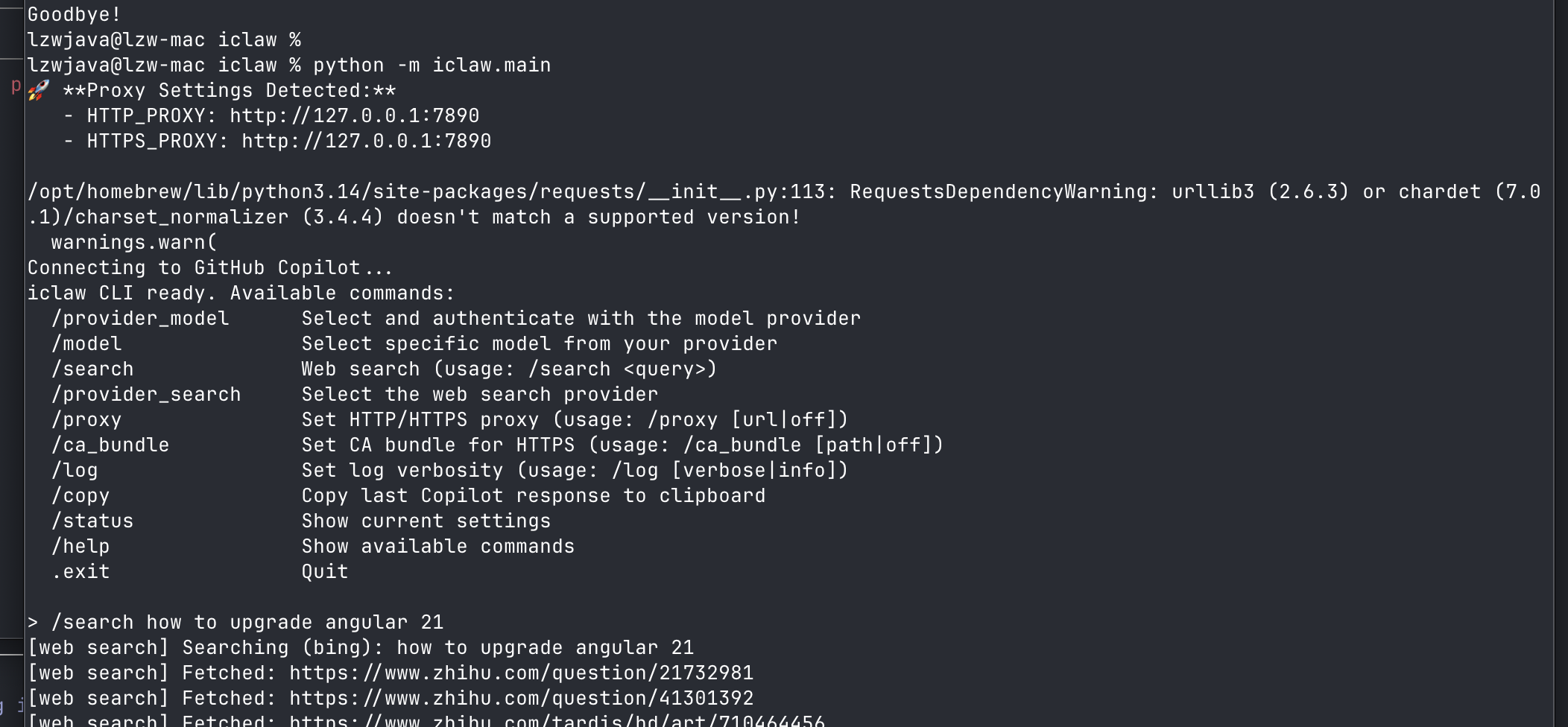
iclaw 是一个终端AI智能体,能够自主编码、搜索和执行命令 —— 可在个人机器和受限制的企业机器上运行。一个最小化的openclaw实现,作为纯Python CLI构建,无需浏览器扩展或IDE插件,由GitHub Copilot驱动。
lzwjava@lzw-mac iclaw % iclaw
██ █████ ██ █████ ██ ██
██ ██ ██ ██ ██ ██ ██
██ ██ ██ ███████ ██ █ ██
██ ██ ██ ██ ██ ██████
██ █████ ███████ ██ ██ ███ ██
可用命令:
/provider_model 选择并验证模型提供商
/model 从提供商中选择具体模型
/search 网页搜索(用法:/search <查询词>)
/provider_search 选择网页搜索提供商
/proxy 设置HTTP/HTTPS代理(用法:/proxy [url|off])
/ca_bundle 设置HTTPS的CA包(用法:/ca_bundle [path|off])
/log 设置日志详细程度(用法:/log [verbose|info])
/copy 复制最后一条Copilot响应到剪贴板
/read 将文件内容打印到终端(用法:/read <路径>)
/clear 清除对话历史
/compact 使用LLM压缩对话历史
/export 将完整对话历史导出为JSON文件
/status 显示当前设置
/help 显示可用命令
/exit 退出REPL。
主要特性:
- 多轮对话 与终端中的GitHub Copilot或OpenRouter。
- 多种模型提供商:GitHub Copilot(OAuth设备流)和OpenRouter(API密钥)。
- 原生工具调用:模型自主调用网页搜索、执行shell命令和编辑文件 —— 无需人工介入。
- 多种搜索提供商:DuckDuckGo、Startpage、Bing和Tavily。
- 企业友好:无需IDE插件或浏览器扩展。支持代理和CA包配置,可在企业防火墙后工作。
- 默认模型:GPT-5.2。
GitHub: lzwjava/iclaw
⚙️ zz —— 数据集处理与训练工具
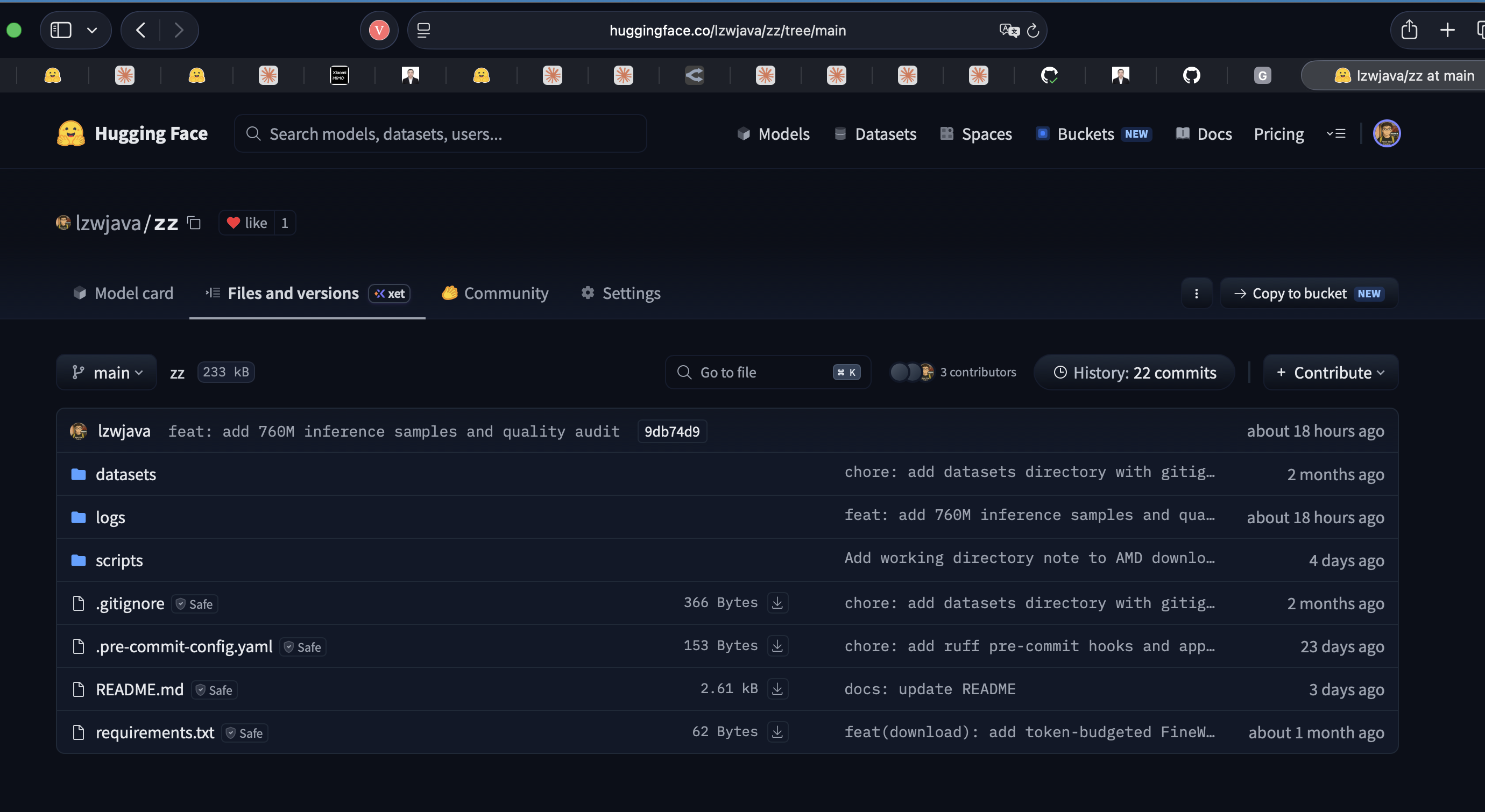
zz 是一个用于ML训练流水线的工具包 —— 数据集下载、token化、提取和推理工具。在RunPod H200、DigitalOcean H100和家中RTX 4070上的GPT-2 124M训练运行中使用。也托管在Hugging Face上。
lzwjava@lzw-mac zz % tree -L 1
scripts/
download/ # 数据集下载脚本(FineWeb、Wikimedia、HF镜像)
extract/ # 数据提取、token化和重命名
analysis/ # 训练时长和指标评估
deepseek/ # LLM推理脚本(DeepSeek-V2-Lite)
logs/ # 训练日志和输出
datasets/ # 下载的数据集存储
主要功能:
- FineWeb下载 —— 规划并下载分片以达到token预算(10B、100B+ tokens),可恢复,带进度跟踪。
- hf-mirror.com支持 —— 当HuggingFace被屏蔽时,提供用于中国访问的wget脚本。
- Parquet提取 —— 通过pyarrow iter_batches进行内存安全迭代。
- Token化 —— 将原始文本转换为训练就绪格式。
- 训练分析 —— 从训练日志计算时长、评估指标。
- DeepSeek推理 —— 用于DeepSeek-V2-Lite的LLM推理脚本。
GitHub: lzwjava/zz · Hugging Face: lzwjava/zz
🎓 证书
机器学习专项课程 —— DeepLearning.AI & Stanford University
2023年11月完成。三门课程:监督式机器学习、高级学习算法、无监督学习、推荐系统、强化学习。

深度学习专项课程 —— DeepLearning.AI
2023年12月完成。五门课程:神经网络、超参数调整、结构化机器学习项目、卷积神经网络、序列模型。

- GitHub: https://github.com/lzwjava
- 博客: https://lzwjava.github.io
原创,AI翻译,但整理分享仍需精力。如果觉得有帮助,欢迎
捐助支持。
微信:@lzwjava ·
X: @lzwjava ·
打个招呼 👋
·
X: @lzwjava ·
打个招呼 👋