## مقدمة إلى الحوسبة السحابية والبيانات الضخمة | أصلي، ترجم بواسطة AI
تحتوي هذه الدورة على المواضيع التالية:
- Spark
- Hadoop
- Kubernetes
- Docker
- Flink
- MongoDB
(ملاحظة: الأسماء التقنية مثل Spark وHadoop وKubernetes وDocker وFlink وMongoDB لا تُترجم عادةً في السياقات التقنية، لذا تم تركها كما هي.)
عند الحديث عن الحوسبة السحابية، يبدو أنه لا يمكن الاستغناء عن العديد من الأدوات مثل Hadoop وHive وHbase وZooKeeper وDocker وKubernetes وSpark وKafka وMongoDB وFlink وDruid وPresto وKylin وElastic Search. هل سمعت بها جميعًا؟ بعض هذه الأدوات وجدتها في وصف وظائف مثل مهندس البيانات الضخمة ومهندس الخلفية الموزعة. هذه الوظائف تتمتع برواتب عالية. دعونا نحاول تثبيتها جميعًا والتلاعب بها قليلاً.
استكشاف Spark الأولي
الموقع الرسمي يقول إن Spark هو محرك تحليل يستخدم لمعالجة البيانات الضخمة. Spark هو في الأساس مجموعة من المكتبات. يبدو أنه لا يتم تقسيمه إلى خادم و عميل مثل Redis. Spark يُستخدم فقط على جانب العميل. قمت بتحميل أحدث إصدار من الموقع الرسمي، وهو spark-3.1.1-bin-hadoop3.2.tar.
$ tree . -L 1
.
├── LICENSE
├── NOTICE
├── R
├── README.md
├── RELEASE
├── bin
├── conf
├── data
├── examples
├── jars
├── kubernetes
├── licenses
├── python
├── sbin
└── yarn
11 مجلدًا، 4 ملفات
يبدو أنها عبارة عن بعض مكتبات التحليل المكتوبة بلغات مختلفة.
كما ذكر الموقع الرسمي أنه يمكن تثبيت مكتبات التبعية مباشرة في Python باستخدام الأمر التالي:
`pip install pyspark`
```shell
$ pip install pyspark
جمع pyspark
تنزيل pyspark-3.1.1.tar.gz (212.3 MB)
|████████████████████████████████| 212.3 MB 14 kB/s
جمع py4j==0.10.9
تنزيل py4j-0.10.9-py2.py3-none-any.whl (198 kB)
|████████████████████████████████| 198 kB 145 kB/s
بناء عجلات للحزم المجمعة: pyspark
بناء عجلة لـ pyspark (setup.py) ... تم
تم إنشاء عجلة لـ pyspark: اسم الملف=pyspark-3.1.1-py2.py3-none-any.whl حجم=212767604 sha256=0b8079e82f3a5bcadad99179902d8c8ff9f8eccad928a469c11b97abdc960b72
تم تخزينها في الدليل: /Users/lzw/Library/Caches/pip/wheels/23/bf/e9/9f3500437422e2ab82246f25a51ee480a44d4efc6c27e50d33
تم بناء pyspark بنجاح
تثبيت الحزم المجمعة: py4j, pyspark
تم تثبيت py4j-0.10.9 و pyspark-3.1.1 بنجاح
تم التثبيت بنجاح.
هذا سيظهر على الموقع الرسمي، وهناك بعض الأمثلة.
./bin/run-example SparkPi 10
أوه، يبدو أنه يمكن تشغيل البرنامج الموجود في حزمة التثبيت التي تم تنزيلها للتو. لكن حدث خطأ.
$ ./bin/run-example SparkPi 10
21/03/11 00:06:15 WARN NativeCodeLoader: غير قادر على تحميل مكتبة native-hadoop لمنصتك... يتم استخدام الفئات المدمجة في جافا حيثما كان ذلك مناسبًا
21/03/11 00:06:16 INFO ResourceUtils: لم يتم تكوين موارد مخصصة لـ spark.driver.
21/03/11 00:06:16 WARN Utils: الخدمة 'sparkDriver' لم تتمكن من الربط على منفذ عشوائي مجاني. قد ترغب في التحقق مما إذا كان يتم تكوين عنوان ربط مناسب.
Spark هو محرك معالجة سريع وعام متوافق مع بيانات Hadoop. يمكنه العمل في مجموعات Hadoop من خلال YARN أو الوضع المستقل لـ Spark، ويمكنه معالجة البيانات في HDFS، HBase، Cassandra، Hive، وأي تنسيق إدخال من Hadoop. تم تصميمه لأداء كل من المعالجة الدفعية (مشابهة لـ MapReduce) وأحمال العمل الجديدة مثل البث المباشر، الاستعلامات التفاعلية، وتعلم الآلة.
ظهرت كلمة hadoop عدة مرات. بعد البحث على Google عن spark depends hadoop، وجدت هذا النص. يبدو أن هذا يعتمد على بيانات بتنسيق Hadoop. دعونا ندرس Hadoop أولاً.
Hadoop
بعد الاطلاع السريع على الموقع الرسمي، دعنا نبدأ بالتثبيت.
brew install hadoop
أثناء عملية التثبيت، دعونا نتعرف على الأمر.
مكتبة برمجيات Apache Hadoop هي إطار عمل يسمح بمعالجة مجموعات البيانات الكبيرة بشكل موزع عبر مجموعات من أجهزة الكمبيوتر باستخدام نماذج برمجية بسيطة. تم تصميمها لتتوسع من خوادم فردية إلى آلاف الأجهزة، حيث يوفر كل جهاز حسابًا محليًا وتخزينًا. بدلًا من الاعتماد على الأجهزة لتوفير التوفر العالي، تم تصميم المكتبة نفسها لاكتشاف والتعامل مع الأعطال على مستوى طبقة التطبيق، مما يوفر خدمة عالية التوفر على مجموعة من أجهزة الكمبيوتر، حيث قد يكون كل جهاز عرضة للأعطال.
بمعنى آخر، Hadoop هو إطار عمل مصمم لمعالجة مجموعات البيانات الموزعة. قد تكون هذه البيانات موزعة على العديد من أجهزة الكمبيوتر. يتم التعامل معها باستخدام نموذج برمجة بسيط. تم تصميمه للتمدد من خادم واحد إلى آلاف الأجهزة. بدلاً من الاعتماد على توفر الأجهزة العالية، تم تصميم هذه المكتبة للكشف عن الأخطاء ومعالجتها على مستوى التطبيق. وبالتالي، يمكن نشر خدمات عالية التوفر في عنقود (cluster)، على الرغم من أن كل جهاز في العنقود قد يكون عرضة للفشل.
$ brew install hadoop
خطأ:
homebrew-core هو استنساخ ضحل.
homebrew-cask هو استنساخ ضحل.
لتنفيذ `brew update`، قم أولاً بتشغيل:
git -C /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core fetch --unshallow
git -C /usr/local/Homebrew/Library/Taps/homebrew/homebrew-cask fetch --unshallow
قد تستغرق هذه الأوامر بضع دقائق للتنفيذ بسبب الحجم الكبير للمستودعات.
تم فرض هذا القيد بناءً على طلب GitHub لأن تحديث الاستنساخات الضحلة
هو عملية مكلفة للغاية بسبب تخطيط الشجرة وحركة المرور في
Homebrew/homebrew-core و Homebrew/homebrew-cask. نحن لا نقوم بذلك تلقائيًا
لتجنب تنفيذ عملية إلغاء الاستنساخ الضحلة بشكل متكرر في
أنظمة CI (والتي يجب إصلاحها بدلاً من ذلك لعدم استخدام استنساخات ضحلة). نأسف للإزعاج!
==> تنزيل https://homebrew.bintray.com/bottles/openjdk-15.0.1.big_sur.bottle.tar.gz
تم التنزيل مسبقًا: /Users/lzw/Library/Caches/Homebrew/downloads/d1e3ece4af1d225bc2607eaa4ce85a873d2c6d43757ae4415d195751bc431962--openjdk-15.0.1.big_sur.bottle.tar.gz
==> تنزيل https://www.apache.org/dyn/closer.lua?path=hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
تم التنزيل مسبقًا: /Users/lzw/Library/Caches/Homebrew/downloads/764c6a0ea7352bb8bb505989feee1b36dc628c2dcd6b93fef1ca829d191b4e1e--hadoop-3.3.0.tar.gz
==> تثبيت التبعيات لـ hadoop: openjdk
==> تثبيت تبعية hadoop: openjdk
==> صب openjdk-15.0.1.big_sur.bottle.tar.gz
==> ملاحظات
لكي تجد أغلفة Java النظامية هذا JDK، قم بإنشاء رابط رمزي باستخدام
sudo ln -sfn /usr/local/opt/openjdk/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk.jdk
openjdk هو keg-only، مما يعني أنه لم يتم إنشاء رابط رمزي له في /usr/local،
لأنه يتعارض مع غلاف java الخاص بـ macOS.
إذا كنت بحاجة إلى أن يكون openjdk أولًا في مسار PATH الخاص بك، قم بتنفيذ الأمر التالي:
echo 'export PATH="/usr/local/opt/openjdk/bin:$PATH"' >> /Users/lzw/.bash_profile
لتمكين المترجمات من العثور على openjdk، قد تحتاج إلى تعيين:
export CPPFLAGS="-I/usr/local/opt/openjdk/include"
==> الملخص
🍺 /usr/local/Cellar/openjdk/15.0.1: 614 ملفًا، 324.9 ميجابايت
==> تثبيت Hadoop
🍺 /usr/local/Cellar/hadoop/3.3.0: 21,819 ملفًا، 954.7 ميجابايت، تم البناء في دقيقتين و15 ثانية
==> ترقية تبعية واحدة:
Maven 3.3.3 -> 3.6.3_1
==> ترقية Maven 3.3.3 -> 3.6.3_1
==> تنزيل https://www.apache.org/dyn/closer.lua?path=maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
==> التنزيل من https://mirror.olnevhost.net/pub/apache/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
######################################################################## 100.0%
خطأ: خطوة brew link لم تكتمل بنجاح
تم بناء الصيغة، ولكن لم يتم إنشاء رابط رمزي في /usr/local
تعذر إنشاء رابط رمزي لـ bin/mvn
الهدف /usr/local/bin/mvn
هو رابط رمزي يتبع لـ Maven. يمكنك إلغاء الربط:
brew unlink maven
لإجبار الربط واستبدال جميع الملفات المتضاربة:
brew link --overwrite maven
لإدراج جميع الملفات التي سيتم حذفها:
brew link --overwrite --dry-run maven
الملفات التي قد تكون متضاربة هي: /usr/local/bin/mvn -> /usr/local/Cellar/maven/3.3.3/bin/mvn /usr/local/bin/mvnDebug -> /usr/local/Cellar/maven/3.3.3/bin/mvnDebug /usr/local/bin/mvnyjp -> /usr/local/Cellar/maven/3.3.3/bin/mvnyjp ==> الملخص 🍺 /usr/local/Cellar/maven/3.6.3_1: 87 ملفًا، 10.7 ميجابايت، تم بناؤها في 7 ثوانٍ إزالة: /usr/local/Cellar/maven/3.3.3… (92 ملفًا، 9 ميجابايت) ==> التحقق من التبعيات المعتمدة على الصيغ المحدثة… ==> لم يتم العثور على تبعيات معطلة! ==> تحذيرات ==> openjdk لكي تتمكن أغلفة Java النظامية من العثور على هذا JDK، قم بإنشاء رابط رمزي باستخدام sudo ln -sfn /usr/local/opt/openjdk/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk.jdk
openjdk هو keg-only، مما يعني أنه لم يتم إنشاء رابط رمزي له في /usr/local،
لأنه يتعارض مع الغلاف java الخاص بـ macOS.
إذا كنت بحاجة إلى أن يكون openjdk أولًا في مسار PATH الخاص بك، قم بتنفيذ الأمر التالي:
echo 'export PATH="/usr/local/opt/openjdk/bin:$PATH"' >> /Users/lzw/.bash_profile
هذا الأمر سيضيف مسار openjdk إلى ملف .bash_profile الخاص بك، مما يضمن أن يتم تحميله أولًا عند فتح أي طرفية جديدة.
لتمكين المترجمات من العثور على openjdk، قد تحتاج إلى تعيين:
export CPPFLAGS="-I/usr/local/opt/openjdk/include"
لاحظت في سجل إخراج brew أن maven لم يتم ربطه بشكل جيد. بعد ذلك، قمت بإجراء ربط إجباري للإصدار 3.6.3_1.
brew link --overwrite maven
تم تثبيت Hadoop بنجاح.
الوحدات
يتضمن المشروع هذه الوحدات:
- Hadoop Common: الأدوات المشتركة التي تدعم وحدات Hadoop الأخرى.
- نظام الملفات الموزع Hadoop (HDFS™): نظام ملفات موزع يوفر وصولًا عالي الإنتاجية لبيانات التطبيقات.
- Hadoop YARN: إطار عمل لجدولة المهام وإدارة موارد العنقودية.
- Hadoop MapReduce: نظام يعتمد على YARN لمعالجة مجموعات البيانات الكبيرة بشكل متوازي.
- Hadoop Ozone: مخزن كائنات لـ Hadoop.
يبدو أن هناك وحدات متاحة. عند كتابة hadoop، سيظهر التالي:
$ hadoop
الاستخدام: hadoop [خيارات] أمر_فرعي [خيارات الأمر الفرعي]
أو hadoop [خيارات] اسم_الصف [خيارات اسم الصف]
حيث اسم_الصف هو صف Java مقدم من المستخدم
الخيارات إما لا شيء أو أي من:
–config dir دليل تهيئة Hadoop –debug تفعيل وضع تصحيح الأخطاء في سكريبت الشل –help معلومات الاستخدام buildpaths محاولة إضافة ملفات الفئات من شجرة البناء hostnames list[,of,host,names] الأسماء المضيفة للاستخدام في وضع العبد (slave mode) hosts filename قائمة الأسماء المضيفة للاستخدام في وضع العبد (slave mode) loglevel level تعيين مستوى log4j لهذا الأمر workers تفعيل وضع العامل (worker mode)
SUBCOMMAND هو أحد الأوامر التالية: أوامر الإدارة:
daemonlog الحصول على/تعيين مستوى السجل لكل خادم (daemon)
أوامر العميل:
archive إنشاء أرشيف Hadoop
checknative التحقق من توفر مكتبات Hadoop الأصلية وضغطها
classpath طباعة مسار الفئة المطلوب للحصول على ملف Hadoop jar والمكتبات المطلوبة
conftest التحقق من صحة ملفات التكوين XML
credential التفاعل مع مزودي الاعتمادات
distch أداة تغيير البيانات الوصفية الموزعة
distcp نسخ ملف أو أدلة بشكل متكرر
dtutil عمليات متعلقة برموز التفويض
envvars عرض متغيرات بيئة Hadoop المحسوبة
fs تشغيل عميل نظام ملفات عام
gridmix إرسال مزيج من الوظائف الاصطناعية، نمذجة حمل من إنتاج مسبق
jar <jar> تشغيل ملف jar. ملاحظة: يرجى استخدام "yarn jar" لبدء تطبيقات YARN، وليس هذا الأمر.
jnipath طباعة java.library.path
kdiag تشخيص مشاكل Kerberos
kerbname عرض تحويل المبدأ auth_to_local
key إدارة المفاتيح عبر KeyProvider
rumenfolder تحجيم أثر إدخال rumen
rumentrace تحويل السجلات إلى أثر rumen
s3guard إدارة البيانات الوصفية على S3
trace عرض وتعديل إعدادات تتبع Hadoop
version طباعة الإصدار
الأوامر الخفية (Daemon Commands):
kms تشغيل KMS، خادم إدارة المفاتيح registrydns تشغيل خادم DNS للسجل
قد يطبع SUBCOMMAND المساعدة عند استدعائه بدون معاملات أو باستخدام -h.
الموقع الرسمي قدم بعض الأمثلة.
```shell
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+'
$ cat output/*
لاحظت وجود ملف share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar. هذا يعني أنه ربما تكون هناك بعض ملفات الأمثلة التي لم نحصل عليها. أتوقع أن تثبيت Homebrew قد لا يشمل هذه الملفات. لذلك قمنا بتنزيل حزمة التثبيت من الموقع الرسمي.
$ tree . -L 1
.
├── LICENSE-binary
├── LICENSE.txt
├── NOTICE-binary
├── NOTICE.txt
├── README.txt
├── bin
├── etc
├── include
├── lib
├── libexec
├── licenses-binary
├── sbin
└── share
ظهر دليل share. ولكن هل حقًا Homebrew لا يحتوي على هذه الملفات الإضافية؟ ابحث عن دليل تثبيت Homebrew.
$ type hadoop
hadoop هو /usr/local/bin/hadoop
$ ls -alrt /usr/local/bin/hadoop
lrwxr-xr-x 1 lzw admin 33 Mar 11 00:48 /usr/local/bin/hadoop -> ../Cellar/hadoop/3.3.0/bin/hadoop
$ cd /usr/local/Cellar/hadoop/3.3.0
هذا هو شجرة الدليل المطبوع في /usr/local/Cellar/hadoop/3.3.0/libexec/share/hadoop.
$ tree . -L 2
.
├── client
│ ├── hadoop-client-api-3.3.0.jar
│ ├── hadoop-client-minicluster-3.3.0.jar
│ └── hadoop-client-runtime-3.3.0.jar
├── common
│ ├── hadoop-common-3.3.0-tests.jar
│ ├── hadoop-common-3.3.0.jar
│ ├── hadoop-kms-3.3.0.jar
│ ├── hadoop-nfs-3.3.0.jar
│ ├── hadoop-registry-3.3.0.jar
│ ├── jdiff
│ ├── lib
│ ├── sources
│ └── webapps
├── hdfs
│ ├── hadoop-hdfs-3.3.0-tests.jar
│ ├── hadoop-hdfs-3.3.0.jar
│ ├── hadoop-hdfs-client-3.3.0-tests.jar
│ ├── hadoop-hdfs-client-3.3.0.jar
│ ├── hadoop-hdfs-httpfs-3.3.0.jar
│ ├── hadoop-hdfs-native-client-3.3.0-tests.jar
│ ├── hadoop-hdfs-native-client-3.3.0.jar
│ ├── hadoop-hdfs-nfs-3.3.0.jar
│ ├── hadoop-hdfs-rbf-3.3.0-tests.jar
│ ├── hadoop-hdfs-rbf-3.3.0.jar
│ ├── jdiff
│ ├── lib
│ ├── sources
│ └── webapps
├── mapreduce
│ ├── hadoop-mapreduce-client-app-3.3.0.jar
│ ├── hadoop-mapreduce-client-common-3.3.0.jar
│ ├── hadoop-mapreduce-client-core-3.3.0.jar
│ ├── hadoop-mapreduce-client-hs-3.3.0.jar
│ ├── hadoop-mapreduce-client-hs-plugins-3.3.0.jar
│ ├── hadoop-mapreduce-client-jobclient-3.3.0-tests.jar
│ ├── hadoop-mapreduce-client-jobclient-3.3.0.jar
│ ├── hadoop-mapreduce-client-nativetask-3.3.0.jar
│ ├── hadoop-mapreduce-client-shuffle-3.3.0.jar
│ ├── hadoop-mapreduce-client-uploader-3.3.0.jar
│ ├── hadoop-mapreduce-examples-3.3.0.jar
│ ├── jdiff
│ ├── lib-examples
│ └── sources
├── tools
│ ├── dynamometer
│ ├── lib
│ ├── resourceestimator
│ ├── sls
│ └── sources
└── yarn
├── csi
├── hadoop-yarn-api-3.3.0.jar
├── hadoop-yarn-applications-catalog-webapp-3.3.0.war
├── hadoop-yarn-applications-distributedshell-3.3.0.jar
├── hadoop-yarn-applications-mawo-core-3.3.0.jar
├── hadoop-yarn-applications-unmanaged-am-launcher-3.3.0.jar
├── hadoop-yarn-client-3.3.0.jar
├── hadoop-yarn-common-3.3.0.jar
├── hadoop-yarn-registry-3.3.0.jar
├── hadoop-yarn-server-applicationhistoryservice-3.3.0.jar
├── hadoop-yarn-server-common-3.3.0.jar
├── hadoop-yarn-server-nodemanager-3.3.0.jar
├── hadoop-yarn-server-resourcemanager-3.3.0.jar
├── hadoop-yarn-server-router-3.3.0.jar
├── hadoop-yarn-server-sharedcachemanager-3.3.0.jar
├── hadoop-yarn-server-tests-3.3.0.jar
├── hadoop-yarn-server-timeline-pluginstorage-3.3.0.jar
├── hadoop-yarn-server-web-proxy-3.3.0.jar
├── hadoop-yarn-services-api-3.3.0.jar
├── hadoop-yarn-services-core-3.3.0.jar
├── lib
├── sources
├── test
├── timelineservice
├── webapps
└── yarn-service-examples
يمكنك أن ترى العديد من حزم jar.
$ mkdir input
$ ls
bin hadoop-config.sh hdfs-config.sh libexec sbin yarn-config.sh
etc hadoop-functions.sh input mapred-config.sh share
$ cp etc/hadoop/*.xml input
$ cd input/
$ ls
capacity-scheduler.xml hadoop-policy.xml hdfs-site.xml kms-acls.xml mapred-site.xml
core-site.xml hdfs-rbf-site.xml httpfs-site.xml kms-site.xml yarn-site.xml
$ cd ..
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+'
JAR غير موجود أو ليس ملفًا عاديًا: /usr/local/Cellar/hadoop/3.3.0/libexec/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar
$
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep input output 'dfs[a-z.]+'
2021-03-11 01:54:30,791 WARN util.NativeCodeLoader: غير قادر على تحميل مكتبة native-hadoop لمنصتك... يتم استخدام فئات Java المدمجة حيثما كان ذلك ممكنًا
2021-03-11 01:54:31,115 INFO impl.MetricsConfig: تم تحميل الخصائص من hadoop-metrics2.properties
2021-03-11 01:54:31,232 INFO impl.MetricsSystemImpl: تم جدولة فترة لقطة المقاييس كل 10 ثانية.
...
بعد اتباع المثال الموجود على الموقع الرسمي، لاحظت أن الأمر bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input يحتوي على رقم إصدار قبل حزمة jar. لذلك، يجب تغيير هذا الرقم إلى الإصدار الخاص بنا وهو 3.3.0.
نهاية السجل:
2021-03-11 01:54:35,374 INFO mapreduce.Job: تم تنفيذ الخريطة بنسبة 100% والاختزال بنسبة 100%
2021-03-11 01:54:35,374 INFO mapreduce.Job: تم إكمال المهمة job_local2087514596_0002 بنجاح
2021-03-11 01:54:35,377 INFO mapreduce.Job: العدادات: 30
عدادات نظام الملفات
FILE: عدد البايتات المقروءة=1204316
FILE: عدد البايتات المكتوبة=3565480
FILE: عدد عمليات القراءة=0
FILE: عدد عمليات القراءة الكبيرة=0
FILE: عدد عمليات الكتابة=0
إطار عمل Map-Reduce
سجلات الإدخال للخريطة=1
سجلات الإخراج للخريطة=1
بايتات الإخراج للخريطة=17
بايتات الإخراج المادية للخريطة=25
بايتات تقسيم الإدخال=141
سجلات الإدخال للجمع=0
سجلات الإخراج للجمع=0
مجموعات الإدخال للاختزال=1
بايتات الاختلاط للاختزال=25
سجلات الإدخال للاختزال=1
سجلات الإخراج للاختزال=1
السجلات المنسكبة=2
الخرائط المختلطة=1
عمليات الاختلاط الفاشلة=0
مخرجات الخرائط المدمجة=1
الوقت المستغرق في جمع القمامة (مللي ثانية)=57
إجمالي استخدام الذاكرة المخصصة (بايت)=772800512
أخطاء الاختلاط
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
عدادات تنسيق إدخال الملف
البايتات المقروءة=123
عدادات تنسيق إخراج الملف
البايتات المكتوبة=23
تابع القراءة.
$ cat output/*
1 dfsadmin
ملاحظة: النص أعلاه هو أمر في سطر الأوامر (shell command) يقوم بعرض محتويات جميع الملفات في مجلد output/. النتيجة المعروضة هي 1 dfsadmin. لا يوجد حاجة لترجمة الأوامر أو المخرجات البرمجية.
ماذا يعني هذا بالضبط؟ لا بأس، على أي حال، لقد قمنا بتشغيل Hadoop بنجاح. وقمنا بتشغيل أول مثال حسابي على نسخة مستقلة.
Spark
بالعودة إلى Spark. لنلقِ نظرة على مثال.
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")
ظهر هنا ملف hdfs. بعد البحث، اكتشفت أنه يمكن إنشاء ملف hdfs بهذه الطريقة:
hdfs dfs -mkdir /test
تم ترجمة الأمر إلى:
hdfs dfs -mkdir /test
ملاحظة: الأمر نفسه بقي كما هو لأنه أمر برمجي ولا يتم ترجمته.
لنلقِ نظرة على أمر hdfs.
$ hdfs
الاستخدام: hdfs [خيارات] الأمر_الفرعي [خيارات الأمر_الفرعي]
OPTIONS إما لا شيء أو أي من:
–buildpaths محاولة إضافة ملفات الفئات من شجرة البناء –config dir دليل تهيئة Hadoop –daemon (start|status|stop) تشغيل أو التحقق من حالة أو إيقاف الخدمة الخلفية –debug تفعيل وضع تصحيح الأخطاء في البرنامج النصي للقشرة –help معلومات الاستخدام –hostnames list[,of,host,names] الأسماء المضيفة التي سيتم استخدامها في وضع العامل –hosts filename قائمة الأسماء المضيفة التي سيتم استخدامها في وضع العامل –loglevel level تعيين مستوى log4j لهذا الأمر –workers تفعيل وضع العامل
SUBCOMMAND هو واحد من: أوامر الإدارة:
cacheadmin تكوين ذاكرة التخزين المؤقت لـ HDFS crypto تكوين مناطق التشفير في HDFS debug تشغيل Debug Admin لتنفيذ أوامر تصحيح HDFS dfsadmin تشغيل عميل إدارة DFS dfsrouteradmin إدارة الاتحاد القائم على Router ec تشغيل واجهة سطر أوامر الترميز الإضافي لـ HDFS fsck تشغيل أداة فحص نظام ملفات DFS haadmin تشغيل عميل إدارة HA لـ DFS jmxget الحصول على القيم المصدرة من JMX من NameNode أو DataNode oev تطبيق عارض التعديلات غير المتصل على ملف التعديلات oiv تطبيق عارض صورة نظام الملفات غير المتصل على صورة نظام الملفات oiv_legacy تطبيق عارض صورة نظام الملفات غير المتصل على صورة نظام ملفات قديمة storagepolicies إدراج/الحصول/تعيين/تحقيق سياسات تخزين الكتل
أوامر العميل:
classpath يطبع مسار الفئة المطلوب للحصول على ملف hadoop.jar والمكتبات المطلوبة
dfs تشغيل أمر نظام الملفات على نظام الملفات
envvars عرض متغيرات بيئة Hadoop المحسوبة
fetchdt جلب رمز تفويض من NameNode
getconf الحصول على قيم التكوين من الإعدادات
groups الحصول على المجموعات التي ينتمي إليها المستخدمون
lsSnapshottableDir سرد جميع الدلائل القابلة لالتقاط اللقطات والمملوكة للمستخدم الحالي
snapshotDiff مقارنة لقطتين لدليل أو مقارنة محتويات الدليل الحالي مع لقطة
version طباعة الإصدار
أوامر Daemon:
balancer تشغيل أداة موازنة الكتلة
datanode تشغيل عقدة بيانات DFS
dfsrouter تشغيل موجه DFS
diskbalancer توزيع البيانات بالتساوي بين الأقراص على عقدة معينة
httpfs تشغيل خادم HttpFS، بوابة HTTP لـ HDFS
journalnode تشغيل عقدة دفتر اليومية لـ DFS
mover تشغيل أداة لنقل نسخ الكتل عبر أنواع التخزين
namenode تشغيل عقدة الاسم لـ DFS
nfs3 تشغيل بوابة إصدار 3 من NFS
portmap تشغيل خدمة portmap
secondarynamenode تشغيل عقدة الاسم الثانوية لـ DFS
sps تشغيل محقق سياسة التخزين الخارجي
zkfc تشغيل وحدة تحكم فشل ZK
قد يطبع SUBCOMMAND المساعدة عند استدعائه بدون معاملات أو باستخدام -h.
استمر في تعديل الكود.
```python
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]")\
.config('spark.driver.bindAddress', '127.0.0.1')\
.getOrCreate()
sc = spark.sparkContext
text_file = sc.textFile("a.txt")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("b.txt")
من المهم ملاحظة .config('spark.driver.bindAddress', '127.0.0.1'). وإلا، سيتم إرجاع خطأ Service 'sparkDriver' could not bind on a random free port. You may check whether configuring an appropriate binding address.
ومع ذلك، حدث خطأ مرة أخرى.
Caused by: org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/pyspark/python/lib/pyspark.zip/pyspark/worker.py", line 473, in main
raise Exception(("Python in worker has different version %s than that in " +
Exception: Python في العامل لديه إصدار مختلف 3.8 عن الإصدار في السائق 3.9، PySpark لا يمكن أن يعمل مع إصدارات ثانوية مختلفة. يرجى التحقق من أن متغيرات البيئة PYSPARK_PYTHON و PYSPARK_DRIVER_PYTHON مضبوطة بشكل صحيح.
يعني تشغيل إصدارات مختلفة من Python.
تعديل ملف .bash_profile:
PYSPARK_PYTHON=/usr/local/Cellar/python@3.9/3.9.1_6/bin/python3
PYSPARK_DRIVER_PYTHON=/usr/local/Cellar/python@3.9/3.9.1_6/bin/python3
ومع ذلك، لا يزال الخطأ نفسه يظهر. بعد البحث، تبين أن السبب قد يكون أن spark لا يقوم بتحميل متغير البيئة هذا عند التشغيل، ولا يستخدم متغيرات البيئة الافتراضية للمحطة الطرفية.
يجب تعيين الإعدادات التالية في الكود:
import os
تعيين بيئات Spark
os.environ['PYSPARK_PYTHON'] = '/usr/local/Cellar/python@3.9/3.9.1_6/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/usr/local/Cellar/python@3.9/3.9.1_6/bin/python3'
هذا سيعمل.
$ python sc.py
21/03/11 02:54:52 WARN NativeCodeLoader: غير قادر على تحميل مكتبة native-hadoop لمنصتك... يتم استخدام الفئات المدمجة في جافا حيثما ينطبق ذلك
يتم استخدام ملف تعريف log4j الافتراضي لـ Spark: org/apache/spark/log4j-defaults.properties
تم تعيين مستوى تسجيل الدخول الافتراضي إلى "WARN".
لضبط مستوى تسجيل الدخول، استخدم sc.setLogLevel(newLevel). بالنسبة لـ SparkR، استخدم setLogLevel(newLevel).
PythonRDD[6] at RDD at PythonRDD.scala:53
تم إنشاء الملف b.txt في هذه المرحلة.
├── b.txt
│ ├── _SUCCESS
│ ├── part-00000
│ └── part-00001
افتحها.
$ cat b.txt/part-00000
('college', 1)
('two', 1)
('things', 2)
('worked', 1)
('on,', 1)
('of', 8)
('school,', 2)
('writing', 2)
('programming.', 1)
("didn't", 4)
('then,', 1)
('probably', 1)
('are:', 1)
('short', 1)
('awful.', 1)
('They', 1)
('plot,', 1)
('just', 1)
('characters', 1)
('them', 2)
...
لقد نجحت! أليس هذا مألوفًا؟ إنه يشبه تمامًا المثال في Hadoop.
$ cat output/*
1 dfsadmin
هذه الملفات تُسمى HDFS. يمكننا هنا استخدام Spark لحساب عدد الكلمات. ببضع جمل بسيطة، يبدو الأمر مريحًا للغاية.
Kubernetes
بعد ذلك، سنتعامل مع Kubernetes، المعروف أيضًا باسم k8s، حيث يتم اختصار الحروف الثمانية في المنتصف إلى الرقم 8. إنه نظام مفتوح المصدر يستخدم لأتمتة نشر وتوسيع وإدارة تطبيقات الحاويات.
أداة سطر الأوامر kubectl تُستخدم لتشغيل بعض الأوامر على عنقود (cluster) Kubernetes. يمكن استخدامها لنشر التطبيقات، وعرض وإدارة موارد العنقود، وكذلك لعرض السجلات (logs).
يمكن أيضًا تثبيته باستخدام Homebrew.
brew install kubectl
إخراج السجل:
==> تنزيل https://homebrew.bintray.com/bottles/kubernetes-cli-1.20.1.big_sur.bottle.tar.gz
==> التنزيل من https://d29vzk4ow07wi7.cloudfront.net/0b4f08bd1d47cb913d7cd4571e3394c6747dfbad7ff114c5589c8396c1085ecf?response-content-disposition=a
######################################################################## 100.0%
==> صب kubernetes-cli-1.20.1.big_sur.bottle.tar.gz
==> ملاحظات
تم تثبيت إكمال Bash في:
/usr/local/etc/bash_completion.d
==> ملخص
🍺 /usr/local/Cellar/kubernetes-cli/1.20.1: 246 ملفًا، 46.1 ميجابايت
تم التثبيت بنجاح.
$ kubectl version --client
Client Version: version.Info{Major:"1", Minor:"20", GitVersion:"v1.20.1", GitCommit:"c4d752765b3bbac2237bf87cf0b1c2e307844666", GitTreeState:"clean", BuildDate:"2020-12-19T08:38:20Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"darwin/amd64"}
$ kubectl
kubectl تتحكم في مدير مجموعة Kubernetes.
يمكنك العثور على مزيد من المعلومات في الرابط التالي:
https://kubernetes.io/docs/reference/kubectl/overview/
الأوامر الأساسية (للمبتدئين): إنشاء إنشاء مورد من ملف أو من stdin. كشف أخذ وحدة تحكم تكرار (replication controller)، خدمة (service)، نشر (deployment) أو وعاء (pod) وكشفها كخدمة جديدة في Kubernetes تشغيل تشغيل صورة معينة على الكتلة (cluster) تعيين تعيين ميزات محددة على الكائنات
الأوامر الأساسية (متوسطة المستوى): explain توثيق الموارد get عرض واحد أو العديد من الموارد edit تعديل مورد على الخادم delete حذف الموارد عن طريق أسماء الملفات، stdin، الموارد والأسماء، أو عن طريق الموارد ومحدد التسمية
أوامر النشر: rollout إدارة عملية النشر لمورد scale تعيين حجم جديد لنشر (Deployment)، مجموعة نسخ (ReplicaSet)، أو وحدة تحكم النسخ المتماثل (Replication Controller) autoscale التحكم التلقائي في الحجم لنشر (Deployment)، مجموعة نسخ (ReplicaSet)، أو وحدة تحكم النسخ المتماثل (ReplicationController)
أوامر إدارة الكتلة (Cluster): certificate تعديل موارد الشهادات. cluster-info عرض معلومات الكتلة. top عرض استخدام الموارد (وحدة المعالجة المركزية/الذاكرة/التخزين). cordon تعيين العقدة على أنها غير قابلة للجدولة. uncordon تعيين العقدة على أنها قابلة للجدولة. drain إفراغ العقدة استعدادًا للصيانة. taint تحديث العيوب (Taints) على عقدة واحدة أو أكثر.
أوامر استكشاف الأخطاء وإصلاحها: describe عرض تفاصيل مورد محدد أو مجموعة من الموارد logs طباعة سجلات (logs) لحاوية في pod attach الاتصال بحاوية قيد التشغيل exec تنفيذ أمر في حاوية port-forward توجيه منفذ أو أكثر من المنافذ المحلية إلى pod proxy تشغيل وكيل (proxy) لخادم Kubernetes API cp نسخ الملفات والمجلدات من وإلى الحاويات auth فحص التفويضات (authorization) debug إنشاء جلسات تصحيح (debugging) لاستكشاف أخطاء الأعباء العملية (workloads) والعقد (nodes)
الأوامر المتقدمة: diff مقارنة النسخة الحية مع النسخة التي سيتم تطبيقها apply تطبيق التكوين على مورد من خلال اسم الملف أو المدخلات القياسية patch تحديث حقل أو أكثر من مورد replace استبدال مورد من خلال اسم الملف أو المدخلات القياسية wait تجريبي: انتظار حالة محددة على مورد واحد أو عدة موارد. kustomize بناء هدف kustomization من دليل أو عنوان URL بعيد.
أوامر الإعدادات: label تحديث التسميات على مورد annotate تحديث التعليقات التوضيحية على مورد completion إخراج كود إكمال shell لـ shell محدد (bash أو zsh)
الأوامر الأخرى: api-resources طباعة موارد API المدعومة على الخادم api-versions طباعة إصدارات API المدعومة على الخادم، في شكل “group/version” config تعديل ملفات kubeconfig plugin يوفر أدوات للتفاعل مع الإضافات. version طباعة معلومات إصدار العميل والخادم
الاستخدام: kubectl [flags] [options]
استخدم “kubectl
استخدم “kubectl options” للحصول على قائمة بخيارات سطر الأوامر العامة (تنطبق على جميع الأوامر).
لنقم بإنشاء ملف تكوين.
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
minReadySeconds: 5
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
```shell
$ kubectl apply -f simple_deployment.yaml
تم رفض الاتصال بالخادم localhost:8080 - هل حددت المضيف أو المنفذ الصحيح؟
$ kubectl cluster-info
لتصحيح أخطاء الكتلة وتشخيص المشكلات بشكل أكبر، استخدم الأمر kubectl cluster-info dump.
تم رفض الاتصال بالخادم localhost:8080 - هل حددت المضيف أو المنفذ الصحيح؟
عندما أجرب تشغيله في الطرفية على الموقع الرسمي.
```shell
$ start.sh
بدء تشغيل Kubernetes...إصدار minikube: v1.8.1
commit: cbda04cf6bbe65e987ae52bb393c10099ab62014
* minikube v1.8.1 على Ubuntu 18.04
* استخدام برنامج التشغيل none بناءً على تكوين المستخدم
* التشغيل على localhost (CPUs=2, Memory=2460MB, Disk=145651MB) ...
* إصدار النظام هو Ubuntu 18.04.4 LTS
- تجهيز Kubernetes الإصدار v1.17.3 على Docker الإصدار 19.03.6 …
- kubelet.resolv-conf=/run/systemd/resolve/resolv.conf
- بدء تشغيل Kubernetes …
- تمكين الإضافات: default-storageclass, storage-provisioner
- تهيئة بيئة المضيف المحلي …
- تم الانتهاء! تم تكوين kubectl لاستخدام “minikube”
- تم تمكين إضافة ‘dashboard’ تم بدء تشغيل Kubernetes ```
لنعد إلى طرفيتنا (Terminal).
$ kubectl version --client
Client Version: version.Info{Major:"1", Minor:"20", GitVersion:"v1.20.1", GitCommit:"c4d752765b3bbac2237bf87cf0b1c2e307844666", GitTreeState:"clean", BuildDate:"2020-12-19T08:38:20Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"darwin/amd64"}
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"20", GitVersion:"v1.20.1", GitCommit:"c4d752765b3bbac2237bf87cf0b1c2e307844666", GitTreeState:"clean", BuildDate:"2020-12-19T08:38:20Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"darwin/amd64"}
تم رفض الاتصال بالخادم localhost:8080 - هل حددت المضيف أو المنفذ الصحيح؟
من المثير للاهتمام أن إضافة الخيار --client لم يتسبب في حدوث خطأ.
توضح الوثائق أنه يجب تثبيت Minikube أولاً.
$ brew install minikube
==> تنزيل https://homebrew.bintray.com/bottles/minikube-1.16.0.big_sur.bottle.tar.gz
==> التنزيل من https://d29vzk4ow07wi7.cloudfront.net/1b6d7d1b97b11b6b07e4fa531c2dc21770da290da9b2816f360fd923e00c85fc?response-content-disposition=a
######################################################################## 100.0%
==> صب minikube-1.16.0.big_sur.bottle.tar.gz
==> ملاحظات
تم تثبيت إكمال Bash في:
/usr/local/etc/bash_completion.d
==> ملخص
🍺 /usr/local/Cellar/minikube/1.16.0: 8 ملفات، 64.6MB
$ minikube start
😄 minikube الإصدار v1.16.0 على نظام Darwin 11.2.2
🎉 الإصدار 1.18.1 من minikube متاح الآن! قم بتنزيله من: https://github.com/kubernetes/minikube/releases/tag/v1.18.1
💡 لتعطيل هذه الإشعارات، قم بتنفيذ الأمر: 'minikube config set WantUpdateNotification false'
✨ تم اختيار برنامج virtualbox كسائق تلقائيًا 💿 يتم تنزيل صورة تمهيد الجهاز الظاهري … > minikube-v1.16.0.iso.sha256: 65 بايت / 65 بايت [————-] 100.00% ? ب/ث 0 ثانية > minikube-v1.16.0.iso: 212.62 ميجابايت / 212.62 ميجابايت [] 100.00% 5.32 ميجابايت/ثانية 40 ثانية 👍 بدء تشغيل عقدة التحكم الرئيسية minikube في الكتلة minikube 💾 يتم تنزيل Kubernetes v1.20.0 مسبقًا … > preloaded-images-k8s-v8-v1….: 491.00 ميجابايت / 491.00 ميجابايت 100.00% 7.52 ميجابايت 🔥 يتم إنشاء الجهاز الظاهري virtualbox (المعالجات=2، الذاكرة=4000 ميجابايت، القرص=20000 ميجابايت) … ❗ يواجه هذا الجهاز الظاهري مشكلة في الوصول إلى https://k8s.gcr.io 💡 لسحب صور خارجية جديدة، قد تحتاج إلى تكوين خادم وكيل: https://minikube.sigs.k8s.io/docs/reference/networking/proxy/ 🐳 يتم تجهيز Kubernetes v1.20.0 على Docker 20.10.0 … ▪ إنشاء الشهادات والمفاتيح … ▪ تشغيل عقدة التحكم الرئيسية … ▪ تكوين قواعد RBAC … 🔎 يتم التحقق من مكونات Kubernetes… 🌟 تم تمكين الإضافات: storage-provisioner, default-storageclass 🏄 تم الانتهاء! تم تكوين kubectl لاستخدام الكتلة “minikube” ومساحة الاسم “default” بشكل افتراضي
لنقم الآن بالوصول إلى هذا الكتلة (Cluster).
```shell
$ kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-74ff55c5b-ndbcr 1/1 Running 0 60s
kube-system etcd-minikube 0/1 Running 0 74s
kube-system kube-apiserver-minikube 1/1 Running 0 74s
kube-system kube-controller-manager-minikube 1/1 Running 0 74s
kube-system kube-proxy-g2296 1/1 Running 0 60s
kube-system kube-scheduler-minikube 0/1 Running 0 74s
kube-system storage-provisioner 1/1 Running 1 74s
لنفتح لوحة تحكم minikube.
$ minikube dashboard
🔌 تمكين لوحة التحكم ...
🤔 التحقق من صحة لوحة التحكم ...
🚀 تشغيل الوكيل ...
🤔 التحقق من صحة الوكيل ...
🎉 فتح http://127.0.0.1:50030/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/ في المتصفح الافتراضي الخاص بك...
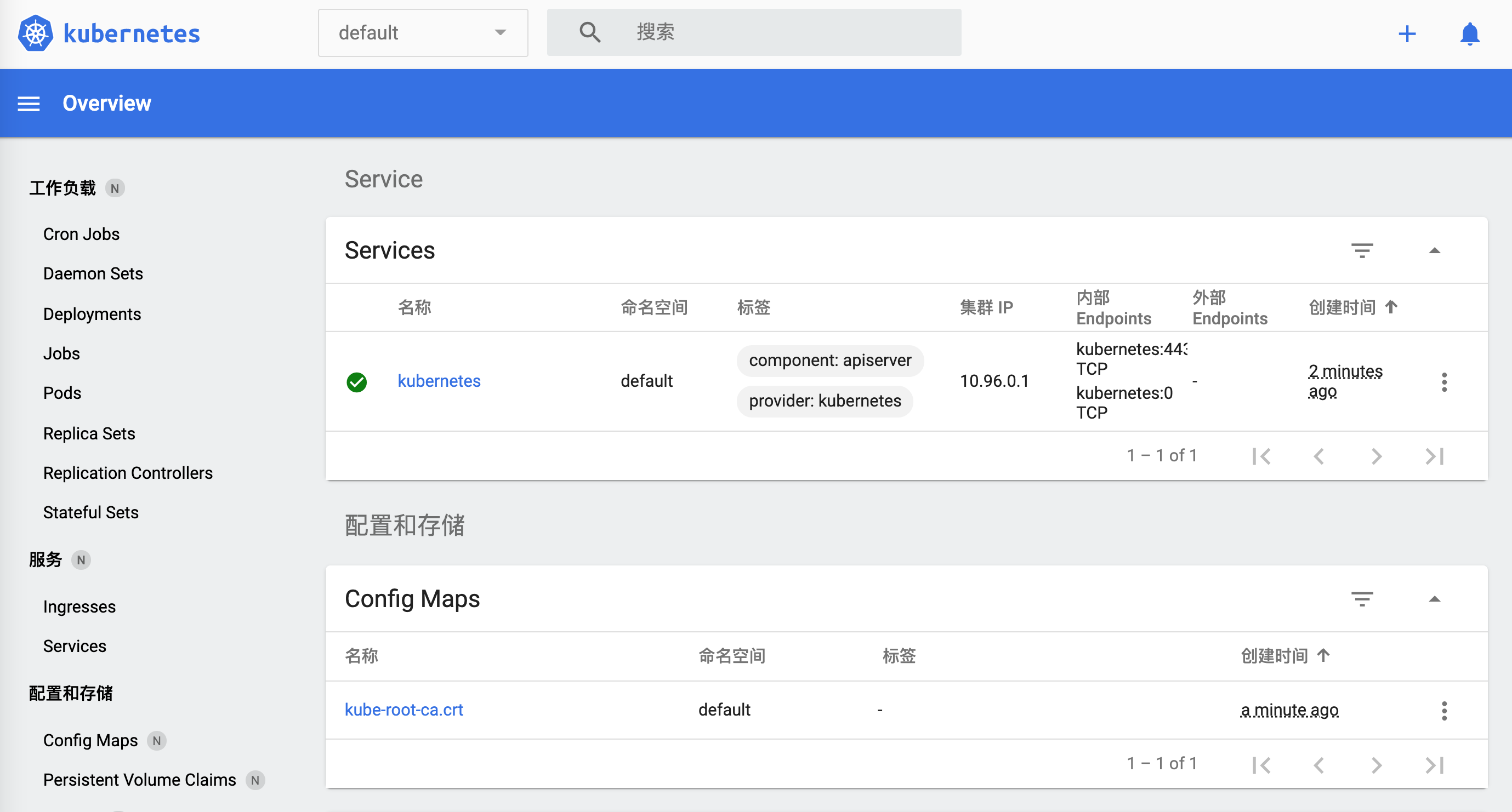
كيف يمكن إيقافها؟
$ minikube
minikube يقوم بتوفير وإدارة مجموعات Kubernetes المحلية المُحسّنة لسير عمل التطوير.
الأوامر الأساسية: start بدء مجموعة Kubernetes محلية status الحصول على حالة مجموعة Kubernetes محلية stop إيقاف مجموعة Kubernetes محلية قيد التشغيل delete حذف مجموعة Kubernetes محلية dashboard الوصول إلى لوحة تحكم Kubernetes التي تعمل داخل مجموعة minikube pause إيقاف Kubernetes مؤقتًا unpause استئناف Kubernetes بعد الإيقاف المؤقت
أوامر الصور: docker-env تهيئة البيئة لاستخدام خادم Docker الخاص بـ minikube podman-env تهيئة البيئة لاستخدام خدمة Podman الخاصة بـ minikube cache إضافة، حذف، أو دفع صورة محلية إلى minikube
أوامر التكوين والإدارة: addons تمكين أو تعطيل إضافة minikube config تعديل قيم التكوين الدائمة profile الحصول على أو عرض الملفات الشخصية الحالية (التجمعات) update-context تحديث kubeconfig في حالة تغيير عنوان IP أو المنفذ
أوامر الشبكات والاتصال: service يُرجع عنوان URL للاتصال بخدمة tunnel الاتصال بخدمات LoadBalancer
الأوامر المتقدمة: mount يقوم بتثبيت الدليل المحدد في minikube ssh تسجيل الدخول إلى بيئة minikube (لأغراض التصحيح) kubectl تشغيل إصدار kubectl الذي يتطابق مع إصدار الكتلة node إضافة أو إزالة أو عرض العقد الإضافية
أوامر استكشاف الأخطاء وإصلاحها: ssh-key استرجاع مسار مفتاح هوية SSH للعقدة المحددة ssh-host استرجاع مفتاح مضيف SSH للعقدة المحددة ip استرجاع عنوان IP للعقدة المحددة logs إرجاع السجلات لتصحيح مجموعة Kubernetes المحلية update-check طباعة رقم الإصدار الحالي والأحدث version طباعة إصدار minikube
الأوامر الأخرى: completion إنشاء إكمال الأوامر لـ shell
استخدم “minikube
يبدو أنه `minikube stop`.
بالعودة إلى `kubernetes`، الآن يعمل بشكل صحيح.
```shell
$ kubectl cluster-info
لوحة تحكم Kubernetes تعمل على https://192.168.99.100:8443
KubeDNS تعمل على https://192.168.99.100:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
لمزيد من تصحيح الأخطاء وتشخيص مشاكل الكتلة (cluster)، استخدم الأمر التالي:
kubectl cluster-info dump
عندما نفتح الرابط https://192.168.99.100:8443، يعرض المتصفح:
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "ممنوع: المستخدم \"system:anonymous\" لا يمكنه الوصول إلى المسار \"/\"",
"reason": "Forbidden",
"details": {
},
"code": 403
}
قم بزيارة الرابط التالي: https://192.168.99.100:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "الخدمات \"kube-dns:dns\" ممنوعة: المستخدم \"system:anonymous\" لا يمكنه الحصول على المورد \"services/proxy\" في مجموعة API \"\" في مساحة الاسم \"kube-system\"",
"reason": "ممنوع",
"details": {
"name": "kube-dns:dns",
"kind": "services"
},
"code": 403
}
جرب الإعدادات التي قمنا بها للتو.
$ kubectl apply -f simple_deployment.yaml
deployment.apps/nginx-deployment created
هناك بعض المشاكل. ومع ذلك، حتى الآن، قمنا بتشغيل kubernetes. دعونا ننهيها هنا ونلعب بها لاحقًا.
$ minikube stop
✋ إيقاف العقدة "minikube" ...
🛑 تم إيقاف عقدة واحدة.
تحقق مما إذا انتهى.
w$ minikube dashboard
🤷 يجب أن تكون عقدة لوحة التحكم قيد التشغيل لهذا الأمر
👉 لبدء الكتلة، قم بتشغيل: "minikube start"
Docker
Docker هو أيضًا منصة حاويات تساعد في تسريع إنشاء ومشاركة وتشغيل التطبيقات الحديثة. يمكنك تنزيل التطبيق من الموقع الرسمي.
استخدام العميل كان بطيئًا بعض الشيء. دعنا نستخدم سطر الأوامر.
$ docker
الاستخدام: docker [OPTIONS] COMMAND
بيئة تشغيل ذاتية الاكتفاء للحاويات
الخيارات: –config string موقع ملفات تكوين العميل (الافتراضي “/Users/lzw/.docker”) -c, –context string اسم السياق الذي سيتم استخدامه للاتصال بالخادم (يتجاوز متغير البيئة DOCKER_HOST والسياق الافتراضي المحدد باستخدام “docker context use”) -D, –debug تمكين وضع التصحيح -H, –host list مقبس (مقابس) الخادم للاتصال به -l, –log-level string تعيين مستوى التسجيل (“debug”|”info”|”warn”|”error”|”fatal”) (الافتراضي “info”) –tls استخدام TLS; يتم تضمينه تلقائيًا مع –tlsverify –tlscacert string الثقة في الشهادات الموقعة فقط من قبل هذا المركز (الافتراضي “/Users/lzw/.docker/ca.pem”) –tlscert string مسار ملف شهادة TLS (الافتراضي “/Users/lzw/.docker/cert.pem”) –tlskey string مسار ملف مفتاح TLS (الافتراضي “/Users/lzw/.docker/key.pem”) –tlsverify استخدام TLS والتحقق من الطرف البعيد -v, –version طباعة معلومات الإصدار والخروج
أوامر الإدارة: app* Docker App (Docker Inc., v0.9.1-beta3) builder إدارة عمليات البناء buildx* البناء باستخدام BuildKit (Docker Inc., v0.5.1-docker) config إدارة إعدادات Docker container إدارة الحاويات context إدارة السياقات image إدارة الصور manifest إدارة قوائم وصور Docker network إدارة الشبكات node إدارة عقد Swarm plugin إدارة الإضافات scan* Docker Scan (Docker Inc., v0.5.0) secret إدارة الأسرار في Docker service إدارة الخدمات stack إدارة مجموعات Docker swarm إدارة Swarm system إدارة Docker trust إدارة الثقة في صور Docker volume إدارة الأحجام
الأوامر: attach ربط المدخلات والمخرجات وتيارات الأخطاء المحلية بجريان حاوية قيد التشغيل build بناء صورة من Dockerfile commit إنشاء صورة جديدة من تغييرات الحاوية cp نسخ الملفات/المجلدات بين الحاوية ونظام الملفات المحلي create إنشاء حاوية جديدة diff فحص التغييرات على الملفات أو الدلائل في نظام ملفات الحاوية events الحصول على الأحداث في الوقت الفعلي من الخادم exec تنفيذ أمر في حاوية قيد التشغيل export تصدير نظام ملفات الحاوية كأرشيف tar history عرض تاريخ الصورة images عرض قائمة الصور import استيراد محتويات من أرشيف tarball لإنشاء صورة نظام ملفات info عرض معلومات النظام على نطاق واسع inspect إرجاع معلومات منخفضة المستوى عن كائنات Docker kill إنهاء تشغيل واحدة أو أكثر من الحاويات الجارية load تحميل صورة من أرشيف tar أو STDIN login تسجيل الدخول إلى سجل Docker logout تسجيل الخروج من سجل Docker logs جلب سجلات الحاوية pause إيقاف جميع العمليات داخل واحدة أو أكثر من الحاويات مؤقتًا port عرض تعيينات المنافذ أو تعيين محدد للحاوية ps عرض قائمة الحاويات pull سحب صورة أو مستودع من السجل push دفع صورة أو مستودع إلى السجل rename إعادة تسمية حاوية restart إعادة تشغيل واحدة أو أكثر من الحاويات rm إزالة واحدة أو أكثر من الحاويات rmi إزالة واحدة أو أكثر من الصور run تنفيذ أمر في حاوية جديدة save حفظ واحدة أو أكثر من الصور في أرشيف tar (يتم إرسالها إلى STDOUT افتراضيًا) search البحث في Docker Hub عن الصور start بدء تشغيل واحدة أو أكثر من الحاويات المتوقفة stats عرض بث مباشر لإحصائيات استخدام موارد الحاوية (الحاويات) stop إيقاف تشغيل واحدة أو أكثر من الحاويات الجارية tag إنشاء علامة TARGET_IMAGE تشير إلى SOURCE_IMAGE top عرض العمليات الجارية في الحاوية unpause استئناف جميع العمليات داخل واحدة أو أكثر من الحاويات update تحديث تكوين واحدة أو أكثر من الحاويات version عرض معلومات إصدار Docker wait الانتظار حتى تتوقف واحدة أو أكثر من الحاويات، ثم طباعة أكواد الخروج الخاصة بها
قم بتشغيل الأمر ‘docker COMMAND –help’ للحصول على مزيد من المعلومات حول أمر معين.
للحصول على المزيد من المساعدة حول Docker، يمكنك الاطلاع على أدلتنا على الرابط التالي: https://docs.docker.com/go/guides/
جرب اتباع البرنامج التعليمي.
```shell
$ docker run -d -p 80:80 docker/getting-started
Unable to find image 'docker/getting-started:latest' locally
latest: Pulling from docker/getting-started
aad63a933944: تم سحبها بالكامل
b14da7a62044: تم سحبها بالكامل
343784d40d66: تم سحبها بالكامل
6f617e610986: تم سحبها بالكامل
Digest: sha256:d2c4fb0641519ea208f20ab03dc40ec2a5a53fdfbccca90bef14f870158ed577
Status: تم تنزيل صورة أحدث لـ docker/getting-started:latest
815f13fc8f99f6185257980f74c349e182842ca572fe60ff62cbb15641199eaf
docker: استجابة خطأ من daemon: المنافذ غير متاحة: الاستماع إلى tcp 0.0.0.0:80: bind: العنوان قيد الاستخدام بالفعل.
غيّر المنفذ.
$ docker run -d -p 8080:80 docker/getting-started
45bb95fa1ae80adc05cc498a1f4f339c45c51f7a8ae1be17f5b704853a5513a5
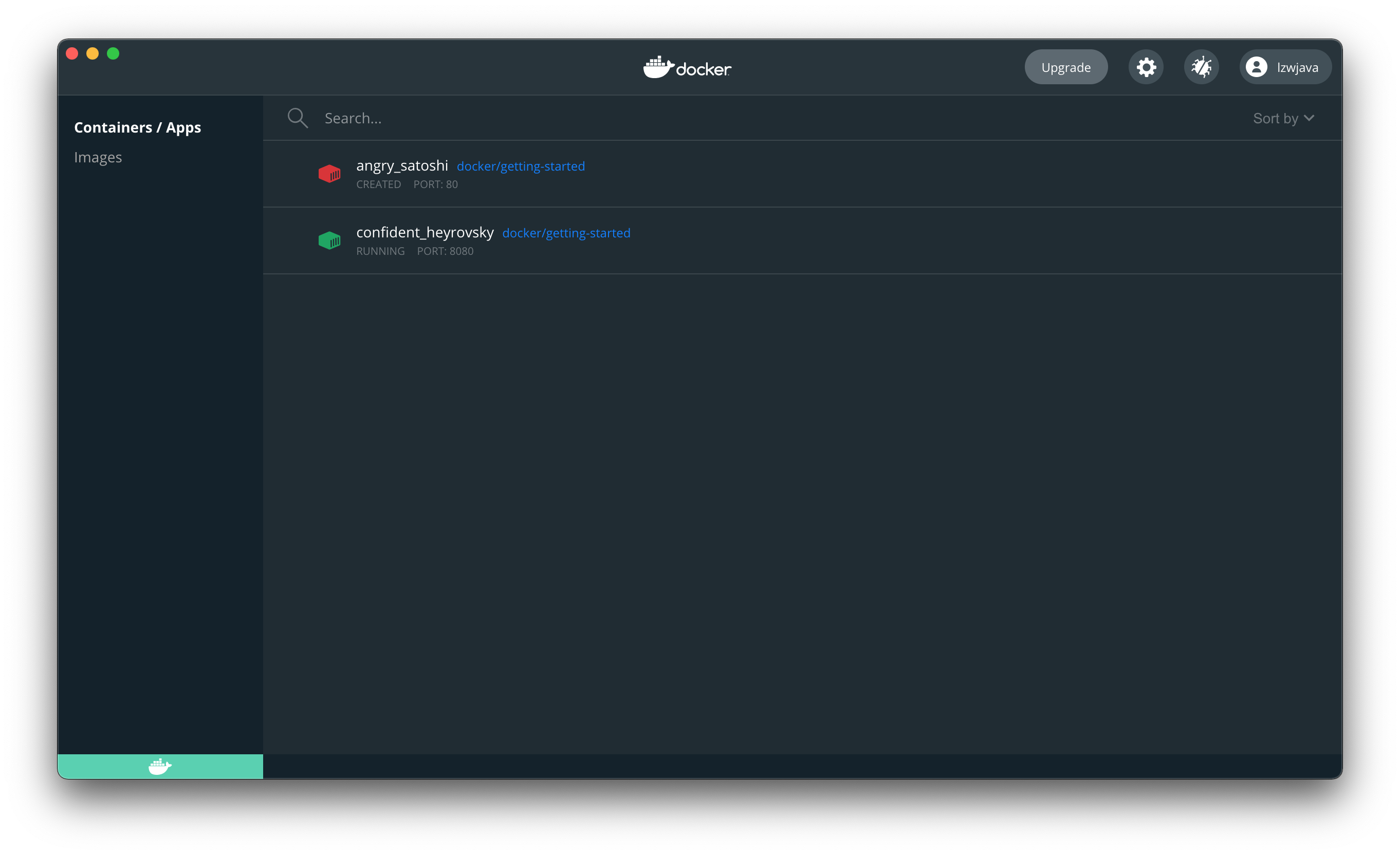
فتح المتصفح يدل على أننا نجحنا في تشغيل docker.
أوقف الحاوية. استخدم ID الذي تم إرجاعه مسبقًا.
$ docker stop 45bb95fa1ae80adc05cc498a1f4f339c45c51f7a8ae1be17f5b704853a5513a5
45bb95fa1ae80adc05cc498a1f4f339c45c51f7a8ae1be17f5b704853a5513a5
في هذه اللحظة لم يعد بالإمكان فتح الموقع.
هذا يشير إلى أن docker يشبه الآلة الافتراضية.
Flink
افتح الموقع الرسمي.
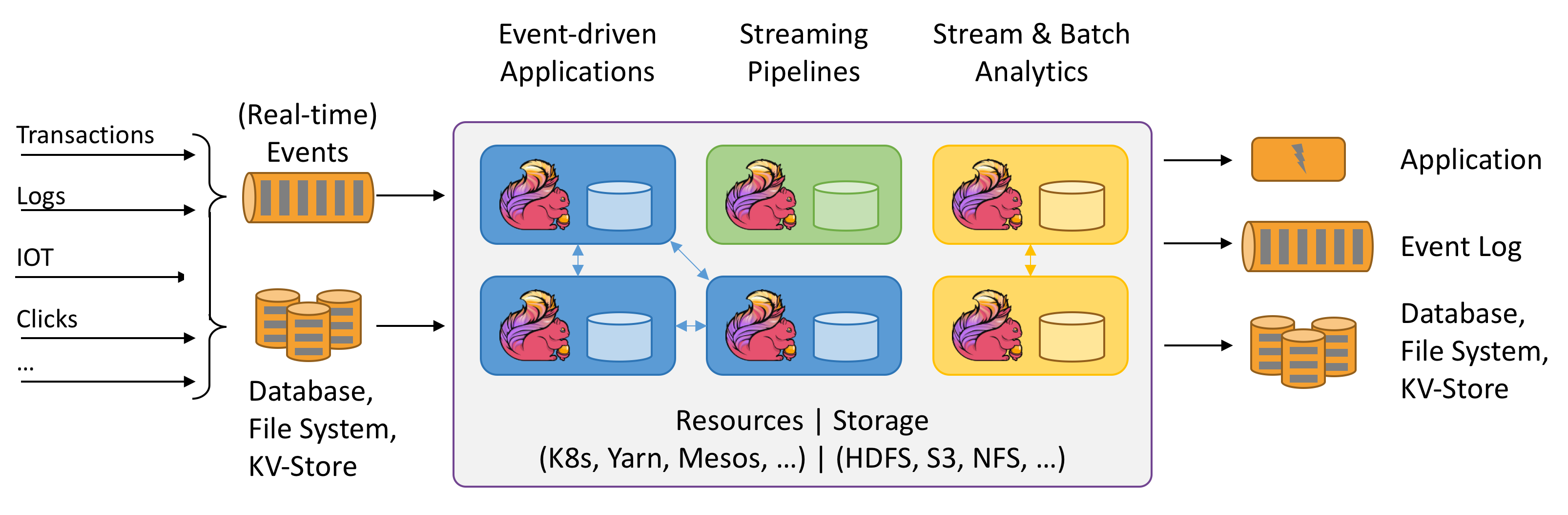
Flink يتحدث عن الحوسبة ذات الحالة (Stateful) لتدفقات البيانات. ماذا تعني Stateful؟ لا أفهمها بعد. الصورة أعلاه مثيرة للاهتمام. دعونا نجربها.
يقال أنه يحتاج إلى بيئة Java.
$ java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
قم بتنزيل أحدث إصدار من الموقع الرسمي flink-1.12.2-bin-scala_2.11.tar.
$ ./bin/start-cluster.sh
بدء تشغيل الكتلة.
بدء تشغيل daemon standalonesession على المضيف lzwjava.
بدء تشغيل daemon taskexecutor على المضيف lzwjava.
$ ./bin/flink run examples/streaming/WordCount.jar
تنفيذ مثال WordCount مع مجموعة بيانات الإدخال الافتراضية.
استخدم --input لتحديد ملف الإدخال.
يتم طباعة النتيجة إلى stdout. استخدم --output لتحديد مسار الإخراج.
تم تقديم المهمة مع JobID 60f37647c20c2a6654359bd34edab807
انتهى تنفيذ البرنامج
المهمة ذات JobID 60f37647c20c2a6654359bd34edab807 قد انتهت.
وقت تشغيل المهمة: 757 مللي ثانية
$ tail log/flink-*-taskexecutor-*.out
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)
$ ./bin/stop-cluster.sh
إيقاف برنامج taskexecutor الخفي (معرف العملية: 41812) على المضيف lzwjava.
نعم، لقد نجحت في البدء. يمكن ملاحظة أن هذا يشبه إلى حد كبير Spark.
كايلين
انتقل إلى الموقع الرسمي.
Apache Kylin™ هو مستودع بيانات تحليلي موزع مفتوح المصدر مخصص للبيانات الضخمة؛ تم تصميمه لتوفير قدرة OLAP (معالجة تحليلية عبر الإنترنت) في عصر البيانات الضخمة. من خلال إعادة ابتكار تقنية المكعب متعدد الأبعاد والحساب المسبق على Hadoop وSpark، يتمكن Kylin من تحقيق سرعة استعلام شبه ثابتة بغض النظر عن حجم البيانات المتزايد باستمرار. بتقليل زمن الاستجابة من دقائق إلى أجزاء من الثانية، يعيد Kylin التحليلات عبر الإنترنت إلى عالم البيانات الضخمة.
Apache Kylin™ يتيح لك استعلام مليارات الصفوف بزمن استجابة أقل من ثانية في 3 خطوات.
- تحديد مخطط نجمي أو ثلجي (Star/Snowflake Schema) على Hadoop.
- بناء مكعب (Cube) من الجداول المحددة.
- الاستعلام باستخدام ANSI-SQL والحصول على النتائج في أقل من ثانية، عبر ODBC، JDBC أو واجهة برمجة التطبيقات RESTful.
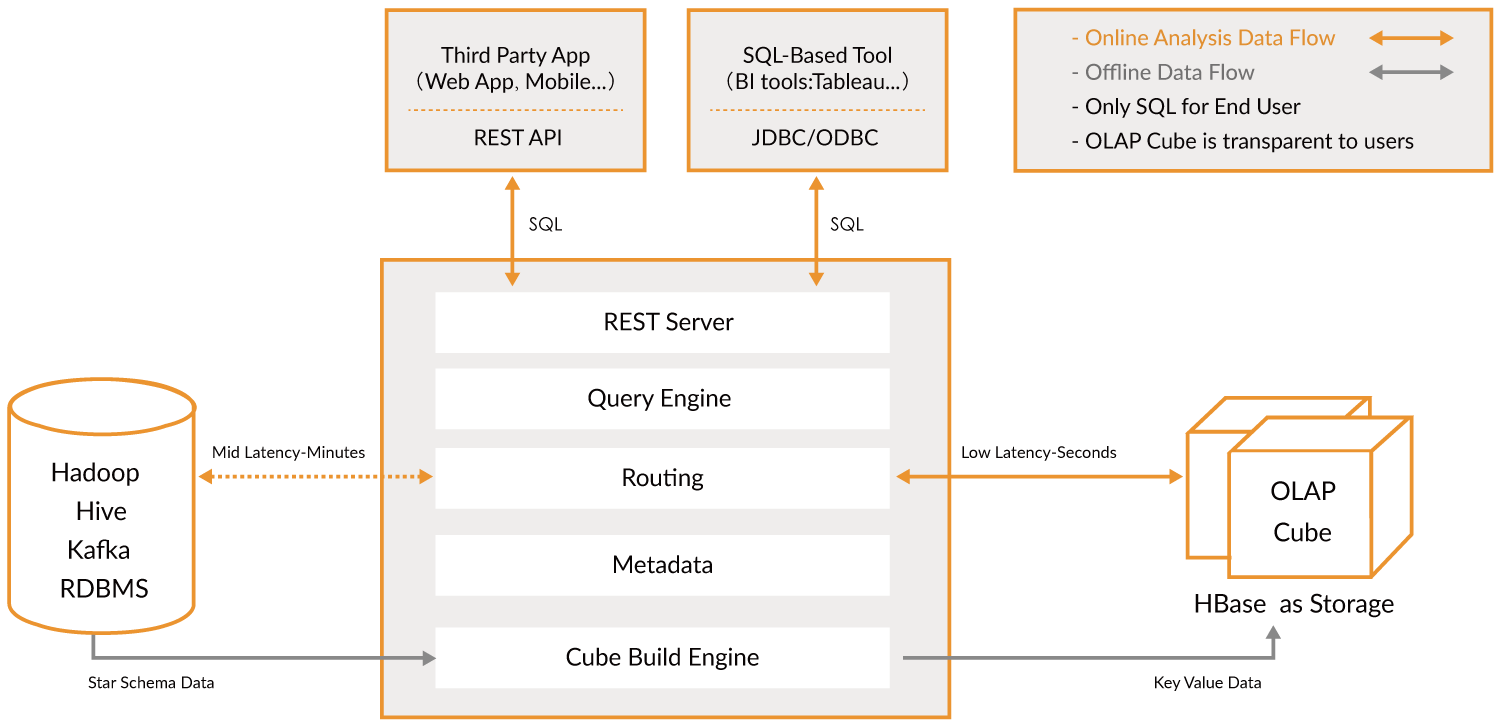
بشكل عام، هو طبقة لتحليل البيانات الضخمة. يمكن استخدامه للبحث بسرعة كبيرة. يعمل كجسر.
للأسف، يمكن حاليًا استخدامه فقط في بيئة Linux. سأعود لاحقًا للتعامل معه.
MongoDB
هذه أيضًا قاعدة بيانات. جرب تثبيتها.
$ brew tap mongodb/brew
==> تثبيت mongodb/brew
جارٍ الاستنساخ إلى '/usr/local/Homebrew/Library/Taps/mongodb/homebrew-brew'...
remote: تعداد الكائنات: 63، تم.
remote: عد الكائنات: 100% (63/63)، تم.
remote: ضغط الكائنات: 100% (62/62)، تم.
remote: إجمالي 566 (دلتا 21)، تم إعادة استخدام 6 (دلتا 1)، تم إعادة استخدام الحزمة 503
جارٍ استقبال الكائنات: 100% (566/566)، 121.78 كيلوبايت | 335.00 كيلوبايت/ثانية، تم.
جارٍ حل الدلتا: 100% (259/259)، تم.
تم تثبيت 11 صيغة (39 ملفًا، 196.2 كيلوبايت).
$ brew install mongodb-community@4.4
==> تثبيت mongodb-community من mongodb/brew
==> تنزيل https://fastdl.mongodb.org/tools/db/mongodb-database-tools-macos-x86_64-100.3.0.zip
######################################################################## 100.0%
==> تنزيل https://fastdl.mongodb.org/osx/mongodb-macos-x86_64-4.4.3.tgz
######################################################################## 100.0%
==> تثبيت التبعيات لـ mongodb/brew/mongodb-community: mongodb-database-tools
==> تثبيت تبعية mongodb/brew/mongodb-community: mongodb-database-tools
خطأ: خطوة `brew link` لم تكتمل بنجاح
تم بناء الصيغة، ولكن لم يتم إنشاء رابط رمزي إلى /usr/local
تعذر إنشاء رابط رمزي لـ bin/bsondump
الهدف /usr/local/bin/bsondump
هو رابط رمزي يتبع لـ mongodb. يمكنك إلغاء ربطه:
brew unlink mongodb
لإجبار الربط واستبدال جميع الملفات المتضاربة: brew link –overwrite mongodb-database-tools
لإدراج جميع الملفات التي سيتم حذفها:
brew link --overwrite --dry-run mongodb-database-tools
الملفات التي قد تكون متضاربة هي:
/usr/local/bin/bsondump -> /usr/local/Cellar/mongodb/3.0.7/bin/bsondump
/usr/local/bin/mongodump -> /usr/local/Cellar/mongodb/3.0.7/bin/mongodump
/usr/local/bin/mongoexport -> /usr/local/Cellar/mongodb/3.0.7/bin/mongoexport
/usr/local/bin/mongofiles -> /usr/local/Cellar/mongodb/3.0.7/bin/mongofiles
/usr/local/bin/mongoimport -> /usr/local/Cellar/mongodb/3.0.7/bin/mongoimport
/usr/local/bin/mongorestore -> /usr/local/Cellar/mongodb/3.0.7/bin/mongorestore
/usr/local/bin/mongostat -> /usr/local/Cellar/mongodb/3.0.7/bin/mongostat
/usr/local/bin/mongotop -> /usr/local/Cellar/mongodb/3.0.7/bin/mongotop
==> الملخص
🍺 /usr/local/Cellar/mongodb-database-tools/100.3.0: 13 ملفًا، 154 ميجابايت، تم بناؤه في 11 ثانية
==> تثبيت mongodb/brew/mongodb-community
خطأ: خطوة brew link لم تكتمل بنجاح
تم بناء الصيغة، ولكن لم يتم إنشاء رابط رمزي لها في /usr/local
تعذر إنشاء رابط رمزي لـ bin/mongo
الهدف /usr/local/bin/mongo
هو رابط رمزي يتبع لـ mongodb. يمكنك إلغاء الربط:
brew unlink mongodb
لإجبار الربط واستبدال جميع الملفات المتضاربة: brew link –overwrite mongodb-community
لإدراج جميع الملفات التي سيتم حذفها:
brew link --overwrite --dry-run mongodb-community
الملفات التي قد تكون متضاربة هي: /usr/local/bin/mongo -> /usr/local/Cellar/mongodb/3.0.7/bin/mongo /usr/local/bin/mongod -> /usr/local/Cellar/mongodb/3.0.7/bin/mongod /usr/local/bin/mongos -> /usr/local/Cellar/mongodb/3.0.7/bin/mongos ==> ملاحظات لبدء mongodb/brew/mongodb-community الآن وإعادة التشغيل عند تسجيل الدخول باستخدام launchd: brew services start mongodb/brew/mongodb-community أو، إذا كنت لا تريد/تحتاج إلى خدمة خلفية، يمكنك فقط تشغيل: mongod –config /usr/local/etc/mongod.conf ==> ملخص 🍺 /usr/local/Cellar/mongodb-community/4.4.3: 11 ملفًا، 156.8 ميجابايت، تم بناؤها في 10 ثوانٍ ==> ملاحظات ==> mongodb-community لبدء mongodb/brew/mongodb-community الآن وإعادة التشغيل عند تسجيل الدخول باستخدام launchd: brew services start mongodb/brew/mongodb-community أو، إذا كنت لا تريد/تحتاج إلى خدمة خلفية، يمكنك فقط تشغيل: mongod –config /usr/local/etc/mongod.conf
في السابق قمت بتثبيت إصدار قديم. سأقوم بإزالة الروابط التالية.
```shell
$ brew unlink mongodb
إلغاء الربط /usr/local/Cellar/mongodb/3.0.7... تمت إزالة 11 رابطًا رمزيًا
$ mongod --version
إصدار قاعدة البيانات v4.4.3
معلومات البناء: {
"version": "4.4.3",
"gitVersion": "913d6b62acfbb344dde1b116f4161360acd8fd13",
"modules": [],
"allocator": "system",
"environment": {
"distarch": "x86_64",
"target_arch": "x86_64"
}
}
بعد ذلك، قم بتشغيل mongod لبدء خادم قاعدة بيانات mongo. ومع ذلك، عند التشغيل الأول، تم الإبلاغ بأن /data/db غير موجود. قمنا بإنشاء دليل، ~/mongodb، هنا لحفظ ملفات قاعدة البيانات.
$ mongod --dbpath ~/mongodb
الإخراج هو:
{"t":{"$date":"2021-03-11T18:17:32.838+08:00"},"s":"I", "c":"CONTROL", "id":23285, "ctx":"main","msg":"تم تعطيل TLS 1.0 تلقائيًا، لتمكين TLS 1.0 قسرًا حدد --sslDisabledProtocols 'none'"}
{"t":{"$date":"2021-03-11T18:17:32.842+08:00"},"s":"W", "c":"ASIO", "id":22601, "ctx":"main","msg":"لم يتم تكوين TransportLayer أثناء بدء تشغيل NetworkInterface"}
{"t":{"$date":"2021-03-11T18:17:32.842+08:00"},"s":"I", "c":"NETWORK", "id":4648602, "ctx":"main","msg":"تم استخدام TCP FastOpen ضمنيًا."}
{"t":{"$date":"2021-03-11T18:17:32.842+08:00"},"s":"I", "c":"STORAGE", "id":4615611, "ctx":"initandlisten","msg":"MongoDB يبدأ التشغيل","attr":{"pid":46256,"port":27017,"dbPath":"/Users/lzw/mongodb","architecture":"64-bit","host":"lzwjava"}}
{"t":{"$date":"2021-03-11T18:17:32.842+08:00"},"s":"I", "c":"CONTROL", "id":23403, "ctx":"initandlisten","msg":"معلومات البناء","attr":{"buildInfo":{"version":"4.4.3","gitVersion":"913d6b62acfbb344dde1b116f4161360acd8fd13","modules":[],"allocator":"system","environment":{"distarch":"x86_64","target_arch":"x86_64"}}}}
{"t":{"$date":"2021-03-11T18:17:32.843+08:00"},"s":"I", "c":"CONTROL", "id":51765, "ctx":"initandlisten","msg":"نظام التشغيل","attr":{"os":{"name":"Mac OS X","version":"20.3.0"}}}
...
يمكن ملاحظة أن جميعها بتنسيق JSON. MongoDB يحفظ جميع ملفات البيانات بتنسيق JSON. بعد ذلك، افتح علامة تبويب طرفية أخرى.
$ mongo
إصدار shell MongoDB: v4.4.3
الاتصال بـ: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
الجلسة الضمنية: session { "id" : UUID("4f55c561-70d3-4289-938d-4b90a284891f") }
إصدار خادم MongoDB: 4.4.3
---
قام الخادم بإنشاء هذه التحذيرات عند بدء التشغيل:
2021-03-11T18:17:33.743+08:00: التحكم في الوصول غير مفعل لقاعدة البيانات. الوصول للقراءة والكتابة للبيانات والإعدادات غير مقيد
2021-03-11T18:17:33.743+08:00: هذا الخادم مرتبط بـ localhost. الأنظمة البعيدة لن تكون قادرة على الاتصال بهذا الخادم. ابدأ الخادم باستخدام --bind_ip <عنوان> لتحديد عناوين IP التي يجب أن يستجيب منها، أو باستخدام --bind_ip_all للربط بجميع الواجهات. إذا كان هذا السلوك مرغوبًا، ابدأ الخادم باستخدام --bind_ip 127.0.0.1 لتعطيل هذا التحذير
2021-03-11T18:17:33.743+08:00: حدود البرامج الناعمة منخفضة جدًا
2021-03-11T18:17:33.743+08:00: القيمة الحالية: 4864
2021-03-11T18:17:33.743+08:00: الحد الأدنى الموصى به: 64000
---
---
قم بتمكين خدمة المراقبة السحابية المجانية من MongoDB، والتي ستستقبل وتعرض
مقاييس حول نشرك (استخدام القرص، CPU، إحصائيات العمليات، إلخ).
ستكون بيانات المراقبة متاحة على موقع MongoDB بعنوان URL فريد يمكنك الوصول إليه
وأي شخص تشارك معه الرابط. قد تستخدم MongoDB هذه المعلومات لإجراء تحسينات على المنتج
ولاقتراح منتجات MongoDB وخيارات النشر المناسبة لك.
لتمكين المراقبة المجانية، قم بتنفيذ الأمر التالي:
```javascript
db.enableFreeMonitoring()
لتعطيل هذا التذكير بشكل دائم، قم بتنفيذ الأمر التالي:
db.disableFreeMonitoring()
بعد ذلك، يمكنك محاولة إدخال البيانات والاستعلام عنها.
> db.inventory.insertOne(
... { item: "canvas", qty: 100, tags: ["cotton"], size: { h: 28, w: 35.5, uom: "cm" } }
... )
{
"acknowledged" : true,
"insertedId" : ObjectId("6049ef91b653541cf355facb")
}
>
> db.inventory.find()
{ "_id" : ObjectId("6049ef91b653541cf355facb"), "item" : "canvas", "qty" : 100, "tags" : [ "cotton" ], "size" : { "h" : 28, "w" : 35.5, "uom" : "cm" } }
الختام
لنكتفي بهذا الآن. سنتعامل مع أدوات أخرى لاحقًا. ما الهدف من كل هذا؟ ربما يكون الحصول على فكرة عامة أولاً. البداية دائمًا صعبة، وقد قمنا بتجربة كل هذه الأشياء دفعة واحدة. هذا يعطينا ثقة، وبعد ذلك، سنقوم بتجربة المزيد من هذه البرامج.
التمرين
- يجب على الطلاب استكشاف الموضوع بشكل مشابه لما ورد أعلاه.