क्लाउड कंप्यूटिंग और बिग डेटा का परिचय | मूल, AI द्वारा अनुवादित
इस पाठ में निम्नलिखित विषय शामिल हैं:
- स्पार्क
- हडूप
- कुबेरनेट्स
- डॉकर
- फ्लिंक
- मोंगोडीबी
क्लाउड कंप्यूटिंग की बात करें तो ऐसा लगता है कि यह बहुत सारे टूल्स के बिना अधूरी है, जैसे Hadoop, Hive, Hbase, ZooKeeper, Docker, Kubernetes, Spark, Kafka, MongoDB, Flink, Druid, Presto, Kylin, Elastic Search। क्या आपने इन सभी के बारे में सुना है? इनमें से कुछ टूल्स मैंने बिग डेटा इंजीनियर और डिस्ट्रिब्यूटेड बैकएंड इंजीनियर की जॉब डिस्क्रिप्शन में देखे हैं। ये सभी उच्च वेतन वाली पद हैं। हम इन सभी को इंस्टॉल करने की कोशिश करेंगे और उन्हें थोड़ा सा समझने की कोशिश करेंगे।
Spark का प्रारंभिक परिचय
आधिकारिक वेबसाइट के अनुसार, Spark बड़े पैमाने पर डेटा के विश्लेषण के लिए एक इंजन है। Spark एक लाइब्रेरी का सेट है। यह Redis की तरह सर्वर और क्लाइंट में विभाजित नहीं होता है। Spark केवल क्लाइंट साइड पर उपयोग किया जाता है। आधिकारिक वेबसाइट से नवीनतम संस्करण डाउनलोड किया गया है, spark-3.1.1-bin-hadoop3.2.tar।
$ tree . -L 1
.
├── LICENSE
├── NOTICE
├── R
├── README.md
├── RELEASE
├── bin
├── conf
├── data
├── examples
├── jars
├── kubernetes
├── licenses
├── python
├── sbin
└── yarn
11 डायरेक्टरीज़, 4 फ़ाइलें
यह विभिन्न भाषाओं में लिखे गए कुछ विश्लेषण पुस्तकालयों (libraries) की तरह लगता है।
साथ ही, आधिकारिक वेबसाइट के अनुसार, आप Python पर सीधे निर्भरता पुस्तकालय (dependency library) स्थापित कर सकते हैं। `pip install pyspark`
```shell
$ pip install pyspark
Collecting pyspark
Downloading pyspark-3.1.1.tar.gz (212.3 MB)
|████████████████████████████████| 212.3 MB 14 kB/s
Collecting py4j==0.10.9
Downloading py4j-0.10.9-py2.py3-none-any.whl (198 kB)
|████████████████████████████████| 198 kB 145 kB/s
Building wheels for collected packages: pyspark
Building wheel for pyspark (setup.py) ... done
Created wheel for pyspark: filename=pyspark-3.1.1-py2.py3-none-any.whl size=212767604 sha256=0b8079e82f3a5bcadad99179902d8c8ff9f8eccad928a469c11b97abdc960b72
Stored in directory: /Users/lzw/Library/Caches/pip/wheels/23/bf/e9/9f3500437422e2ab82246f25a51ee480a44d4efc6c27e50d33
Successfully built pyspark
Installing collected packages: py4j, pyspark
Successfully installed py4j-0.10.9 pyspark-3.1.1
इंस्टॉल हो गया है।
यह वेबसाइट पर कुछ उदाहरण देख रहा है।
./bin/run-example SparkPi 10
ओह, मैंने अभी डाउनलोड किए गए इंस्टॉलेशन पैकेज में मौजूद प्रोग्राम को चलाने की कोशिश की। लेकिन एक त्रुटि हुई।
$ ./bin/run-example SparkPi 10
21/03/11 00:06:15 WARN NativeCodeLoader: आपके प्लेटफॉर्म के लिए नेटिव-हैडूप लाइब्रेरी लोड करने में असमर्थ... जहां लागू हो, बिल्ट-इन जावा क्लासेस का उपयोग किया जा रहा है
21/03/11 00:06:16 INFO ResourceUtils: spark.driver के लिए कोई कस्टम संसाधन कॉन्फ़िगर नहीं किया गया है।
21/03/11 00:06:16 WARN Utils: सेवा 'sparkDriver' एक यादृच्छिक मुक्त पोर्ट पर बाइंड नहीं कर सकी। आप जांच सकते हैं कि क्या एक उपयुक्त बाइंडिंग एड्रेस कॉन्फ़िगर किया गया है।
Spark एक तेज़ और सामान्य प्रसंस्करण इंजन है जो Hadoop डेटा के साथ संगत है। यह YARN या Spark के स्टैंडअलोन मोड के माध्यम से Hadoop क्लस्टर में चल सकता है, और यह HDFS, HBase, Cassandra, Hive, और किसी भी Hadoop InputFormat में डेटा को प्रोसेस कर सकता है। इसे बैच प्रोसेसिंग (MapReduce के समान) और नए वर्कलोड जैसे स्ट्रीमिंग, इंटरएक्टिव क्वेरीज़, और मशीन लर्निंग को संचालित करने के लिए डिज़ाइन किया गया है।
hadoop कई बार आया है। spark depends hadoop को Google करने के बाद, मुझे यह वाक्य मिला। ऐसा लगता है कि यह Hadoop फॉर्मेट के डेटा पर निर्भर करता है। आइए पहले Hadoop पर शोध करें।
Hadoop
आधिकारिक वेबसाइट को संक्षेप में देखने के बाद, इसे इंस्टॉल करने का प्रयास करते हैं।
brew install hadoop
इंस्टॉलेशन के दौरान, आइए इसके बारे में थोड़ा जानें।
Apache Hadoop सॉफ्टवेयर लाइब्रेरी एक ऐसा फ्रेमवर्क है जो सरल प्रोग्रामिंग मॉडल का उपयोग करके कंप्यूटरों के क्लस्टर पर बड़े डेटा सेट के वितरित प्रसंस्करण की अनुमति देता है। यह सिंगल सर्वर से हजारों मशीनों तक स्केल करने के लिए डिज़ाइन किया गया है, जहां प्रत्येक मशीन स्थानीय गणना और भंडारण प्रदान करती है। हार्डवेयर पर निर्भर होने के बजाय उच्च उपलब्धता प्रदान करने के लिए, यह लाइब्रेरी स्वयं एप्लिकेशन लेयर पर विफलताओं का पता लगाने और उन्हें संभालने के लिए डिज़ाइन की गई है, इस प्रकार कंप्यूटरों के एक क्लस्टर के ऊपर एक अत्यधिक उपलब्ध सेवा प्रदान करती है, जहां प्रत्येक मशीन विफलताओं के प्रति संवेदनशील हो सकती है।
Hadoop एक ऐसा फ्रेमवर्क है जो वितरित डेटासेट को प्रोसेस करने के लिए बनाया गया है। ये डेटासेट कई कंप्यूटरों पर वितरित हो सकते हैं। इसे एक बहुत ही सरल प्रोग्रामिंग मॉडल का उपयोग करके प्रोसेस किया जाता है। इसे एकल सर्वर से हजारों मशीनों तक स्केल करने के लिए डिज़ाइन किया गया है। हार्डवेयर की उच्च उपलब्धता पर निर्भर होने के बजाय, यह लाइब्रेरी एप्लिकेशन लेयर पर ही त्रुटियों की जांच और उन्हें संभालने के लिए डिज़ाइन की गई है। इस तरह, उच्च उपलब्धता वाली सेवाओं को क्लस्टर में तैनात किया जा सकता है, भले ही क्लस्टर में शामिल हर कंप्यूटर विफल हो सकता हो।
$ brew install hadoop
त्रुटि:
homebrew-core एक उथला क्लोन है।
homebrew-cask एक उथला क्लोन है।
`brew update` करने के लिए, पहले निम्नलिखित कमांड चलाएं:
git -C /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core fetch --unshallow
git -C /usr/local/Homebrew/Library/Taps/homebrew/homebrew-cask fetch --unshallow
ये कमांड रिपॉजिटरीज़ के बड़े आकार के कारण चलने में कुछ मिनट ले सकती हैं।
GitHub के अनुरोध पर यह प्रतिबंध लगाया गया है क्योंकि उथले क्लोन को अपडेट करना Homebrew/homebrew-core और Homebrew/homebrew-cask के ट्री लेआउट और ट्रैफ़िक के कारण एक बहुत ही महंगा ऑपरेशन है। हम इसे आपके लिए स्वचालित रूप से नहीं करते हैं ताकि CI सिस्टम में बार-बार एक महंगे unshallow ऑपरेशन को करने से बचा जा सके (जिन्हें उथले क्लोन का उपयोग न करने के लिए ठीक किया जाना चाहिए)। असुविधा के लिए क्षमा करें!
==> Downloading https://homebrew.bintray.com/bottles/openjdk-15.0.1.big_sur.bottle.tar.gz
पहले से डाउनलोड किया गया: /Users/lzw/Library/Caches/Homebrew/downloads/d1e3ece4af1d225bc2607eaa4ce85a873d2c6d43757ae4415d195751bc431962--openjdk-15.0.1.big_sur.bottle.tar.gz
==> Downloading https://www.apache.org/dyn/closer.lua?path=hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
पहले से डाउनलोड किया गया: /Users/lzw/Library/Caches/Homebrew/downloads/764c6a0ea7352bb8bb505989feee1b36dc628c2dcd6b93fef1ca829d191b4e1e--hadoop-3.3.0.tar.gz
==> hadoop के लिए निर्भरताएँ स्थापित कर रहा है: openjdk
==> hadoop निर्भरता स्थापित कर रहा है: openjdk
==> openjdk-15.0.1.big_sur.bottle.tar.gz डाल रहा है
==> चेतावनी
सिस्टम Java रैपर्स को इस JDK को खोजने के लिए, इसे निम्नलिखित कमांड से सिमलिंक करें:
sudo ln -sfn /usr/local/opt/openjdk/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk.jdk
openjdk keg-only है, जिसका अर्थ है कि इसे /usr/local में symlink नहीं किया गया है,
क्योंकि यह macOS के java wrapper को छिपाता है।
यदि आपको अपने PATH में openjdk को पहले रखने की आवश्यकता है, तो निम्नलिखित कमांड चलाएँ:
echo 'export PATH="/usr/local/opt/openjdk/bin:$PATH"' >> /Users/lzw/.bash_profile
कंपाइलर्स को openjdk ढूंढने के लिए आपको यह सेट करने की आवश्यकता हो सकती है: export CPPFLAGS=”-I/usr/local/opt/openjdk/include”
==> सारांश
🍺 /usr/local/Cellar/openjdk/15.0.1: 614 फ़ाइलें, 324.9MB
==> Hadoop इंस्टॉल कर रहा है
🍺 /usr/local/Cellar/hadoop/3.3.0: 21,819 फ़ाइलें, 954.7MB, 2 मिनट 15 सेकंड में बनाया गया
==> 1 निर्भर को अपग्रेड कर रहा है:
maven 3.3.3 -> 3.6.3_1
==> Maven 3.3.3 -> 3.6.3_1 को अपग्रेड कर रहा है
==> डाउनलोड कर रहा है https://www.apache.org/dyn/closer.lua?path=maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
==> डाउनलोड कर रहा है https://mirror.olnevhost.net/pub/apache/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz से
######################################################################## 100.0%
त्रुटि: brew link चरण सफलतापूर्वक पूरा नहीं हुआ
फ़ॉर्मूला बनाया गया, लेकिन /usr/local में सिमलिंक नहीं किया गया
bin/mvn को सिमलिंक नहीं किया जा सका
लक्ष्य /usr/local/bin/mvn
maven का एक सिमलिंक है। आप इसे अनलिंक कर सकते हैं:
brew unlink maven
लिंक को बाध्य करने और सभी संघर्षरत फ़ाइलों को ओवरराइट करने के लिए: brew link –overwrite maven
सभी फ़ाइलों को सूचीबद्ध करने के लिए जो हटा दी जाएंगी: brew link –overwrite –dry-run maven
संभावित विरोधाभासी फ़ाइलें हैं: /usr/local/bin/mvn -> /usr/local/Cellar/maven/3.3.3/bin/mvn /usr/local/bin/mvnDebug -> /usr/local/Cellar/maven/3.3.3/bin/mvnDebug /usr/local/bin/mvnyjp -> /usr/local/Cellar/maven/3.3.3/bin/mvnyjp ==> सारांश 🍺 /usr/local/Cellar/maven/3.6.3_1: 87 फ़ाइलें, 10.7MB, 7 सेकंड में बनाया गया हटाया जा रहा है: /usr/local/Cellar/maven/3.3.3… (92 फ़ाइलें, 9MB) ==> अपग्रेड किए गए फ़ॉर्मूले के आश्रितों की जाँच कर रहा है… ==> कोई टूटे हुए आश्रित नहीं मिले! ==> चेतावनी ==> openjdk सिस्टम Java wrappers को इस JDK को खोजने के लिए, इसे symlink करें sudo ln -sfn /usr/local/opt/openjdk/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk.jdk
openjdk keg-only है, जिसका अर्थ है कि इसे /usr/local में symlink नहीं किया गया है, क्योंकि यह macOS के java wrapper को छिपाता है।
यदि आपको अपने PATH में openjdk को सबसे पहले रखने की आवश्यकता है, तो निम्नलिखित कमांड चलाएँ:
echo 'export PATH="/usr/local/opt/openjdk/bin:$PATH"' >> /Users/lzw/.bash_profile
कंपाइलर को openjdk ढूंढने के लिए आपको यह सेट करने की आवश्यकता हो सकती है: export CPPFLAGS=”-I/usr/local/opt/openjdk/include”
ध्यान दें कि `brew` के आउटपुट लॉग में `maven` को ठीक से लिंक नहीं किया गया है। इसके बाद, `3.6.3_1` संस्करण के लिए मजबूती से लिंक करें।
```shell
brew link --overwrite maven
(यह कमांड Maven को लिंक करने और पहले से मौजूद फाइलों को ओवरराइट करने के लिए उपयोग की जाती है।)
Hadoop सफलतापूर्वक इंस्टॉल हो गया है।
मॉड्यूल
इस प्रोजेक्ट में निम्नलिखित मॉड्यूल शामिल हैं:
- Hadoop Common: अन्य Hadoop मॉड्यूल का समर्थन करने वाले सामान्य उपयोगिताएँ।
- Hadoop Distributed File System (HDFS™): एक वितरित फ़ाइल सिस्टम जो एप्लिकेशन डेटा तक उच्च-थ्रूपुट पहुंच प्रदान करता है।
- Hadoop YARN: जॉब शेड्यूलिंग और क्लस्टर संसाधन प्रबंधन के लिए एक फ्रेमवर्क।
- Hadoop MapReduce: बड़े डेटा सेट के समानांतर प्रसंस्करण के लिए एक YARN-आधारित सिस्टम।
- Hadoop Ozone: Hadoop के लिए एक ऑब्जेक्ट स्टोर।
यह कहा जा रहा है कि ये मॉड्यूल हैं। इसे टाइप करने पर hadoop दिखाई देगा:
$ hadoop
उपयोग: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
या hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
जहां CLASSNAME एक उपयोगकर्ता-प्रदत्त Java क्लास है
OPTIONS कोई नहीं या निम्नलिखित में से कोई भी हो सकता है:
--config dir Hadoop कॉन्फ़िग डायरेक्टरी
--debug शेल स्क्रिप्ट डिबग मोड चालू करें
--help उपयोग जानकारी
buildpaths बिल्ड ट्री से क्लास फ़ाइलें जोड़ने का प्रयास करें
hostnames list[,of,host,names] स्लेव मोड में उपयोग करने के लिए होस्ट नाम
hosts filename स्लेव मोड में उपयोग करने के लिए होस्ट्स की सूची
loglevel level इस कमांड के लिए log4j स्तर सेट करें
workers वर्कर मोड चालू करें
SUBCOMMAND निम्नलिखित में से एक है:
व्यवस्थापक कमांड:
daemonlog प्रत्येक डेमन के लिए लॉग स्तर प्राप्त/सेट करें
क्लाइंट कमांड्स:
archive Hadoop आर्काइव बनाएं
checknative Hadoop और कंप्रेशन लाइब्रेरीज़ की उपलब्धता की जाँच करें
classpath Hadoop jar और आवश्यक लाइब्रेरीज़ प्राप्त करने के लिए आवश्यक क्लास पाथ प्रिंट करें
conftest कॉन्फ़िगरेशन XML फ़ाइलों को वैलिडेट करें
credential क्रेडेंशियल प्रोवाइडर्स के साथ इंटरैक्ट करें
distch वितरित मेटाडेटा परिवर्तक
distcp फ़ाइल या डायरेक्टरीज़ को रिकर्सिवली कॉपी करें
dtutil डेलिगेशन टोकन से संबंधित ऑपरेशन
envvars गणना किए गए Hadoop पर्यावरण चर प्रदर्शित करें
fs एक सामान्य फ़ाइलसिस्टम यूज़र क्लाइंट चलाएं
gridmix सिंथेटिक जॉब का मिश्रण सबमिट करें, जो प्रोडक्शन लोड से मॉडलिंग करता है
jar <jar> एक jar फ़ाइल चलाएं। नोट: कृपया YARN एप्लिकेशन लॉन्च करने के लिए "yarn jar" का उपयोग करें, इस कमांड का नहीं।
jnipath java.library.path प्रिंट करें
kdiag Kerberos समस्याओं का निदान करें
kerbname auth_to_local प्रिंसिपल रूपांतरण दिखाएं
key KeyProvider के माध्यम से कुंजियों का प्रबंधन करें
rumenfolder एक rumen इनपुट ट्रेस को स्केल करें
rumentrace लॉग्स को rumen ट्रेस में कन्वर्ट करें
s3guard S3 पर मेटाडेटा का प्रबंधन करें
trace Hadoop ट्रेसिंग सेटिंग्स देखें और संशोधित करें
version संस्करण प्रिंट करें
डेमन कमांड्स:
kms KMS चलाएं, यह की मैनेजमेंट सर्वर है
registrydns रजिस्ट्री DNS सर्वर चलाएं
SUBCOMMAND बिना पैरामीटर्स के या -h के साथ आमंत्रित होने पर मदद प्रिंट कर सकता है।
आधिकारिक वेबसाइट पर कुछ उदाहरण दिए गए हैं।
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+'
$ cat output/*
ध्यान दें कि share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar मौजूद है। इसका मतलब यह हो सकता है कि कुछ उदाहरण फ़ाइलें हमें नहीं मिली हैं। अनुमान है कि Homebrew के माध्यम से इंस्टॉल करने पर ये फ़ाइलें नहीं मिलती हैं। हमने आधिकारिक वेबसाइट से इंस्टॉलेशन पैकेज डाउनलोड किया है।
$ tree . -L 1
.
├── LICENSE-binary
├── LICENSE.txt
├── NOTICE-binary
├── NOTICE.txt
├── README.txt
├── bin
├── etc
├── include
├── lib
├── libexec
├── licenses-binary
├── sbin
└── share
share डायरेक्टरी दिखाई दी है। हालांकि, क्या Homebrew वास्तव में इन अतिरिक्त फ़ाइलों को शामिल नहीं करता है? Homebrew के इंस्टॉलेशन डायरेक्टरी को ढूंढें।
$ type hadoop
hadoop है /usr/local/bin/hadoop
$ ls -alrt /usr/local/bin/hadoop
lrwxr-xr-x 1 lzw admin 33 Mar 11 00:48 /usr/local/bin/hadoop -> ../Cellar/hadoop/3.3.0/bin/hadoop
$ cd /usr/local/Cellar/hadoop/3.3.0
यह /usr/local/Cellar/hadoop/3.3.0/libexec/share/hadoop के अंतर्गत प्रिंट की गई डायरेक्टरी ट्री है।
$ tree . -L 2
.
├── client
│ ├── hadoop-client-api-3.3.0.jar
│ ├── hadoop-client-minicluster-3.3.0.jar
│ └── hadoop-client-runtime-3.3.0.jar
├── common
│ ├── hadoop-common-3.3.0-tests.jar
│ ├── hadoop-common-3.3.0.jar
│ ├── hadoop-kms-3.3.0.jar
│ ├── hadoop-nfs-3.3.0.jar
│ ├── hadoop-registry-3.3.0.jar
│ ├── jdiff
│ ├── lib
│ ├── sources
│ └── webapps
├── hdfs
│ ├── hadoop-hdfs-3.3.0-tests.jar
│ ├── hadoop-hdfs-3.3.0.jar
│ ├── hadoop-hdfs-client-3.3.0-tests.jar
│ ├── hadoop-hdfs-client-3.3.0.jar
│ ├── hadoop-hdfs-httpfs-3.3.0.jar
│ ├── hadoop-hdfs-native-client-3.3.0-tests.jar
│ ├── hadoop-hdfs-native-client-3.3.0.jar
│ ├── hadoop-hdfs-nfs-3.3.0.jar
│ ├── hadoop-hdfs-rbf-3.3.0-tests.jar
│ ├── hadoop-hdfs-rbf-3.3.0.jar
│ ├── jdiff
│ ├── lib
│ ├── sources
│ └── webapps
├── mapreduce
│ ├── hadoop-mapreduce-client-app-3.3.0.jar
│ ├── hadoop-mapreduce-client-common-3.3.0.jar
│ ├── hadoop-mapreduce-client-core-3.3.0.jar
│ ├── hadoop-mapreduce-client-hs-3.3.0.jar
│ ├── hadoop-mapreduce-client-hs-plugins-3.3.0.jar
│ ├── hadoop-mapreduce-client-jobclient-3.3.0-tests.jar
│ ├── hadoop-mapreduce-client-jobclient-3.3.0.jar
│ ├── hadoop-mapreduce-client-nativetask-3.3.0.jar
│ ├── hadoop-mapreduce-client-shuffle-3.3.0.jar
│ ├── hadoop-mapreduce-client-uploader-3.3.0.jar
│ ├── hadoop-mapreduce-examples-3.3.0.jar
│ ├── jdiff
│ ├── lib-examples
│ └── sources
├── tools
│ ├── dynamometer
│ ├── lib
│ ├── resourceestimator
│ ├── sls
│ └── sources
└── yarn
├── csi
├── hadoop-yarn-api-3.3.0.jar
├── hadoop-yarn-applications-catalog-webapp-3.3.0.war
├── hadoop-yarn-applications-distributedshell-3.3.0.jar
├── hadoop-yarn-applications-mawo-core-3.3.0.jar
├── hadoop-yarn-applications-unmanaged-am-launcher-3.3.0.jar
├── hadoop-yarn-client-3.3.0.jar
├── hadoop-yarn-common-3.3.0.jar
├── hadoop-yarn-registry-3.3.0.jar
├── hadoop-yarn-server-applicationhistoryservice-3.3.0.jar
├── hadoop-yarn-server-common-3.3.0.jar
├── hadoop-yarn-server-nodemanager-3.3.0.jar
├── hadoop-yarn-server-resourcemanager-3.3.0.jar
├── hadoop-yarn-server-router-3.3.0.jar
├── hadoop-yarn-server-sharedcachemanager-3.3.0.jar
├── hadoop-yarn-server-tests-3.3.0.jar
├── hadoop-yarn-server-timeline-pluginstorage-3.3.0.jar
├── hadoop-yarn-server-web-proxy-3.3.0.jar
├── hadoop-yarn-services-api-3.3.0.jar
├── hadoop-yarn-services-core-3.3.0.jar
├── lib
├── sources
├── test
├── timelineservice
├── webapps
└── yarn-service-examples
आप देख सकते हैं कि बहुत सारे jar पैकेज हैं।
$ mkdir input
$ ls
bin hadoop-config.sh hdfs-config.sh libexec sbin yarn-config.sh
etc hadoop-functions.sh input mapred-config.sh share
$ cp etc/hadoop/*.xml input
$ cd input/
$ ls
capacity-scheduler.xml hadoop-policy.xml hdfs-site.xml kms-acls.xml mapred-site.xml
core-site.xml hdfs-rbf-site.xml httpfs-site.xml kms-site.xml yarn-site.xml
$ cd ..
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+'
JAR फ़ाइल मौजूद नहीं है या एक सामान्य फ़ाइल नहीं है: /usr/local/Cellar/hadoop/3.3.0/libexec/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar
$
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep input output 'dfs[a-z.]+'
2021-03-11 01:54:30,791 WARN util.NativeCodeLoader: आपके प्लेटफ़ॉर्म के लिए नेटिव-हडूप लाइब्रेरी लोड करने में असमर्थ... जहां लागू हो, बिल्ट-इन जावा क्लासेज़ का उपयोग कर रहे हैं
2021-03-11 01:54:31,115 INFO impl.MetricsConfig: hadoop-metrics2.properties से गुण लोड किए गए
2021-03-11 01:54:31,232 INFO impl.MetricsSystemImpl: मीट्रिक स्नैपशॉट अवधि 10 सेकंड पर शेड्यूल की गई।
...
वेबसाइट के उदाहरण के अनुसार टाइप करें। ध्यान दें कि bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input में, jar पैकेज से पहले वर्ज़न नंबर है। इसलिए हमें इसे अपने 3.3.0 से बदलना होगा।
लॉग का अंत:
2021-03-11 01:54:35,374 INFO mapreduce.Job: map 100% reduce 100%
2021-03-11 01:54:35,374 INFO mapreduce.Job: Job job_local2087514596_0002 सफलतापूर्वक पूरा हुआ
2021-03-11 01:54:35,377 INFO mapreduce.Job: काउंटर्स: 30
फाइल सिस्टम काउंटर्स
FILE: पढ़े गए बाइट्स की संख्या=1204316
FILE: लिखे गए बाइट्स की संख्या=3565480
FILE: पढ़ने के ऑपरेशन की संख्या=0
FILE: बड़े पढ़ने के ऑपरेशन की संख्या=0
FILE: लिखने के ऑपरेशन की संख्या=0
Map-Reduce फ्रेमवर्क
Map इनपुट रिकॉर्ड्स=1
Map आउटपुट रिकॉर्ड्स=1
Map आउटपुट बाइट्स=17
Map आउटपुट मटेरियलाइज्ड बाइट्स=25
इनपुट स्प्लिट बाइट्स=141
कॉम्बाइन इनपुट रिकॉर्ड्स=0
कॉम्बाइन आउटपुट रिकॉर्ड्स=0
रिड्यूस इनपुट ग्रुप्स=1
रिड्यूस शफल बाइट्स=25
रिड्यूस इनपुट रिकॉर्ड्स=1
रिड्यूस आउटपुट रिकॉर्ड्स=1
स्पिल्ड रिकॉर्ड्स=2
शफल्ड मैप्स =1
फेल्ड शफल्स=0
मर्ज्ड मैप आउटपुट्स=1
GC समय व्यतीत (ms)=57
कुल कमिटेड हीप उपयोग (बाइट्स)=772800512
शफल एरर्स
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
फाइल इनपुट फॉर्मेट काउंटर्स
पढ़े गए बाइट्स=123
फाइल आउटपुट फॉर्मेट काउंटर्स
लिखे गए बाइट्स=23
जारी रखें और देखें।
$ cat output/*
1 dfsadmin
यह वास्तव में क्या मतलब है? कोई बात नहीं, कुल मिलाकर हमने Hadoop को चला दिया है। और पहला स्टैंडअलोन कंप्यूटेशन उदाहरण भी चलाया है।
स्पार्क
Spark पर वापस आते हैं। एक उदाहरण देखते हैं।
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")
(यह कोड ब्लॉक को अनुवादित नहीं किया गया है क्योंकि यह Python कोड है और इसे हिंदी में अनुवादित करने की आवश्यकता नहीं है।)
यहां hdfs फ़ाइल दिखाई दी है। जांच करने के बाद, पता चला कि hdfs फ़ाइल इस तरह बनाई जा सकती है:
hdfs dfs -mkdir /test
hdfs कमांड को देखते हैं।
$ hdfs
उपयोग: hdfs [विकल्प] उपकमांड [उपकमांड विकल्प]
OPTIONS कोई नहीं या निम्नलिखित में से कोई भी हो सकता है:
–buildpaths बिल्ड ट्री से क्लास फ़ाइलें जोड़ने का प्रयास करें –config dir Hadoop कॉन्फ़िग डायरेक्टरी –daemon (start|status|stop) डेमन पर कार्रवाई करें –debug शेल स्क्रिप्ट डिबग मोड चालू करें –help उपयोग जानकारी –hostnames list[,of,host,names] वर्कर मोड में उपयोग करने के लिए होस्ट्स –hosts filename वर्कर मोड में उपयोग करने के लिए होस्ट्स की सूची –loglevel level इस कमांड के लिए log4j स्तर सेट करें –workers वर्कर मोड चालू करें
SUBCOMMAND निम्नलिखित में से एक हो सकता है: Admin Commands:
cacheadmin HDFS कैश को कॉन्फ़िगर करें crypto HDFS एन्क्रिप्शन ज़ोन को कॉन्फ़िगर करें debug HDFS डीबग कमांड्स को एक्ज़ीक्यूट करने के लिए डीबग एडमिन चलाएं dfsadmin एक DFS एडमिन क्लाइंट चलाएं dfsrouteradmin राउटर-आधारित फेडरेशन का प्रबंधन करें ec HDFS इरेज़र कोडिंग CLI चलाएं fsck DFS फ़ाइलसिस्टम चेकिंग यूटिलिटी चलाएं haadmin DFS HA एडमिन क्लाइंट चलाएं jmxget NameNode या DataNode से JMX एक्सपोर्टेड वैल्यूज़ प्राप्त करें oev एडिट्स फ़ाइल पर ऑफ़लाइन एडिट्स व्यूअर लागू करें oiv fsimage पर ऑफ़लाइन fsimage व्यूअर लागू करें oiv_legacy लेगेसी fsimage पर ऑफ़लाइन fsimage व्यूअर लागू करें storagepolicies ब्लॉक स्टोरेज पॉलिसीज़ को सूचीबद्ध/प्राप्त/सेट/संतुष्ट करें
क्लाइंट कमांड्स:
classpath Hadoop jar और आवश्यक लाइब्रेरीज़ प्राप्त करने के लिए आवश्यक क्लास पथ प्रिंट करता है dfs फ़ाइल सिस्टम पर एक फ़ाइल सिस्टम कमांड चलाता है envvars गणित Hadoop पर्यावरण चर प्रदर्शित करता है fetchdt NameNode से एक प्रतिनिधि टोकन प्राप्त करता है getconf कॉन्फ़िगरेशन से कॉन्फ़िग मान प्राप्त करता है groups उन समूहों को प्राप्त करता है जिनसे उपयोगकर्ता संबंधित हैं lsSnapshottableDir वर्तमान उपयोगकर्ता द्वारा स्वामित्व वाले सभी स्नैपशॉटेबल डायरेक्टरीज़ को सूचीबद्ध करता है snapshotDiff एक डायरेक्टरी के दो स्नैपशॉट्स के बीच अंतर या वर्तमान डायरेक्टरी सामग्री और एक स्नैपशॉट के बीच अंतर दिखाता है version संस्करण प्रिंट करता है
डेमन कमांड्स:
balancer क्लस्टर संतुलन उपयोगिता चलाएं datanode DFS डेटानोड चलाएं dfsrouter DFS राउटर चलाएं diskbalancer दिए गए नोड पर डिस्क्स के बीच डेटा समान रूप से वितरित करें httpfs HttpFS सर्वर चलाएं, HDFS HTTP गेटवे journalnode DFS जर्नलनोड चलाएं mover ब्लॉक प्रतिकृति को स्टोरेज प्रकारों के बीच ले जाने के लिए उपयोगिता चलाएं namenode DFS नेमनोड चलाएं nfs3 NFS संस्करण 3 गेटवे चलाएं portmap पोर्टमैप सेवा चलाएं secondarynamenode DFS सेकेंडरी नेमनोड चलाएं sps बाहरी स्टोरेजपॉलिसीसंतुष्टि चलाएं zkfc ZK फेलओवर कंट्रोलर डेमन चलाएं
SUBCOMMAND, जब बिना पैरामीटर्स के या -h के साथ इनवोक किया जाता है, तो मदद प्रिंट कर सकता है।
कोड को संशोधित करना जारी रखें।
```python
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]")\
.config('spark.driver.bindAddress', '127.0.0.1')\
.getOrCreate()
sc = spark.sparkContext
यह कोड एक SparkSession बनाता है और उसे spark नाम से इनिशियलाइज़ करता है। master("local[*]") का उपयोग करके यह स्थानीय मशीन पर सभी उपलब्ध कोर का उपयोग करता है। spark.driver.bindAddress को 127.0.0.1 पर सेट किया गया है, जो ड्राइवर को लोकलहोस्ट पर बाइंड करता है। अंत में, getOrCreate() मेथड का उपयोग करके SparkSession को बनाया या पहले से मौजूद सत्र को प्राप्त किया जाता है। sc वेरिएबल SparkContext को संदर्भित करता है, जो Spark एप्लिकेशन का मुख्य प्रवेश बिंदु है।
text_file = sc.textFile("a.txt")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("b.txt")
यह कोड Apache Spark में एक सरल शब्द गणना (word count) प्रोग्राम है। यह a.txt फ़ाइल से पाठ पढ़ता है, प्रत्येक शब्द को गिनता है, और परिणाम को b.txt फ़ाइल में सहेजता है।
ध्यान दें कि .config('spark.driver.bindAddress', '127.0.0.1') सेट करना महत्वपूर्ण है। अन्यथा, आपको Service 'sparkDriver' could not bind on a random free port. You may check whether configuring an appropriate binding address जैसी त्रुटि मिल सकती है।
हालांकि, इस समय फिर से एक त्रुटि उत्पन्न हुई।
Caused by: org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/pyspark/python/lib/pyspark.zip/pyspark/worker.py", line 473, in main
raise Exception(("Python in worker has different version %s than that in " +
Exception: वर्कर में Python का संस्करण 3.8 है जो ड्राइवर के संस्करण 3.9 से अलग है, PySpark अलग-अलग माइनर संस्करणों के साथ नहीं चल सकता। कृपया पर्यावरण चर PYSPARK_PYTHON और PYSPARK_DRIVER_PYTHON को सही ढंग से सेट करने की जाँच करें।
यह दर्शाता है कि विभिन्न संस्करणों के Python चलाए गए हैं।
.bash_profile को संशोधित करें:
PYSPARK_PYTHON=/usr/local/Cellar/python@3.9/3.9.1_6/bin/python3
PYSPARK_DRIVER_PYTHON=/usr/local/Cellar/python@3.9/3.9.1_6/bin/python3
फिर भी वही त्रुटि आ रही है। कुछ जानकारी प्राप्त करने के बाद, यह संभव है कि spark चलाते समय यह पर्यावरण चर लोड नहीं हुआ हो, और टर्मिनल के डिफ़ॉल्ट पर्यावरण चर का उपयोग नहीं किया गया हो।
कोड में निम्नलिखित सेटिंग्स की आवश्यकता है:
import os
Spark वातावरण सेट करें
os.environ[‘PYSPARK_PYTHON’] = ‘/usr/local/Cellar/python@3.9/3.9.1_6/bin/python3’ os.environ[‘PYSPARK_DRIVER_PYTHON’] = ‘/usr/local/Cellar/python@3.9/3.9.1_6/bin/python3’
यह चलेगा।
```shell
$ python sc.py
21/03/11 02:54:52 WARN NativeCodeLoader: आपके प्लेटफॉर्म के लिए native-hadoop लाइब्रेरी लोड करने में असमर्थ... जहां लागू हो, वहां builtin-java क्लासेस का उपयोग किया जा रहा है
Spark का डिफ़ॉल्ट log4j प्रोफ़ाइल उपयोग कर रहा है: org/apache/spark/log4j-defaults.properties
डिफ़ॉल्ट लॉग स्तर को "WARN" पर सेट किया जा रहा है।
लॉगिंग स्तर को समायोजित करने के लिए sc.setLogLevel(newLevel) का उपयोग करें। SparkR के लिए, setLogLevel(newLevel) का उपयोग करें।
PythonRDD[6] at RDD at PythonRDD.scala:53
इस समय b.txt फ़ाइल जनरेट हो गई है।
├── b.txt
│ ├── _SUCCESS
│ ├── part-00000
│ └── part-00001
खोलो।
$ cat b.txt/part-00000
('college', 1)
('two', 1)
('things', 2)
('worked', 1)
('on,', 1)
('of', 8)
('school,', 2)
('writing', 2)
('programming.', 1)
("didn't", 4)
('then,', 1)
('probably', 1)
('are:', 1)
('short', 1)
('awful.', 1)
('They', 1)
('plot,', 1)
('just', 1)
('characters', 1)
('them', 2)
...
सफलता! क्या यह परिचित नहीं लगता? यह ठीक वैसा ही है जैसा Hadoop उदाहरण में था।
$ cat output/*
1 dfsadmin
(यहाँ कोड ब्लॉक है, इसलिए इसे अनुवादित नहीं किया गया है।)
ये फ़ाइलें HDFS कहलाती हैं। यहाँ Spark का उपयोग शब्दों की गिनती करने के लिए किया गया है। कुछ ही पंक्तियों में, यह बहुत सुविधाजनक लगता है।
Kubernetes
अगला कदम Kubernetes को समझना है, जिसे k8s भी कहा जाता है, जहां बीच के 8 अक्षरों को 8 से संक्षिप्त किया गया है। यह एक ओपन-सोर्स सिस्टम है जो कंटेनर एप्लिकेशन्स को स्वचालित रूप से डिप्लॉय, स्केल और मैनेज करने के लिए उपयोग किया जाता है।
kubectl कमांड लाइन टूल का उपयोग k8s क्लस्टर पर कुछ कमांड चलाने के लिए किया जाता है। इसका उपयोग एप्लिकेशन को डिप्लॉय करने, क्लस्टर संसाधनों को देखने और प्रबंधित करने, और लॉग्स देखने के लिए किया जा सकता है।
Homebrew का उपयोग करके भी इंस्टॉल किया जा सकता है।
brew install kubectl
(नोट: यह एक कमांड है जिसे टर्मिनल में चलाया जाता है। इसे हिंदी में ट्रांसलेट करने की आवश्यकता नहीं है।)
लॉग आउटपुट:
==> डाउनलोड हो रहा है https://homebrew.bintray.com/bottles/kubernetes-cli-1.20.1.big_sur.bottle.tar.gz
==> डाउनलोड हो रहा है https://d29vzk4ow07wi7.cloudfront.net/0b4f08bd1d47cb913d7cd4571e3394c6747dfbad7ff114c5589c8396c1085ecf?response-content-disposition=a
######################################################################## 100.0%
==> डाला जा रहा है kubernetes-cli-1.20.1.big_sur.bottle.tar.gz
==> सावधानियाँ
Bash पूर्णता स्थापित की गई है:
/usr/local/etc/bash_completion.d
==> सारांश
🍺 /usr/local/Cellar/kubernetes-cli/1.20.1: 246 फ़ाइलें, 46.1MB
इंस्टॉल हो गया है।
$ kubectl version --client
Client Version: version.Info{Major:"1", Minor:"20", GitVersion:"v1.20.1", GitCommit:"c4d752765b3bbac2237bf87cf0b1c2e307844666", GitTreeState:"clean", BuildDate:"2020-12-19T08:38:20Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"darwin/amd64"}
$ kubectl
kubectl Kubernetes क्लस्टर मैनेजर को नियंत्रित करता है।
अधिक जानकारी के लिए यहां जाएं: https://kubernetes.io/docs/reference/kubectl/overview/
बेसिक कमांड्स (शुरुआती): create फ़ाइल या stdin से एक संसाधन बनाएं। expose एक रिप्लिकेशन कंट्रोलर, सर्विस, डिप्लॉयमेंट या पॉड लें और इसे एक नई Kubernetes सर्विस के रूप में एक्सपोज़ करें। run क्लस्टर पर एक विशिष्ट इमेज चलाएं। set ऑब्जेक्ट्स पर विशिष्ट फ़ीचर्स सेट करें।
बेसिक कमांड्स (इंटरमीडिएट): explain संसाधनों का दस्तावेज़ीकरण get एक या अनेक संसाधनों को प्रदर्शित करें edit सर्वर पर एक संसाधन को संपादित करें delete फ़ाइलनाम, stdin, संसाधन और नाम, या संसाधन और लेबल चयनकर्ता द्वारा संसाधनों को हटाएं
Deploy Commands: rollout किसी संसाधन के रोलआउट का प्रबंधन करें scale Deployment, ReplicaSet या Replication Controller के लिए एक नया आकार सेट करें autoscale Deployment, ReplicaSet, या ReplicationController को स्वचालित रूप से स्केल करें
क्लस्टर प्रबंधन कमांड्स: certificate सर्टिफिकेट संसाधनों को संशोधित करें। cluster-info क्लस्टर की जानकारी प्रदर्शित करें। top संसाधन (CPU/मेमोरी/स्टोरेज) उपयोग प्रदर्शित करें। cordon नोड को अनुसूचित नहीं करने योग्य के रूप में चिह्नित करें। uncordon नोड को अनुसूचित करने योग्य के रूप में चिह्नित करें। drain रखरखाव की तैयारी में नोड को ड्रेन करें। taint एक या अधिक नोड्स पर टेंट्स को अपडेट करें।
समस्या निवारण और डिबगिंग कमांड: describe किसी विशिष्ट संसाधन या संसाधनों के समूह का विवरण दिखाएं logs पॉड में कंटेनर के लॉग प्रिंट करें attach चल रहे कंटेनर से जुड़ें exec कंटेनर में एक कमांड निष्पादित करें port-forward एक या अधिक स्थानीय पोर्ट्स को पॉड में फॉरवर्ड करें proxy Kubernetes API सर्वर के लिए एक प्रॉक्सी चलाएं cp कंटेनर से और कंटेनर में फ़ाइलें और डायरेक्टरीज़ कॉपी करें auth प्राधिकरण का निरीक्षण करें debug वर्कलोड और नोड्स के समस्या निवारण के लिए डिबगिंग सत्र बनाएं
उन्नत कमांड्स: diff लाइव संस्करण और लागू किए जाने वाले संस्करण के बीच अंतर दिखाएं apply फ़ाइलनाम या stdin के माध्यम से कॉन्फ़िगरेशन को संसाधन पर लागू करें patch संसाधन के फ़ील्ड को अपडेट करें replace फ़ाइलनाम या stdin के माध्यम से संसाधन को बदलें wait प्रायोगिक: एक या कई संसाधनों पर विशिष्ट स्थिति की प्रतीक्षा करें। kustomize एक निर्देशिका या दूरस्थ URL से एक kustomization लक्ष्य बनाएं।
सेटिंग्स कमांड्स: label किसी संसाधन पर लेबल अपडेट करें annotate किसी संसाधन पर एनोटेशन अपडेट करें completion निर्दिष्ट शेल (bash या zsh) के लिए शेल पूर्णता कोड आउटपुट करें
अन्य कमांड्स: api-resources सर्वर पर समर्थित API संसाधनों को प्रिंट करें api-versions सर्वर पर समर्थित API संस्करणों को “group/version” के रूप में प्रिंट करें config kubeconfig फ़ाइलों को संशोधित करें plugin प्लगइन्स के साथ इंटरैक्ट करने के लिए उपयोगिताएँ प्रदान करें version क्लाइंट और सर्वर संस्करण जानकारी प्रिंट करें
उपयोग: kubectl [फ्लैग्स] [विकल्प]
किसी दिए गए कमांड के बारे में अधिक जानकारी के लिए “kubectl
एक कॉन्फ़िगरेशन फ़ाइल बनाने के लिए।
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
minReadySeconds: 5
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
यह YAML फ़ाइल एक Kubernetes Deployment को परिभाषित करती है जो nginx कंटेनर को डिप्लॉय करती है। यह Deployment nginx-deployment नाम से जाना जाएगा और यह nginx:1.14.2 इमेज का उपयोग करेगा। कंटेनर 80 पोर्ट पर लिसन करेगा। minReadySeconds सेटिंग यह सुनिश्चित करती है कि कंटेनर कम से कम 5 सेकंड तक तैयार रहेगा।
```shell
$ kubectl apply -f simple_deployment.yaml
सर्वर localhost:8080 से कनेक्शन अस्वीकार कर दिया गया - क्या आपने सही होस्ट या पोर्ट निर्दिष्ट किया है?
$ kubectl cluster-info
क्लस्टर समस्याओं को और डीबग और डायग्नोस करने के लिए, ‘kubectl cluster-info dump’ का उपयोग करें। सर्वर localhost:8080 से कनेक्शन अस्वीकार कर दिया गया - क्या आपने सही होस्ट या पोर्ट निर्दिष्ट किया है?
जब आप आधिकारिक वेबसाइट के टर्मिनल का उपयोग करके इसे चलाने की कोशिश करते हैं।
```shell
$ start.sh
Kubernetes शुरू हो रहा है...minikube संस्करण: v1.8.1
कमिट: cbda04cf6bbe65e987ae52bb393c10099ab62014
* minikube v1.8.1 Ubuntu 18.04 पर
* उपयोगकर्ता कॉन्फ़िगरेशन के आधार पर none ड्राइवर का उपयोग कर रहा है
* localhost पर चल रहा है (CPUs=2, Memory=2460MB, Disk=145651MB) ...
* OS रिलीज़ Ubuntu 18.04.4 LTS है
- Kubernetes v1.17.3 को Docker 19.03.6 पर तैयार कर रहे हैं …
- kubelet.resolv-conf=/run/systemd/resolve/resolv.conf
- Kubernetes लॉन्च कर रहे हैं …
- ऐडऑन्स सक्षम कर रहे हैं: default-storageclass, storage-provisioner
- लोकल होस्ट वातावरण को कॉन्फ़िगर कर रहे हैं …
- हो गया! kubectl अब “minikube” का उपयोग करने के लिए कॉन्फ़िगर है
- ‘dashboard’ ऐडऑन सक्षम है Kubernetes शुरू हो गया है ```
हमारे टर्मिनल पर वापस आते हैं।
$ kubectl version --client
Client Version: version.Info{Major:"1", Minor:"20", GitVersion:"v1.20.1", GitCommit:"c4d752765b3bbac2237bf87cf0b1c2e307844666", GitTreeState:"clean", BuildDate:"2020-12-19T08:38:20Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"darwin/amd64"}
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"20", GitVersion:"v1.20.1", GitCommit:"c4d752765b3bbac2237bf87cf0b1c2e307844666", GitTreeState:"clean", BuildDate:"2020-12-19T08:38:20Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"darwin/amd64"}
सर्वर localhost:8080 से कनेक्शन अस्वीकार कर दिया गया - क्या आपने सही होस्ट या पोर्ट निर्दिष्ट किया है?
दिलचस्प बात यह है कि --client विकल्प को जोड़ने पर कोई त्रुटि नहीं आई।
दस्तावेज़ के अनुसार, Minikube को पहले इंस्टॉल करना आवश्यक है।
$ brew install minikube
==> Downloading https://homebrew.bintray.com/bottles/minikube-1.16.0.big_sur.bottle.tar.gz
==> Downloading from https://d29vzk4ow07wi7.cloudfront.net/1b6d7d1b97b11b6b07e4fa531c2dc21770da290da9b2816f360fd923e00c85fc?response-content-disposition=a
######################################################################## 100.0%
==> Pouring minikube-1.16.0.big_sur.bottle.tar.gz
==> Caveats
Bash पूर्णता (completion) इंस्टॉल की गई है:
/usr/local/etc/bash_completion.d
==> Summary
🍺 /usr/local/Cellar/minikube/1.16.0: 8 फाइलें, 64.6MB
$ minikube start
😄 minikube v1.16.0 डार्विन 11.2.2 पर
🎉 minikube 1.18.1 उपलब्ध है! इसे डाउनलोड करें: https://github.com/kubernetes/minikube/releases/tag/v1.18.1
💡 इस सूचना को अक्षम करने के लिए, चलाएं: 'minikube config set WantUpdateNotification false'
✨ स्वचालित रूप से virtualbox ड्राइवर का चयन किया गया 💿 VM बूट इमेज डाउनलोड हो रहा है … > minikube-v1.16.0.iso.sha256: 65 B / 65 B [————-] 100.00% ? p/s 0s > minikube-v1.16.0.iso: 212.62 MiB / 212.62 MiB [] 100.00% 5.32 MiB p/s 40s 👍 कंट्रोल प्लेन नोड minikube को क्लस्टर minikube में शुरू किया जा रहा है 💾 Kubernetes v1.20.0 प्रीलोड डाउनलोड हो रहा है … > preloaded-images-k8s-v8-v1….: 491.00 MiB / 491.00 MiB 100.00% 7.52 MiB 🔥 virtualbox VM बनाया जा रहा है (CPUs=2, Memory=4000MB, Disk=20000MB) … ❗ इस VM को https://k8s.gcr.io तक पहुंचने में समस्या हो रही है 💡 नई बाहरी इमेज को पुल करने के लिए, आपको एक प्रॉक्सी कॉन्फ़िगर करने की आवश्यकता हो सकती है: https://minikube.sigs.k8s.io/docs/reference/networking/proxy/ 🐳 Kubernetes v1.20.0 को Docker 20.10.0 पर तैयार किया जा रहा है … ▪ सर्टिफिकेट और कुंजियाँ जनरेट की जा रही हैं … ▪ कंट्रोल प्लेन को बूट किया जा रहा है … ▪ RBAC नियम कॉन्फ़िगर किए जा रहे हैं … 🔎 Kubernetes कंपोनेंट्स की जाँच की जा रही है… 🌟 एडऑन्स सक्षम किए गए: storage-provisioner, default-storageclass 🏄 हो गया! kubectl अब डिफ़ॉल्ट रूप से “minikube” क्लस्टर और “default” नेमस्पेस का उपयोग करने के लिए कॉन्फ़िगर हो गया है
इस क्लस्टर को एक्सेस करने के लिए आगे बढ़ें।
```shell
$ kubectl get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-74ff55c5b-ndbcr 1/1 चल रहा है 0 60s
kube-system etcd-minikube 0/1 चल रहा है 0 74s
kube-system kube-apiserver-minikube 1/1 चल रहा है 0 74s
kube-system kube-controller-manager-minikube 1/1 चल रहा है 0 74s
kube-system kube-proxy-g2296 1/1 चल रहा है 0 60s
kube-system kube-scheduler-minikube 0/1 चल रहा है 0 74s
kube-system storage-provisioner 1/1 चल रहा है 1 74s
minikube का डैशबोर्ड खोलने के लिए।
$ minikube dashboard
🔌 डैशबोर्ड सक्षम कर रहा है ...
🤔 डैशबोर्ड स्वास्थ्य की जाँच कर रहा है ...
🚀 प्रॉक्सी लॉन्च कर रहा है ...
🤔 प्रॉक्सी स्वास्थ्य की जाँच कर रहा है ...
🎉 आपके डिफ़ॉल्ट ब्राउज़र में http://127.0.0.1:50030/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/ खोल रहा है...
कैसे बंद करें।
$ minikube
minikube विकास वर्कफ़्लो के लिए अनुकूलित स्थानीय Kubernetes क्लस्टर्स को प्रोविज़न और प्रबंधित करता है।
बेसिक कमांड्स: start एक स्थानीय Kubernetes क्लस्टर शुरू करता है status एक स्थानीय Kubernetes क्लस्टर की स्थिति प्राप्त करता है stop चल रहे स्थानीय Kubernetes क्लस्टर को रोकता है delete एक स्थानीय Kubernetes क्लस्टर को हटाता है dashboard minikube क्लस्टर के अंदर चल रहे Kubernetes डैशबोर्ड तक पहुंच प्रदान करता है pause Kubernetes को पॉज़ करता है unpause Kubernetes को अनपॉज़ करता है
Images Commands: docker-env minikube के Docker डेमन का उपयोग करने के लिए वातावरण को कॉन्फ़िगर करें podman-env minikube के Podman सेवा का उपयोग करने के लिए वातावरण को कॉन्फ़िगर करें cache minikube में एक स्थानीय छवि को जोड़ें, हटाएं, या पुश करें
कॉन्फ़िगरेशन और प्रबंधन कमांड: addons मिनिक्यूब ऐडऑन को सक्षम या अक्षम करें config स्थायी कॉन्फ़िगरेशन मानों को संशोधित करें profile वर्तमान प्रोफाइल (क्लस्टर) प्राप्त करें या सूचीबद्ध करें update-context IP या पोर्ट परिवर्तन के मामले में kubeconfig को अपडेट करें
नेटवर्किंग और कनेक्टिविटी कमांड्स: service किसी सेवा से कनेक्ट करने के लिए एक URL रिटर्न करता है tunnel LoadBalancer सेवाओं से कनेक्ट करता है
उन्नत कमांड्स: mount निर्दिष्ट डायरेक्टरी को minikube में माउंट करता है ssh minikube वातावरण में लॉग इन करें (डिबगिंग के लिए) kubectl क्लस्टर संस्करण से मेल खाने वाले kubectl बाइनरी को चलाएं node अतिरिक्त नोड्स को जोड़ें, हटाएं, या सूचीबद्ध करें
समस्या निवारण कमांड्स: ssh-key निर्दिष्ट नोड की ssh पहचान कुंजी पथ प्राप्त करें ssh-host निर्दिष्ट नोड की ssh होस्ट कुंजी प्राप्त करें ip निर्दिष्ट नोड का IP पता प्राप्त करें logs स्थानीय Kubernetes क्लस्टर को डीबग करने के लिए लॉग्स लौटाएं update-check वर्तमान और नवीनतम संस्करण संख्या प्रिंट करें version minikube का संस्करण प्रिंट करें
अन्य कमांड: completion किसी शेल के लिए कमांड पूर्णता उत्पन्न करें
किसी दिए गए कमांड के बारे में अधिक जानकारी के लिए “minikube
दिखाई दे रहा है कि यह `minikube stop` है।
`kubernetes` पर वापस आते हुए, अब यह ठीक से काम कर रहा है।
```shell
$ kubectl cluster-info
Kubernetes कंट्रोल प्लेन https://192.168.99.100:8443 पर चल रहा है
KubeDNS https://192.168.99.100:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy पर चल रहा है
क्लस्टर समस्याओं को और डीबग और निदान करने के लिए, ‘kubectl cluster-info dump’ का उपयोग करें।
जब हम `https://192.168.99.100:8443` खोलते हैं, तो ब्राउज़र दिखाता है:
```json
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "निषिद्ध: उपयोगकर्ता \"system:anonymous\" पथ \"/\" प्राप्त नहीं कर सकता",
"reason": "Forbidden",
"details": {
},
"code": 403
}
https://192.168.99.100:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy पर जाएं:
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "सेवाएँ \"kube-dns:dns\" निषिद्ध हैं: उपयोगकर्ता \"system:anonymous\" API समूह \"\" में नामस्थान \"kube-system\" में संसाधन \"services/proxy\" प्राप्त नहीं कर सकता है",
"reason": "Forbidden",
"details": {
"name": "kube-dns:dns",
"kind": "services"
},
"code": 403
}
आइए अभी उस कॉन्फ़िगरेशन को आज़माएं।
$ kubectl apply -f simple_deployment.yaml
deployment.apps/nginx-deployment बनाया गया
थोड़ी समस्या है। हालांकि, यहां तक हमने kubernetes को चला लिया है। पहले इसे समाप्त करते हैं। बाद में फिर खेलेंगे।
$ minikube stop
✋ "minikube" नोड को रोक रहा है ...
🛑 1 नोड रोक दिया गया।
समाप्ति की जाँच करें।
w$ minikube dashboard
🤷 इस कमांड के लिए कंट्रोल प्लेन नोड चल रहा होना चाहिए
👉 क्लस्टर शुरू करने के लिए, चलाएं: "minikube start"
Docker
Docker एक कंटेनर प्लेटफॉर्म भी है, जो आधुनिक एप्लिकेशन बनाने, साझा करने और चलाने में तेजी लाने में मदद करता है। आधिकारिक वेबसाइट से एप्लिकेशन डाउनलोड करें।
क्लाइंट का उपयोग करते समय थोड़ा लैग हो रहा है। चलो कमांड लाइन का उपयोग करते हैं।
$ docker
उपयोग: docker [विकल्प] कमांड
कंटेनरों के लिए एक स्वयं-पर्याप्त रनटाइम
विकल्प: –config string क्लाइंट कॉन्फ़िग फ़ाइलों का स्थान (डिफ़ॉल्ट “/Users/lzw/.docker”) -c, –context string डेमन से कनेक्ट करने के लिए उपयोग करने वाले कॉन्टेक्स्ट का नाम (DOCKER_HOST env var और “docker context use” के साथ सेट डिफ़ॉल्ट कॉन्टेक्स्ट को ओवरराइड करता है) -D, –debug डिबग मोड सक्षम करें -H, –host list कनेक्ट करने के लिए डेमन सॉकेट(s) -l, –log-level string लॉगिंग स्तर सेट करें (“debug”|”info”|”warn”|”error”|”fatal”) (डिफ़ॉल्ट “info”) –tls TLS का उपयोग करें; –tlsverify द्वारा निहित –tlscacert string केवल इस CA द्वारा हस्ताक्षरित प्रमाणपत्रों पर भरोसा करें (डिफ़ॉल्ट “/Users/lzw/.docker/ca.pem”) –tlscert string TLS प्रमाणपत्र फ़ाइल का पथ (डिफ़ॉल्ट “/Users/lzw/.docker/cert.pem”) –tlskey string TLS कुंजी फ़ाइल का पथ (डिफ़ॉल्ट “/Users/lzw/.docker/key.pem”) –tlsverify TLS का उपयोग करें और रिमोट को सत्यापित करें -v, –version संस्करण जानकारी प्रिंट करें और बाहर निकलें
प्रबंधन कमांड्स: app* Docker App (Docker Inc., v0.9.1-beta3) builder बिल्ड्स प्रबंधित करें buildx* BuildKit के साथ बिल्ड करें (Docker Inc., v0.5.1-docker) config Docker कॉन्फ़िगरेशन प्रबंधित करें container कंटेनर प्रबंधित करें context कॉन्टेक्स्ट प्रबंधित करें image इमेज प्रबंधित करें manifest Docker इमेज मैनिफेस्ट और मैनिफेस्ट सूचियाँ प्रबंधित करें network नेटवर्क प्रबंधित करें node Swarm नोड्स प्रबंधित करें plugin प्लगइन्स प्रबंधित करें scan* Docker Scan (Docker Inc., v0.5.0) secret Docker सीक्रेट्स प्रबंधित करें service सर्विसेज प्रबंधित करें stack Docker स्टैक्स प्रबंधित करें swarm Swarm प्रबंधित करें system Docker प्रबंधित करें trust Docker इमेज पर ट्रस्ट प्रबंधित करें volume वॉल्यूम प्रबंधित करें
कमांड्स: attach एक चल रहे कंटेनर से स्थानीय मानक इनपुट, आउटपुट और त्रुटि स्ट्रीम को जोड़ें build Dockerfile से एक इमेज बनाएं commit कंटेनर में हुए परिवर्तनों से एक नई इमेज बनाएं cp कंटेनर और स्थानीय फाइल सिस्टम के बीच फाइल/फोल्डर कॉपी करें create एक नया कंटेनर बनाएं diff कंटेनर के फाइल सिस्टम पर फाइल या डायरेक्टरी में हुए परिवर्तनों का निरीक्षण करें events सर्वर से रियल टाइम इवेंट्स प्राप्त करें exec एक चल रहे कंटेनर में कमांड चलाएं export कंटेनर के फाइल सिस्टम को tar आर्काइव के रूप में निर्यात करें history एक इमेज का इतिहास दिखाएं images इमेज की सूची दिखाएं import एक tarball से सामग्री आयात करके फाइल सिस्टम इमेज बनाएं info सिस्टम-व्यापी जानकारी प्रदर्शित करें inspect Docker ऑब्जेक्ट्स पर निम्न-स्तरीय जानकारी दिखाएं kill एक या अधिक चल रहे कंटेनर को समाप्त करें load tar आर्काइव या STDIN से एक इमेज लोड करें login Docker रजिस्ट्री में लॉग इन करें logout Docker रजिस्ट्री से लॉग आउट करें logs कंटेनर के लॉग प्राप्त करें pause एक या अधिक कंटेनर के सभी प्रक्रियाओं को रोकें port कंटेनर के पोर्ट मैपिंग या एक विशिष्ट मैपिंग की सूची दिखाएं ps कंटेनर की सूची दिखाएं pull रजिस्ट्री से एक इमेज या रिपॉजिटरी डाउनलोड करें push रजिस्ट्री में एक इमेज या रिपॉजिटरी अपलोड करें rename कंटेनर का नाम बदलें restart एक या अधिक कंटेनर को पुनरारंभ करें rm एक या अधिक कंटेनर हटाएं rmi एक या अधिक इमेज हटाएं run एक नए कंटेनर में कमांड चलाएं save एक या अधिक इमेज को tar आर्काइव के रूप में सहेजें (डिफ़ॉल्ट रूप से STDOUT पर स्ट्रीम किया जाता है) search Docker Hub पर इमेज खोजें start एक या अधिक रुके हुए कंटेनर शुरू करें stats कंटेनर(र) के संसाधन उपयोग सांख्यिकी का लाइव स्ट्रीम प्रदर्शित करें stop एक या अधिक चल रहे कंटेनर को रोकें tag एक टैग TARGET_IMAGE बनाएं जो SOURCE_IMAGE को संदर्भित करता है top कंटेनर की चल रही प्रक्रियाओं को प्रदर्शित करें unpause एक या अधिक कंटेनर के सभी प्रक्रियाओं को अनपॉज़ करें update एक या अधिक कंटेनर की कॉन्फ़िगरेशन अपडेट करें version Docker संस्करण जानकारी दिखाएं wait एक या अधिक कंटेनर के रुकने तक ब्लॉक करें, फिर उनके एग्जिट कोड प्रिंट करें
किसी कमांड के बारे में अधिक जानकारी के लिए ‘docker COMMAND –help’ चलाएं।
Docker के बारे में अधिक मदद पाने के लिए, हमारे गाइड्स देखें: https://docs.docker.com/go/guides/
ट्यूटोरियल के अनुसार कोशिश करें।
```shell
$ docker run -d -p 80:80 docker/getting-started
'docker/getting-started:latest' इमेज स्थानीय रूप से नहीं मिली
latest: docker/getting-started से खींचा जा रहा है
aad63a933944: पूरी तरह से खींचा गया
b14da7a62044: पूरी तरह से खींचा गया
343784d40d66: पूरी तरह से खींचा गया
6f617e610986: पूरी तरह से खींचा गया
Digest: sha256:d2c4fb0641519ea208f20ab03dc40ec2a5a53fdfbccca90bef14f870158ed577
Status: docker/getting-started के लिए नई इमेज डाउनलोड की गई
815f13fc8f99f6185257980f74c349e182842ca572fe60ff62cbb15641199eaf
docker: डेमन से त्रुटि प्रतिक्रिया: पोर्ट उपलब्ध नहीं हैं: listen tcp 0.0.0.0:80: bind: पता पहले से उपयोग में है।
पोर्ट बदलें।
$ docker run -d -p 8080:80 docker/getting-started
45bb95fa1ae80adc05cc498a1f4f339c45c51f7a8ae1be17f5b704853a5513a5
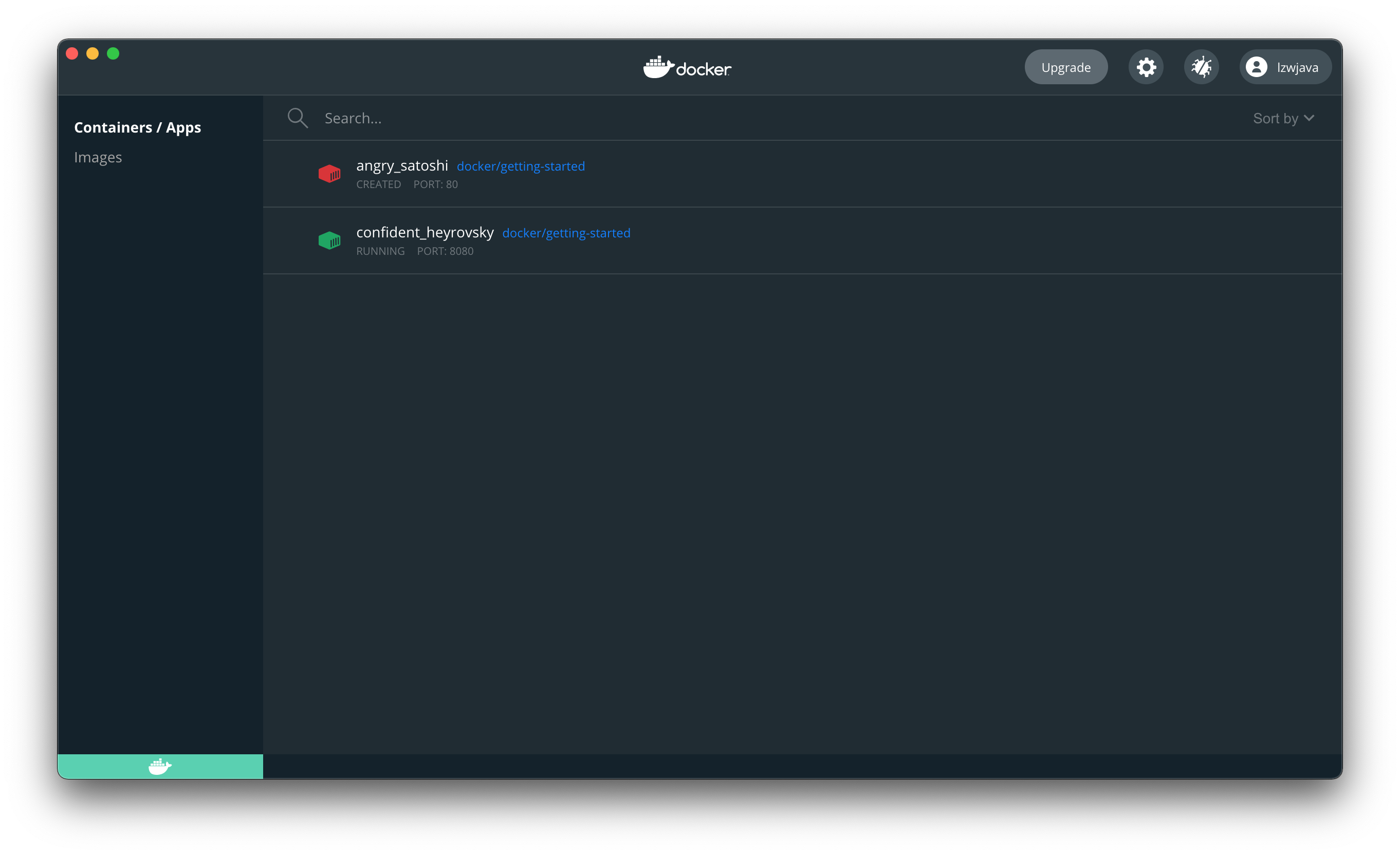
ब्राउज़र खोलें, यह दर्शाता है कि हमने docker को सफलतापूर्वक चला दिया है।
कंटेनर को रोकें। पहले प्राप्त किए गए ID का उपयोग करें।
$ docker stop 45bb95fa1ae80adc05cc498a1f4f339c45c51f7a8ae1be17f5b704853a5513a5
45bb95fa1ae80adc05cc498a1f4f339c45c51f7a8ae1be17f5b704853a5513a5
इस समय वेबसाइट खोलना संभव नहीं था।
इससे पता चलता है कि docker एक वर्चुअल मशीन की तरह है।
Flink
वेबसाइट खोलें।
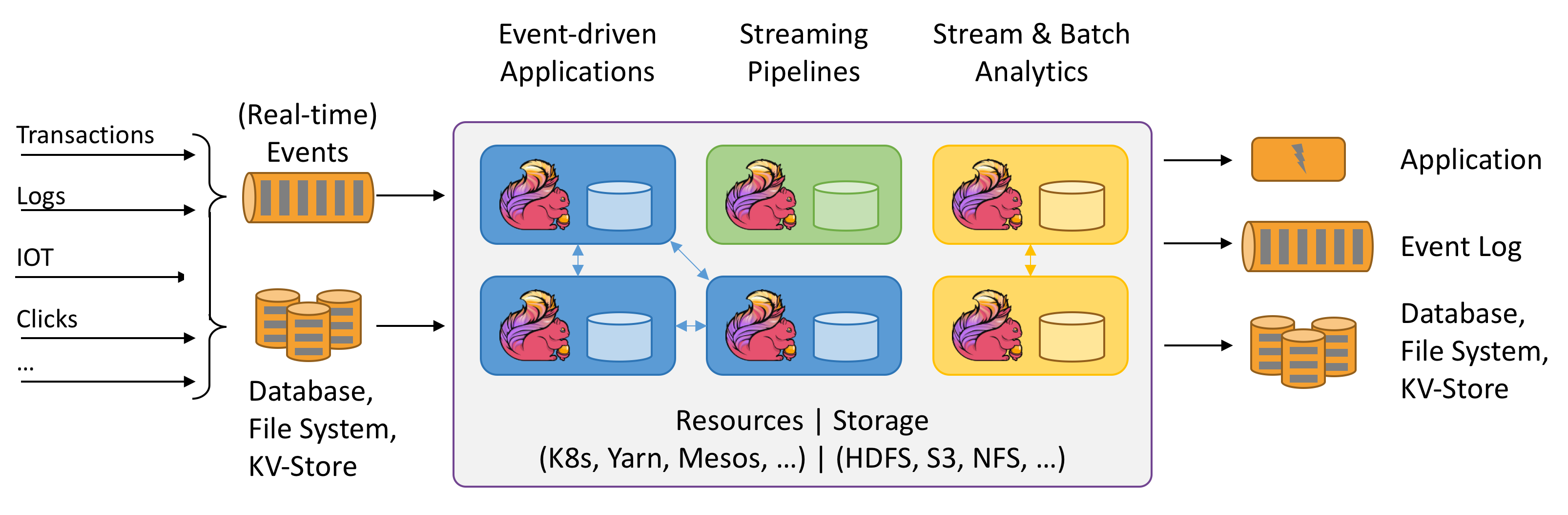
Flink को डेटा स्ट्रीम के Stateful कंप्यूटेशन के रूप में जाना जाता है। Stateful का क्या मतलब है? अभी तक समझ में नहीं आया। ऊपर दिया गया चित्र बहुत दिलचस्प है। आइए इसे आज़माएं।
यह कहा जाता है कि Java वातावरण की आवश्यकता है।
$ java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
आधिकारिक वेबसाइट से नवीनतम संस्करण flink-1.12.2-bin-scala_2.11.tar डाउनलोड करें।
$ ./bin/start-cluster.sh
क्लस्टर शुरू कर रहा है।
होस्ट lzwjava पर स्टैंडअलोनसेशन डेमन शुरू कर रहा है।
होस्ट lzwjava पर टास्कएक्जीक्यूटर डेमन शुरू कर रहा है।
$ ./bin/flink run examples/streaming/WordCount.jar
डिफ़ॉल्ट इनपुट डेटा सेट के साथ WordCount उदाहरण को निष्पादित कर रहा है।
फ़ाइल इनपुट निर्दिष्ट करने के लिए --input का उपयोग करें।
परिणाम को stdout पर प्रिंट कर रहा है। आउटपुट पथ निर्दिष्ट करने के लिए --output का उपयोग करें।
JobID 60f37647c20c2a6654359bd34edab807 के साथ जॉब सबमिट की गई है।
प्रोग्राम निष्पादन समाप्त हो गया है।
JobID 60f37647c20c2a6654359bd34edab807 के साथ जॉब समाप्त हो गई है।
जॉब रनटाइम: 757 मिलीसेकंड
$ tail log/flink-*-taskexecutor-*.out
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)
$ ./bin/stop-cluster.sh
टास्कएक्ज़ीक्यूटर डेमन (pid: 41812) को होस्ट lzwjava पर रोक रहा है।
हाँ, सफलतापूर्वक शुरुआत की। यह देखा जा सकता है कि यह Spark के समान है।
काइलिन
आधिकारिक वेबसाइट खोलने के लिए।
Apache Kylin™ एक ओपन सोर्स, वितरित विश्लेषणात्मक डेटा वेयरहाउस है जो बिग डेटा के लिए डिज़ाइन किया गया है; यह बिग डेटा युग में OLAP (ऑनलाइन विश्लेषणात्मक प्रसंस्करण) क्षमता प्रदान करने के लिए बनाया गया था। Hadoop और Spark पर मल्टी-डायमेंशनल क्यूब और प्रीकैलकुलेशन तकनीक को नवीनीकृत करके, Kylin लगातार बढ़ते डेटा वॉल्यूम के बावजूद लगभग स्थिर क्वेरी गति प्राप्त करने में सक्षम है। क्वेरी विलंबता को मिनटों से सब-सेकंड तक कम करके, Kylin ऑनलाइन एनालिटिक्स को बिग डेटा में वापस लाता है।
Apache Kylin™ आपको 3 चरणों में सब-सेकंड लेटेंसी पर अरबों पंक्तियों को क्वेरी करने की सुविधा देता है।
- Hadoop पर एक Star/Snowflake Schema की पहचान करें।
- पहचाने गए टेबल्स से Cube बनाएं।
- ANSI-SQL का उपयोग करके क्वेरी करें और ODBC, JDBC या RESTful API के माध्यम से सब-सेकंड में परिणाम प्राप्त करें।
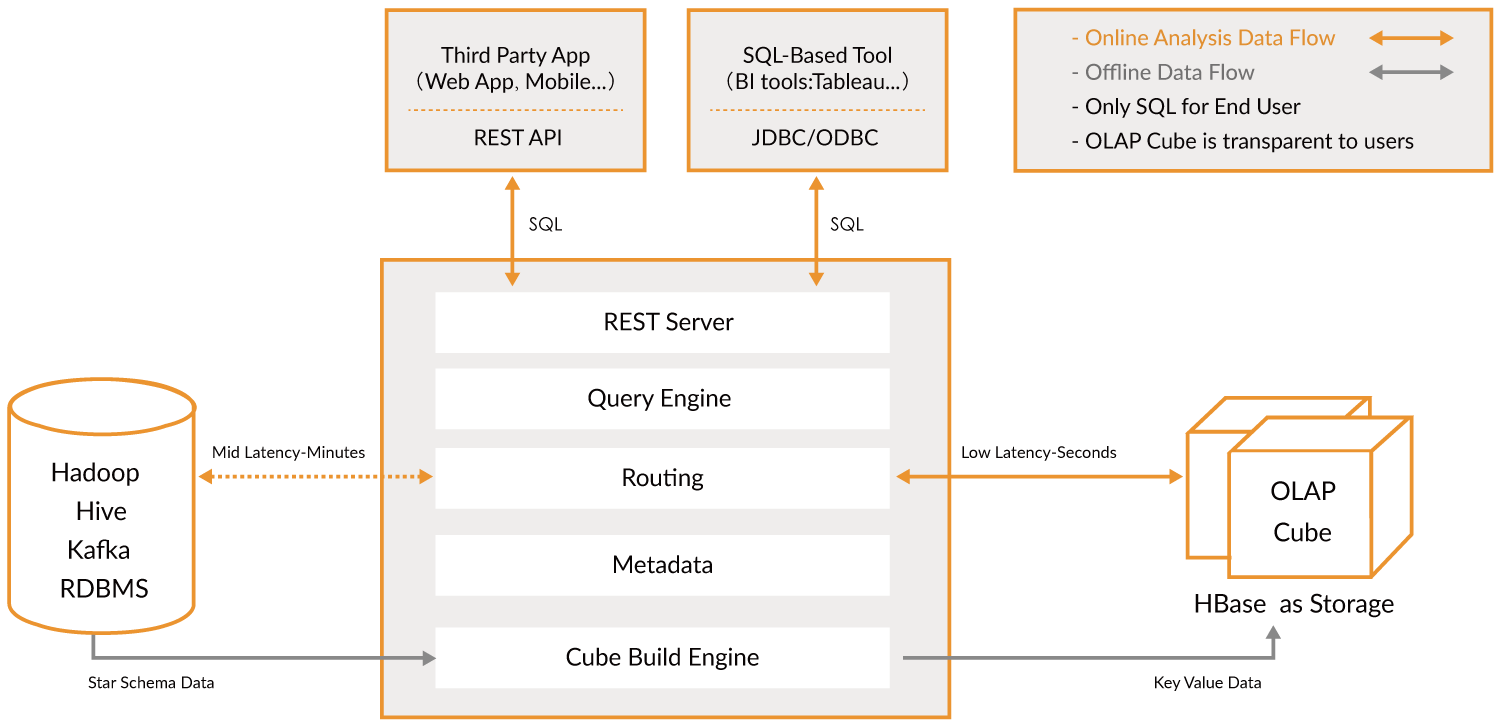
यह मूल रूप से बड़े डेटा के विश्लेषण की एक परत है। इसका उपयोग करके आप बहुत तेज़ी से खोज सकते हैं। यह एक पुल की तरह काम करता है।
दुर्भाग्य से, यह वर्तमान में केवल Linux वातावरण में उपयोग किया जा सकता है। बाद में इसे फिर से संभालूंगा।
MongoDB
यह भी एक प्रकार का डेटाबेस है। इसे इंस्टॉल करके देखें।
$ brew tap mongodb/brew
==> mongodb/brew को टैप कर रहा है
'/usr/local/Homebrew/Library/Taps/mongodb/homebrew-brew' में क्लोन किया जा रहा है...
remote: ऑब्जेक्ट्स की गणना कर रहा है: 63, हो गया।
remote: ऑब्जेक्ट्स की गिनती: 100% (63/63), हो गया।
remote: ऑब्जेक्ट्स को संपीड़ित कर रहा है: 100% (62/62), हो गया।
remote: कुल 566 (डेल्टा 21), पुन: उपयोग किए गए 6 (डेल्टा 1), पैक-पुन: उपयोग किए गए 503
ऑब्जेक्ट्स प्राप्त कर रहा है: 100% (566/566), 121.78 KiB | 335.00 KiB/s, हो गया।
डेल्टा को हल कर रहा है: 100% (259/259), हो गया।
11 फॉर्मूले (39 फाइलें, 196.2KB) टैप किए गए।
$ brew install mongodb-community@4.4
==> mongodb/brew से mongodb-community इंस्टॉल कर रहा है
==> https://fastdl.mongodb.org/tools/db/mongodb-database-tools-macos-x86_64-100.3.0.zip डाउनलोड कर रहा है
######################################################################## 100.0%
==> https://fastdl.mongodb.org/osx/mongodb-macos-x86_64-4.4.3.tgz डाउनलोड कर रहा है
######################################################################## 100.0%
==> mongodb/brew/mongodb-community के लिए डिपेंडेंसीज इंस्टॉल कर रहा है: mongodb-database-tools
==> mongodb/brew/mongodb-community डिपेंडेंसी: mongodb-database-tools इंस्टॉल कर रहा है
त्रुटि: `brew link` चरण सफलतापूर्वक पूरा नहीं हुआ
फॉर्मूला बन गया, लेकिन /usr/local में सिमलिंक नहीं हुआ
bin/bsondump को सिमलिंक नहीं किया जा सका
टार्गेट /usr/local/bin/bsondump
mongodb का एक सिमलिंक है। आप इसे अनलिंक कर सकते हैं:
brew unlink mongodb
लिंक को फोर्स करने और सभी संघर्ष करने वाली फ़ाइलों को ओवरराइट करने के लिए: brew link –overwrite mongodb-database-tools
सभी फ़ाइलों को सूचीबद्ध करने के लिए जिन्हें हटाया जाएगा: brew link –overwrite –dry-run mongodb-database-tools
संभावित टकराव वाली फ़ाइलें हैं:
/usr/local/bin/bsondump -> /usr/local/Cellar/mongodb/3.0.7/bin/bsondump
/usr/local/bin/mongodump -> /usr/local/Cellar/mongodb/3.0.7/bin/mongodump
/usr/local/bin/mongoexport -> /usr/local/Cellar/mongodb/3.0.7/bin/mongoexport
/usr/local/bin/mongofiles -> /usr/local/Cellar/mongodb/3.0.7/bin/mongofiles
/usr/local/bin/mongoimport -> /usr/local/Cellar/mongodb/3.0.7/bin/mongoimport
/usr/local/bin/mongorestore -> /usr/local/Cellar/mongodb/3.0.7/bin/mongorestore
/usr/local/bin/mongostat -> /usr/local/Cellar/mongodb/3.0.7/bin/mongostat
/usr/local/bin/mongotop -> /usr/local/Cellar/mongodb/3.0.7/bin/mongotop
==> सारांश
🍺 /usr/local/Cellar/mongodb-database-tools/100.3.0: 13 फ़ाइलें, 154MB, 11 सेकंड में बनाई गईं
==> mongodb/brew/mongodb-community स्थापित कर रहा है
त्रुटि: brew link चरण सफलतापूर्वक पूरा नहीं हुआ
फ़ॉर्मूला बन गया, लेकिन /usr/local में सिमलिंक नहीं किया गया है
bin/mongo को सिमलिंक नहीं किया जा सका
लक्ष्य /usr/local/bin/mongo
mongodb का एक सिमलिंक है। आप इसे अनलिंक कर सकते हैं:
brew unlink mongodb
लिंक को फोर्स करने और सभी संघर्ष करने वाली फ़ाइलों को ओवरराइट करने के लिए: brew link –overwrite mongodb-community
सभी फ़ाइलों को सूचीबद्ध करने के लिए जो हटा दी जाएंगी: brew link –overwrite –dry-run mongodb-community
संभावित संघर्ष करने वाली फ़ाइलें हैं: /usr/local/bin/mongo -> /usr/local/Cellar/mongodb/3.0.7/bin/mongo /usr/local/bin/mongod -> /usr/local/Cellar/mongodb/3.0.7/bin/mongod /usr/local/bin/mongos -> /usr/local/Cellar/mongodb/3.0.7/bin/mongos ==> सावधानियाँ launchd को mongodb/brew/mongodb-community को अभी शुरू करने और लॉगिन पर पुनः आरंभ करने के लिए: brew services start mongodb/brew/mongodb-community या, यदि आपको बैकग्राउंड सेवा की आवश्यकता/इच्छा नहीं है तो आप सिर्फ चला सकते हैं: mongod –config /usr/local/etc/mongod.conf ==> सारांश 🍺 /usr/local/Cellar/mongodb-community/4.4.3: 11 फ़ाइलें, 156.8MB, 10 सेकंड में बनाया गया ==> सावधानियाँ ==> mongodb-community launchd को mongodb/brew/mongodb-community को अभी शुरू करने और लॉगिन पर पुनः आरंभ करने के लिए: brew services start mongodb/brew/mongodb-community या, यदि आपको बैकग्राउंड सेवा की आवश्यकता/इच्छा नहीं है तो आप सिर्फ चला सकते हैं: mongod –config /usr/local/etc/mongod.conf
पहले मैंने एक पुराना वर्जन इंस्टॉल किया था। लिंक को हटा दें।
```shell
$ brew unlink mongodb
/usr/local/Cellar/mongodb/3.0.7 को अनलिंक किया जा रहा है... 11 सिमलिंक हटाए गए
$ mongod --version
db version v4.4.3
Build Info: {
"version": "4.4.3",
"gitVersion": "913d6b62acfbb344dde1b116f4161360acd8fd13",
"modules": [],
"allocator": "system",
"environment": {
"distarch": "x86_64",
"target_arch": "x86_64"
}
}
फिर mongod चलाकर mongo डेटाबेस सर्वर शुरू करें। हालांकि, पहली बार शुरू करते समय यह कहा गया कि /data/db मौजूद नहीं है। हम एक डायरेक्टरी बनाते हैं, ~/mongodb, जहां डेटाबेस फाइलों को सहेजा जाएगा।
$ mongod --dbpath ~/mongodb
(यह कोड ब्लॉक है, इसे अनुवादित नहीं किया जाना चाहिए।)
आउटपुट होगा:
{"t":{"$date":"2021-03-11T18:17:32.838+08:00"},"s":"I", "c":"CONTROL", "id":23285, "ctx":"main","msg":"स्वचालित रूप से TLS 1.0 को अक्षम कर दिया गया है, TLS 1.0 को जबरन सक्षम करने के लिए --sslDisabledProtocols 'none' निर्दिष्ट करें"}
{"t":{"$date":"2021-03-11T18:17:32.842+08:00"},"s":"W", "c":"ASIO", "id":22601, "ctx":"main","msg":"NetworkInterface शुरू होने के दौरान कोई TransportLayer कॉन्फ़िगर नहीं किया गया"}
{"t":{"$date":"2021-03-11T18:17:32.842+08:00"},"s":"I", "c":"NETWORK", "id":4648602, "ctx":"main","msg":"अप्रत्यक्ष TCP FastOpen उपयोग में है।"}
{"t":{"$date":"2021-03-11T18:17:32.842+08:00"},"s":"I", "c":"STORAGE", "id":4615611, "ctx":"initandlisten","msg":"MongoDB शुरू हो रहा है","attr":{"pid":46256,"port":27017,"dbPath":"/Users/lzw/mongodb","architecture":"64-bit","host":"lzwjava"}}
{"t":{"$date":"2021-03-11T18:17:32.842+08:00"},"s":"I", "c":"CONTROL", "id":23403, "ctx":"initandlisten","msg":"बिल्ड जानकारी","attr":{"buildInfo":{"version":"4.4.3","gitVersion":"913d6b62acfbb344dde1b116f4161360acd8fd13","modules":[],"allocator":"system","environment":{"distarch":"x86_64","target_arch":"x86_64"}}}}
{"t":{"$date":"2021-03-11T18:17:32.843+08:00"},"s":"I", "c":"CONTROL", "id":51765, "ctx":"initandlisten","msg":"ऑपरेटिंग सिस्टम","attr":{"os":{"name":"Mac OS X","version":"20.3.0"}}}
...
देखा जा सकता है कि सभी JSON प्रारूप में हैं। MongoDB में सभी डेटा फ़ाइलें JSON प्रारूप में सहेजी जाती हैं। इसके बाद, एक और टर्मिनल टैब खोलें।
$ mongo
MongoDB shell version v4.4.3
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("4f55c561-70d3-4289-938d-4b90a284891f") }
MongoDB server version: 4.4.3
---
सर्वर ने बूट होते समय ये स्टार्टअप चेतावनियाँ उत्पन्न कीं:
2021-03-11T18:17:33.743+08:00: डेटाबेस के लिए एक्सेस कंट्रोल सक्षम नहीं है। डेटा और कॉन्फ़िगरेशन तक पढ़ने और लिखने की पहुंच असीमित है
2021-03-11T18:17:33.743+08:00: यह सर्वर लोकलहोस्ट से बंधा हुआ है। दूरस्थ सिस्टम इस सर्वर से कनेक्ट नहीं कर पाएंगे। सर्वर को --bind_ip <address> के साथ शुरू करें ताकि यह निर्दिष्ट कर सकें कि यह किन IP पतों से प्रतिक्रियाएं देना चाहिए, या --bind_ip_all के साथ सभी इंटरफेस से बंधे। यदि यह व्यवहार वांछित है, तो सर्वर को --bind_ip 127.0.0.1 के साथ शुरू करें ताकि इस चेतावनी को अक्षम किया जा सके
2021-03-11T18:17:33.743+08:00: सॉफ्ट rlimits बहुत कम हैं
2021-03-11T18:17:33.743+08:00: currentValue: 4864
2021-03-11T18:17:33.743+08:00: recommendedMinimum: 64000
---
---
MongoDB के मुफ्त क्लाउड-आधारित मॉनिटरिंग सेवा को सक्षम करें, जो आपके डिप्लॉयमेंट के बारे में मेट्रिक्स (डिस्क उपयोग, CPU, ऑपरेशन सांख्यिकी, आदि) प्राप्त करेगा और प्रदर्शित करेगा।
मॉनिटरिंग डेटा एक MongoDB वेबसाइट पर उपलब्ध होगा, जिसका एक यूनिक URL आपके और उन लोगों के लिए सुलभ होगा, जिनके साथ आप URL साझा करते हैं। MongoDB इस जानकारी का उपयोग उत्पाद सुधार करने और आपको MongoDB उत्पादों और डिप्लॉयमेंट विकल्पों का सुझाव देने के लिए कर सकता है।
मुफ्त मॉनिटरिंग सक्षम करने के लिए, निम्नलिखित कमांड चलाएँ: `db.enableFreeMonitoring()`
इस अनुस्मारक को स्थायी रूप से अक्षम करने के लिए, निम्नलिखित कमांड चलाएँ: `db.disableFreeMonitoring()`
इसके बाद, आप डेटा इन्सर्ट करने और डेटा क्वेरी करने का प्रयास कर सकते हैं।
> db.inventory.insertOne(
... { item: "canvas", qty: 100, tags: ["cotton"], size: { h: 28, w: 35.5, uom: "cm" } }
... )
{
"acknowledged" : true,
"insertedId" : ObjectId("6049ef91b653541cf355facb")
}
>
> db.inventory.find()
{ "_id" : ObjectId("6049ef91b653541cf355facb"), "item" : "canvas", "qty" : 100, "tags" : [ "cotton" ], "size" : { "h" : 28, "w" : 35.5, "uom" : "cm" } }
अंत में
यहाँ तक। बाद में हम अन्य टूल्स पर हाथ आज़माएंगे। हम ये सब कर रहे हैं, इसका क्या मतलब है। शायद पहले एक संरचना बनाना है। हर काम की शुरुआत मुश्किल होती है, और हमने शुरुआत में ही इन सभी को एक बार में कर लिया। इससे हमें आत्मविश्वास मिला है, और अब आगे, हम इन सॉफ़्टवेयर को और अधिक एक्सप्लोर करेंगे।
अभ्यास
- छात्र ऊपर दिए गए तरीके से समान रूप से एक्सप्लोर करें।