完整AI工具生態系統 | 原創,AI翻譯
目錄
- Jina AI
- Jina AI 整合的 Python 腳本
- 使用
r.jina.ai獲取 URL 內容 - 使用
s.jina.ai處理搜索查詢 - Base64 編碼與 API 認證
- Tavily AI
- 專為 LLM 應用設計的 AI 搜索 API
- 設定與 API 金鑰註冊
- Python 客戶端實現
- 搜索請求示例與用法
- Open WebUI
- 本地 AI 介面安裝
- 伺服器設定與配置
- 與 Ollama 整合以使用本地模型
- 安裝時間與需求
- Tableau, Scale, 與 Power BI
- 商業智能平台比較
- Tableau 13 天試用體驗
- Scale 數據平台概述
- Microsoft Power BI 功能
- 使用 OpenRouter
- 接受中國簽發的 Visa 信用卡
- 模型排名與趨勢分析
- LLM 使用類別與應用
- 香港用戶訪問 Anthropic API 仍需 VPN
- ElevenLabs AI
- 文字轉語音 API 整合
- 語音克隆功能
- 多語言音頻生成
- 音頻轉換的 Python 腳本
Jina AI
此 Python 腳本使用 API 金鑰與命令列參數與 Jina AI 服務互動。它支持兩項主要任務:從 URL 獲取內容與執行搜索查詢。腳本從環境變數中獲取 Jina API 金鑰,確保服務的安全訪問。它使用 requests 庫發送 HTTP 請求,並使用 base64 解碼搜索查詢。腳本隨後打印 Jina AI 服務的回應。
import os
import requests
from dotenv import load_dotenv
import argparse
import base64
load_dotenv()
api_key = os.environ.get("JINA_API_KEY")
if not api_key:
raise ValueError("JINA_API_KEY environment variable not set.")
parser = argparse.ArgumentParser()
parser.add_argument("--job", type=str, choices=['url', 'search'], help="Job to execute (url or search)", required=True)
parser.add_argument("--input", type=str, help="Input for the job", required=True)
args = parser.parse_args()
if args.job == 'url':
url = f'https://r.jina.ai/{args.input}'
headers = {'Authorization': f'Bearer {api_key}'}
print(f"URL: {url}")
print(f"Headers: {headers}")
response = requests.get(url, headers=headers)
print(response.text)
elif args.job == 'search':
question = base64.b64decode(args.input).decode('utf-8', errors='ignore')
url = f'https://s.jina.ai/{question}'
headers = {
'Authorization': f'Bearer {api_key}',
'X-Engine': 'direct',
'X-Retain-Images': 'none'
}
print(f"URL: {url}")
print(f"Headers: {headers}")
response = requests.get(url, headers=headers)
print(response.text)
else:
print("Please specify --job url or --job search")
Tavily AI
Tavily 是一個專為 LLM 應用設計的 AI 搜索 API。它通過結合網絡搜索與 AI 處理,提供高度相關的搜索結果。
使用 Tavily 的步驟:
- 在 tavily.com 註冊獲取 API 金鑰。
- 安裝 Python 套件。
import os
from tavily import TavilyClient
# 從環境變數中獲取 API 金鑰
TAVILY_API_KEY = os.getenv('TAVILY_API_KEY')
if TAVILY_API_KEY is None:
raise ValueError("API key not found. Please set the TAVILY_API_KEY environment variable.")
# 使用獲取的 API 金鑰初始化 TavilyClient
tavily_client = TavilyClient(api_key=TAVILY_API_KEY)
# 發送搜索請求
response = tavily_client.search("Who is Leo Messi?")
# 打印回應
print(response)
Open WebUI
-
Open WebUI 是一個非常實用的工具。
-
啟動伺服器的命令:
pip install open-webui與open-webui serve。 -
安裝過程可能需要一些時間(約 10 分鐘或更長)。
-
Open WebUI 與 Ollama 搭配使用效果良好。
Tableau, Scale, 與 Power BI
Tableau
註冊後,我被告知有 13 天的試用期。
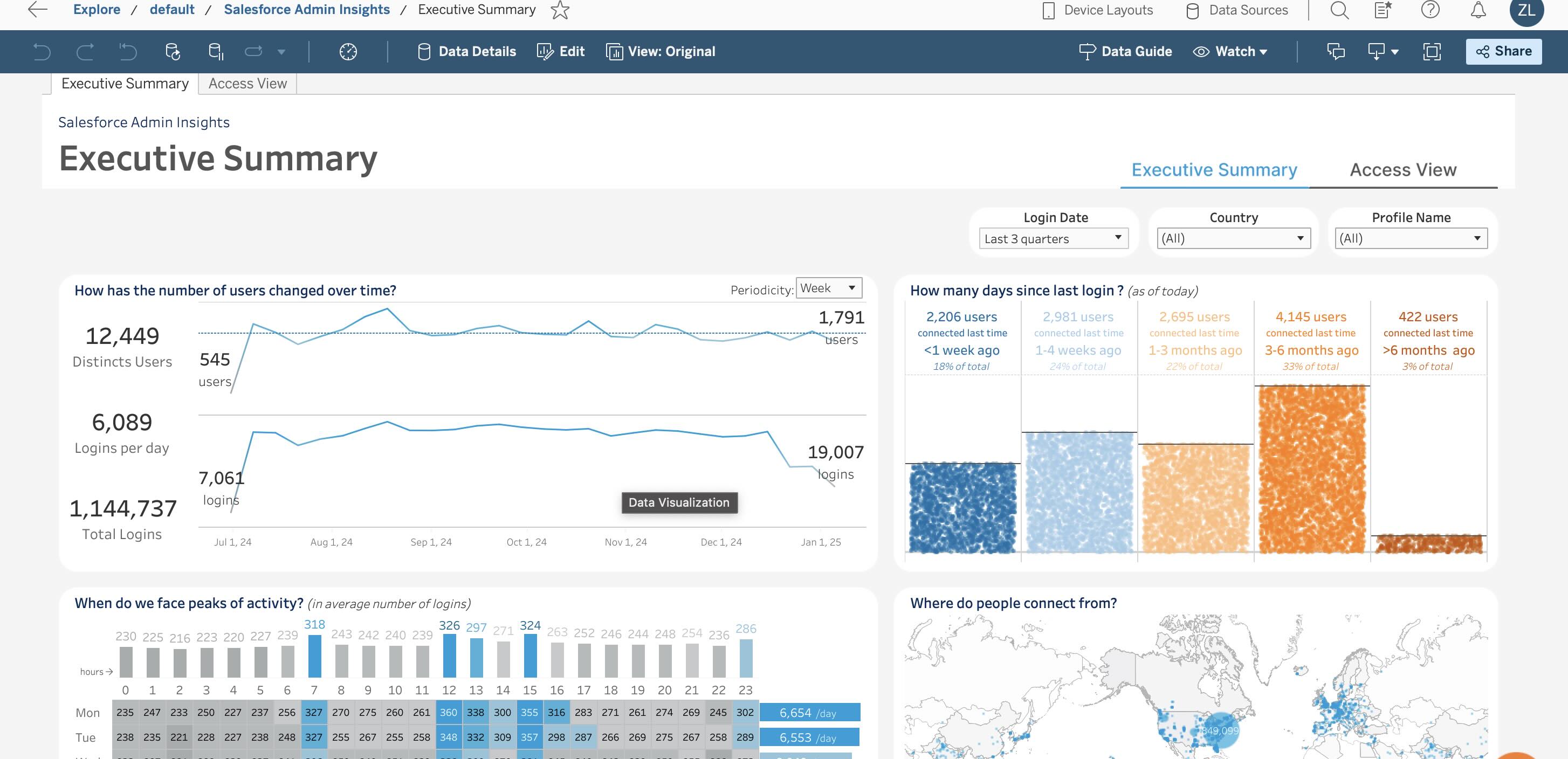 來源:tableau.com
來源:tableau.com
Scale
 來源:scale.com
來源:scale.com
Power BI
使用 OpenRouter
-
接受中國簽發的 Visa 信用卡。
-
排名頁面可以看到當下最熱門與趨勢模型。
-
你可以看到人們如何使用 LLM 模型於角色扮演、編程、市場營銷、市場營銷/SEO 與技術等類別。
-
香港用戶仍需使用 VPN 來訪問 Anthropic API。
ElevenLabs AI
import os
import requests
from dotenv import load_dotenv
import argparse
import re
load_dotenv()
api_key = os.environ.get("ELEVENLABS_API_KEY")
if not api_key:
raise ValueError("ELEVENLABS_API_KEY environment variable not set.")
parser = argparse.ArgumentParser()
parser.add_argument("--file", type=str, help="Markdown file to convert to speech", required=False)
parser.add_argument("--text", type=str, help="Text to convert to speech", required=False)
parser.add_argument("--output", type=str, help="Output file name", required=True)
parser.add_argument("--voice_id", type=str, default="21m00Tcm4TlvDq8iK2G8", help="Voice ID to use")
args = parser.parse_args()
if args.file:
try:
with open(args.file, 'r') as f:
content = f.read()
# Remove front matter
content = re.sub(r'---.*?---', '', content, flags=re.DOTALL)
text = content.strip()
except FileNotFoundError:
print(f"Error: File not found: {args.file}")
exit(1)
except Exception as e:
print(f"Error reading file: {e}")
exit(1)
elif args.text:
text = args.text
else:
print("Error: Either --file or --text must be specified.")
exit(1)
url = f"https://api.elevenlabs.io/v1/text-to-speech/{args.voice_id}"
headers = {
"Accept": "audio/mpeg",
"Content-Type": "application/json",
"xi-api-key": api_key
}
data = {
"text": text,
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.5
}
}
response = requests.post(url, json=data, headers=headers)
if response.status_code == 200:
with open(args.output, 'wb') as f:
f.write(response.content)
print(f"Audio saved to {args.output}")
else:
print(f"Error: {response.status_code} - {response.text}")