संपूर्ण एआई टूल्स इकोसिस्टम | मूल, AI द्वारा अनुवादित
सामग्री की तालिका
- Jina AI
- Jina AI एकीकरण के लिए पायथन स्क्रिप्ट
r.jina.aiके साथ URL सामग्री प्राप्त करनाs.jina.aiके साथ खोज क्वेरी प्रसंस्करण- Base64 एनकोडिंग और API प्रमाणीकरण
- Tavily AI
- LLM एप्लिकेशन्स के लिए विशेष AI खोज API
- सेटअप और API कुंजी पंजीकरण
- पायथन क्लाइंट कार्यान्वयन
- खोज अनुरोध उदाहरण और उपयोग
- Open WebUI
- स्थानीय AI इंटरफेस स्थापना
- सर्वर सेटअप और कॉन्फ़िगरेशन
- स्थानीय मॉडल्स के लिए Ollama एकीकरण
- स्थापना समय और आवश्यकताएँ
- Tableau, Scale, और Power BI
- व्यावसायिक बुद्धिमत्ता प्लेटफॉर्म्स की तुलना
- Tableau का 13-दिन का ट्रायल अनुभव
- Scale डेटा प्लेटफॉर्म का अवलोकन
- Microsoft Power BI की विशेषताएं
- OpenRouter का उपयोग
- चीन वीज़ा कार्ड भुगतान स्वीकृति
- मॉडल रैंकिंग और ट्रेंडिंग विश्लेषण
- LLM उपयोग श्रेणियाँ और एप्लिकेशन्स
- Anthropic API के लिए हांगकांग VPN आवश्यकताएँ
- ElevenLabs AI
- टेक्स्ट-टू-स्पीच API एकीकरण
- वॉयस क्लोनिंग क्षमताएं
- बहुभाषी ऑडियो जनरेशन
- ऑडियो रूपांतरण के लिए पायथन स्क्रिप्ट
Jina AI
यह पायथन स्क्रिप्ट API कुंजियों और कमांड-लाइन तर्कों का उपयोग करके Jina AI सेवाओं के साथ इंटरैक्ट करती है। यह दो मुख्य कार्यों का समर्थन करती है: एक URL से सामग्री प्राप्त करना और एक खोज क्वेरी निष्पादित करना। स्क्रिप्ट Jina API कुंजी को पर्यावरण चर से प्राप्त करती है, जिससे सेवाओं तक सुरक्षित पहुंच सुनिश्चित होती है। यह HTTP अनुरोध करने के लिए requests लाइब्रेरी और खोज क्वेरी को डिकोड करने के लिए base64 का उपयोग करती है। स्क्रिप्ट फिर Jina AI सेवा से प्रतिक्रिया प्रिंट करती है।
import os
import requests
from dotenv import load_dotenv
import argparse
import base64
load_dotenv()
api_key = os.environ.get("JINA_API_KEY")
if not api_key:
raise ValueError("JINA_API_KEY environment variable not set.")
parser = argparse.ArgumentParser()
parser.add_argument("--job", type=str, choices=['url', 'search'], help="Job to execute (url or search)", required=True)
parser.add_argument("--input", type=str, help="Input for the job", required=True)
args = parser.parse_args()
if args.job == 'url':
url = f'https://r.jina.ai/{args.input}'
headers = {'Authorization': f'Bearer {api_key}'}
print(f"URL: {url}")
print(f"Headers: {headers}")
response = requests.get(url, headers=headers)
print(response.text)
elif args.job == 'search':
question = base64.b64decode(args.input).decode('utf-8', errors='ignore')
url = f'https://s.jina.ai/{question}'
headers = {
'Authorization': f'Bearer {api_key}',
'X-Engine': 'direct',
'X-Retain-Images': 'none'
}
print(f"URL: {url}")
print(f"Headers: {headers}")
response = requests.get(url, headers=headers)
print(response.text)
else:
print("Please specify --job url or --job search")
Tavily AI
Tavily एक AI खोज API है जो विशेष रूप से LLM एप्लिकेशन्स के लिए डिज़ाइन किया गया है। यह वेब खोज को AI प्रसंस्करण के साथ जोड़कर अत्यधिक प्रासंगिक खोज परिणाम प्रदान करता है।
Tavily का उपयोग करने के लिए, आपको यह करना होगा:
- tavily.com पर एक API कुंजी के लिए साइन अप करें
- पायथन पैकेज इंस्टॉल करें।
import os
from tavily import TavilyClient
# पर्यावरण चर से API कुंजी प्राप्त करें
TAVILY_API_KEY = os.getenv('TAVILY_API_KEY')
if TAVILY_API_KEY is None:
raise ValueError("API कुंजी नहीं मिली। कृपया TAVILY_API_KEY पर्यावरण चर सेट करें।")
# प्राप्त API कुंजी के साथ TavilyClient को प्रारंभ करें
tavily_client = TavilyClient(api_key=TAVILY_API_KEY)
# एक खोज अनुरोध करें
response = tavily_client.search("Who is Leo Messi?")
# प्रतिक्रिया प्रिंट करें
print(response)
Open WebUI
-
Open WebUI एक बेहतरीन टूल है।
-
सर्वर शुरू करने के लिए, इन कमांड्स को निष्पादित करें:
pip install open-webuiऔरopen-webui serve। -
स्थापना प्रक्रिया में कुछ समय लग सकता है (लगभग 10 मिनट या अधिक)।
-
Open WebUI Ollama के साथ अच्छी तरह काम करता है।
Tableau, Scale, और Power BI
Tableau
पंजीकरण के बाद, मुझे सूचित किया गया कि मेरे पास सेवा का परीक्षण करने के लिए 13 दिन हैं।
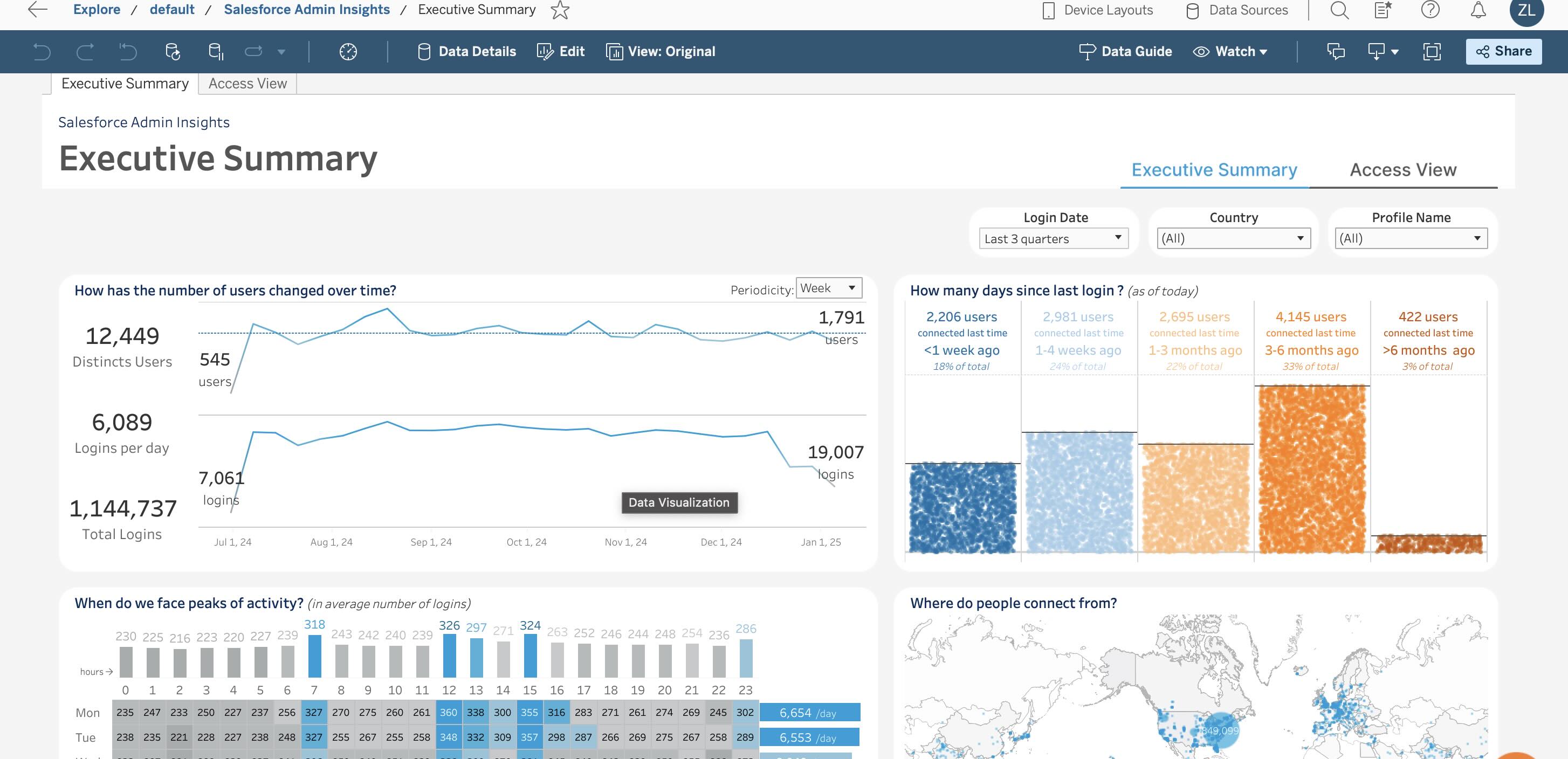 source: tableau.com
source: tableau.com
Scale
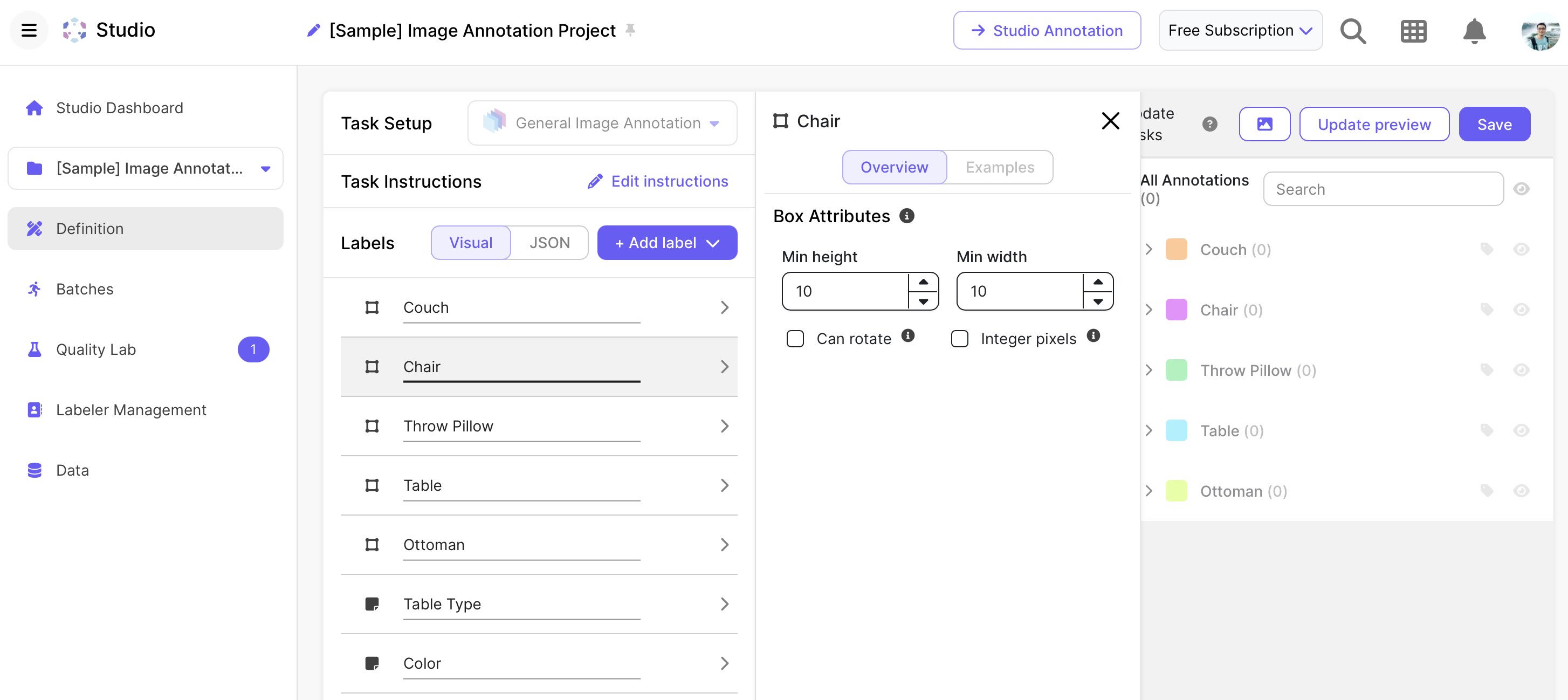 source: scale.com
source: scale.com
Power BI
OpenRouter का उपयोग
-
चीन-जारी किए गए वीज़ा क्रेडिट कार्ड स्वीकार किए जाते हैं।
-
रैंकिंग पृष्ठ सबसे लोकप्रिय और ट्रेंडिंग मॉडल्स देखने के लिए दिलचस्प है।
-
आप देख सकते हैं कि लोग LLM मॉडल्स का उपयोग कैसे करते हैं जैसे कि Roleplay, Programming, Marketing, Marketing/SEO, और Technology श्रेणियों में।
-
हांगकांग के उपयोगकर्ताओं के लिए, Anthropic API तक पहुंचने के लिए अभी भी एक VPN की आवश्यकता है।
ElevenLabs AI
-
बढ़िया। मैंने सेवा का परीक्षण करने के लिए $5 USD का उपयोग किया।
-
वॉयस क्लोनिंग बहुत अच्छी है।
-
ऑडियो नमूने नीचे दिए गए हैं:
import os
import requests
from dotenv import load_dotenv
import argparse
import re
load_dotenv()
api_key = os.environ.get("ELEVENLABS_API_KEY")
if not api_key:
raise ValueError("ELEVENLABS_API_KEY environment variable not set.")
parser = argparse.ArgumentParser()
parser.add_argument("--file", type=str, help="Markdown file to convert to speech", required=False)
parser.add_argument("--text", type=str, help="Text to convert to speech", required=False)
parser.add_argument("--output", type=str, help="Output file name", required=True)
parser.add_argument("--voice_id", type=str, default="21m00Tcm4TlvDq8iK2G8", help="Voice ID to use")
args = parser.parse_args()
if args.file:
try:
with open(args.file, 'r') as f:
content = f.read()
# Remove front matter
content = re.sub(r'---.*?---', '', content, flags=re.DOTALL)
text = content.strip()
except FileNotFoundError:
print(f"Error: File not found: {args.file}")
exit(1)
except Exception as e:
print(f"Error reading file: {e}")
exit(1)
elif args.text:
text = args.text
else:
print("Error: Either --file or --text must be specified.")
exit(1)
url = f"https://api.elevenlabs.io/v1/text-to-speech/{args.voice_id}"
headers = {
"Accept": "audio/mpeg",
"Content-Type": "application/json",
"xi-api-key": api_key
}
data = {
"text": text,
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.5
}
}
response = requests.post(url, json=data, headers=headers)
if response.status_code == 200:
with open(args.output, 'wb') as f:
f.write(response.content)
print(f"Audio saved to {args.output}")
else:
print(f"Error: {response.status_code} - {response.text}")