为什么Kafka速度这么快 | AI生成和翻译
核心要点
- 视频《系统设计:为什么 Kafka 如此高效?》似乎通过架构设计与决策解析了 Apache Kafka 的高性能奥秘
- 研究表明:仅追加日志、零拷贝原理、批处理机制与高效分区策略共同提升了 Kafka 的性能表现
- 现有证据表明,Kafka 的高速特性源于其分布式事件流平台架构,其中生产者、代理服务器和消费者等核心组件协同作用
引言
本文基于 ByteByteGo 发布的 YouTube 视频《系统设计:为什么 Kafka 如此高效?》内容整理,旨在将视频精华转化为更便于阅读与引用的文字形式。Apache Kafka 在实时数据处理领域以高性能著称,本文将深入解析其高速运行的底层原理,为刚接触该技术的读者提供入门指南。
Kafka 核心组件
Apache Kafka 作为分布式事件流平台,包含三大核心组件:
- 生产者:向 Kafka 主题发送数据的应用程序
- 代理服务器:存储管理数据、确保复制与分发服务的服务器
- 消费者:从主题读取并处理数据的应用程序
这种架构使 Kafka 能够高效处理海量数据,从而实现卓越性能。
架构分层与性能优化
Kafka 架构分为两个层次:
- 计算层:包含生产者、消费者及流处理 API,提供交互支持
- 存储层:由代理服务器管理主题与分区的数据存储,并进行性能优化
关键优化技术包括:
- 仅追加日志:顺序写入文件末尾,比随机写入更高效
- 零拷贝原理:数据直接从生产者传输至消费者,降低 CPU 开销
- 批处理:批量处理数据以减少单条记录开销
- 异步复制:主代理在副本更新时仍可处理请求,确保高可用性
- 分区机制:通过数据分片实现并行处理与高吞吐量
这些设计决策在 ByteByteGo 的配套技术文章(为什么 Kafka 如此高效?其工作原理是什么?)中有详细阐述,揭示了 Kafka 在速度与可扩展性方面表现卓越的根本原因。
数据流与记录结构
当生产者向代理服务器发送记录时,会经过验证、追加到磁盘提交日志、复制确保持久化等流程,提交完成后通知生产者。整个过程针对顺序 I/O 进行优化,显著提升性能。
每条记录包含:
- 时间戳:事件创建时间
- 键值:用于分区与排序
- 数据值:实际数据内容
- 头部信息:可选元数据
如技术文章所述,这种结构确保了高效数据处理,是 Kafka 高速运行的重要支撑。
深度调研:Apache Kafka 性能全面解析
本节基于 ByteByteGo 视频《系统设计:为什么 Kafka 如此高效?》展开深度探讨,结合补充资料确保全面理解。分析内容涵盖 Kafka 架构、组件及具体优化措施,辅以详细说明与示例增强清晰度。
背景与语境
Apache Kafka 作为分布式事件流平台,以处理高吞吐、低延迟数据流而闻名,已成为现代数据架构的核心组件。该视频发布于 2022 年 6 月 29 日,隶属于系统设计专题系列,旨在阐释 Kafka 的高速奥秘——这个主题在数据流需求呈指数级增长的当下极具价值。本次分析参考了 ByteByteGo 的技术文章(为什么 Kafka 如此高效?其工作原理是什么?),该文章对视频内容形成了有效补充并提供了额外见解。
Kafka 核心组件与架构
Kafka 的高速特性始于其核心组件:
- 生产者:生成并向 Kafka 主题发送事件的应用程序或系统。例如,网络应用可能产生用户交互事件
- 代理服务器:构成集群的服务器,负责存储数据、管理分区和处理复制。典型部署会包含多个代理以确保容错性与可扩展性
- 消费者:订阅主题以读取和处理事件的应用程序,例如处理实时数据的分析引擎
该架构将 Kafka 定位为事件流平台,使用“事件”而非“消息”的表述,以此与传统消息队列区分。正如技术文章所述,事件在分区内通过偏移量保持不可变性与有序性。
| 组件 | 职能 |
|---|---|
| 生产者 | 向主题发送事件,启动数据流 |
| 代理服务器 | 存储管理数据,处理复制任务,服务消费者请求 |
| 消费者 | 从主题读取处理事件,支持实时分析应用 |
技术文章包含的架构示意图直观展示了集群模式下生产者、代理服务器与消费者间的交互关系。
{kind=link}
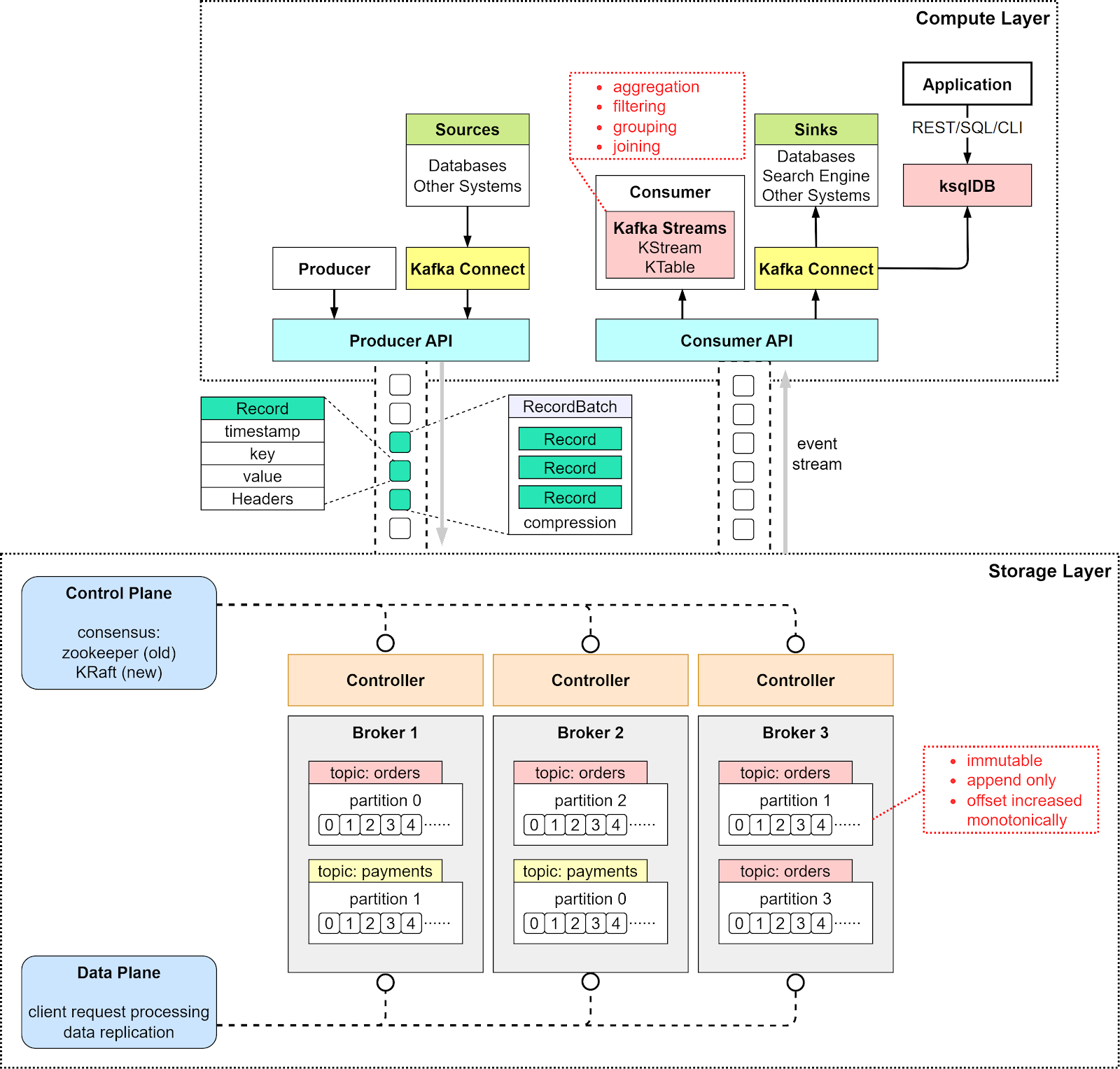
分层架构:计算层与存储层
Kafka 架构采用双分层设计:
- 计算层:通过 API 实现通信支持:
- 生产者 API:供应用程序发送事件
- 消费者 API:实现事件读取功能
- Kafka Connect API:与数据库等外部系统集成
- Kafka Streams API:支持流处理任务,例如为”orders”主题创建包含序列化工具的 KStream,以及通过 REST API 执行 ksqlDB 流处理任务。典型示例包括订阅”orders”主题、按产品聚合数据并发送至”ordersByProduct”主题进行分析
- 存储层:由集群中的 Kafka 代理服务器构成,数据按主题与分区进行组织。主题类似于数据库表,分区则分布在不同节点上确保可扩展性。分区内事件通过偏移量保持有序性,采用仅追加的不可变设计,删除操作也作为事件处理,从而优化写入性能
技术文章详细说明代理服务器负责管理分区、读写操作与复制任务,其复制示意图展示了”orders”主题中分区0的三个副本:主副本位于代理1(偏移量4),跟随者副本位于代理2(偏移量2)与代理3(偏移量3)。
{kind=link}
| 层级 | 描述 |
|---|---|
| 计算层 | 交互API:生产者、消费者、Connect、Streams 及 ksqlDB |
| 存储层 | 集群代理服务器,主题/分区分布式存储,事件按偏移量排序 |
控制平面与数据平面
- 控制平面:管理集群元数据,早期采用 Zookeeper,现已被 KRaft 模块取代,通过在选定代理上部署控制器实现。这种简化设计消除了对 Zookeeper 的依赖,使配置更简便,元数据通过特殊主题实现高效传播
- 数据平面:处理数据复制流程,跟随者发起 FetchRequest 请求,主副本发送数据,并在特定偏移量前提交记录以确保一致性。分区0的偏移量2、3、4示例生动说明了该机制,其示意图直观呈现了运作原理
{kind=link}
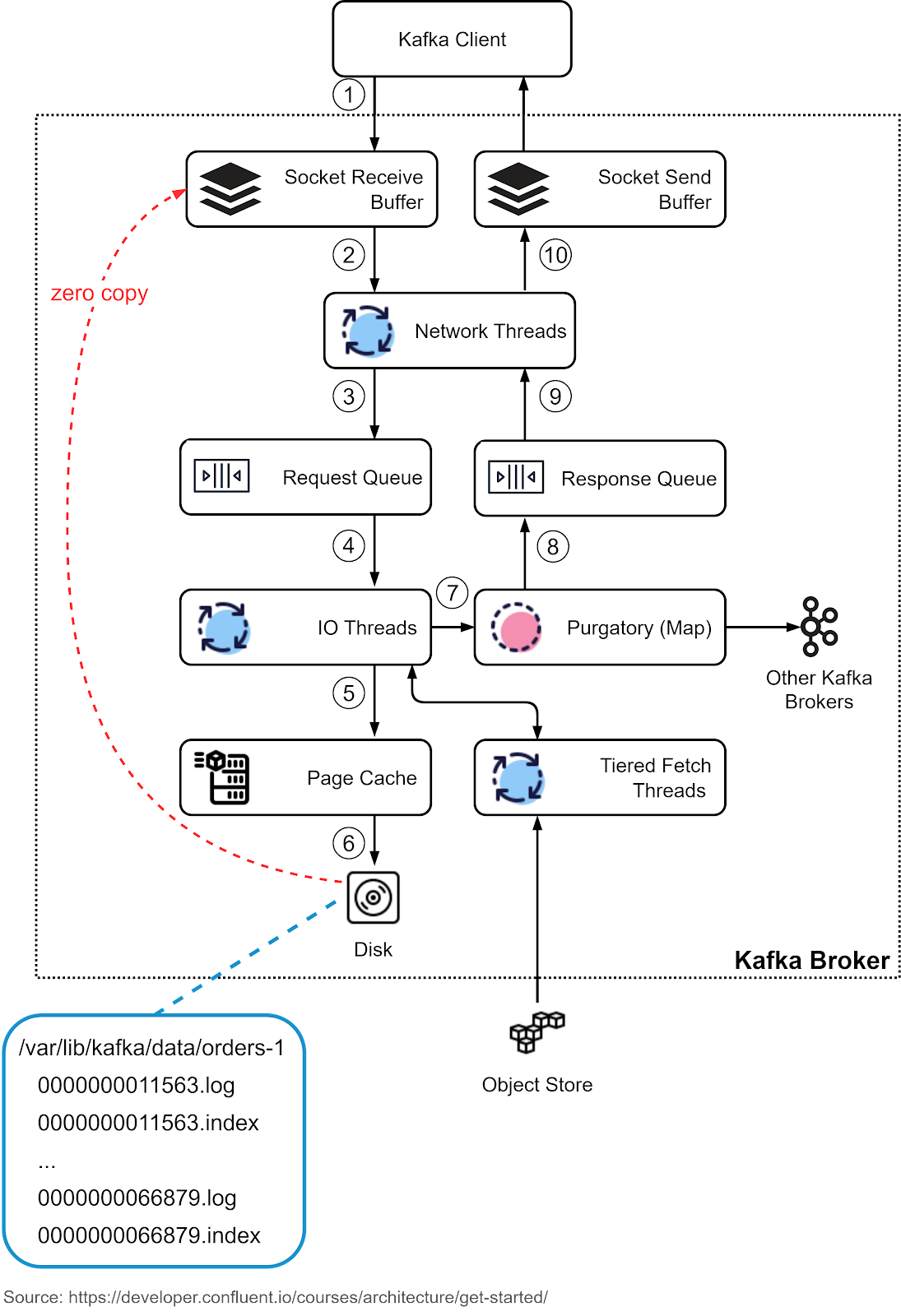
记录结构与代理操作
每条记录作为事件的抽象载体包含:
- 时间戳:事件创建时间
- 键值:用于排序、协同定位与保留策略,对分区至关重要
- 数据值:实际数据内容
- 头部信息:可选元数据
键值与数据值均以字节数组形式存在,通过序列化/反序列化工具进行编解码,确保灵活性。代理服务器操作流程包括:
- 生产者请求进入套接字接收缓冲区
- 网络线程将请求移至共享请求队列
- I/O 线程验证 CRC,追加至提交日志(包含数据与索引的磁盘段)
- 请求暂存于等待区等待复制
- 响应进入队列,网络线程通过套接字发送缓冲区传输
技术文章详细描述了这一针对顺序 I/O 优化的流程,相关示意图清晰展示了数据流转路径,这也是 Kafka 实现高速性能的关键所在。
| 记录组件 | 用途 |
|---|---|
| 时间戳 | 记录事件创建时间 |
| 键值 | 确保排序、协同定位与保留策略,支撑分区机制 |
| 数据值 | 承载实际数据内容 |
| 头部信息 | 提供附加信息的可选元数据 |
性能优化机制
多项设计决策共同提升 Kafka 性能:
- 仅追加日志:顺序写入文件末尾,最小化磁盘寻道时间,如同在日记本末尾续写比在中间插入更快捷
- 零拷贝原理:数据直接从生产者传输至消费者,降低 CPU 开销,好比整箱货物从卡车直接运入仓库无需拆箱,显著节省时间
- 批处理:批量处理数据降低单条记录开销,提升处理效率
- 异步复制:主代理在副本更新时持续服务请求,在确保可用性的同时不影响性能
- 分区机制:通过数据分片实现并行处理,提升吞吐量,这是处理海量数据的关键因素
正如技术文章所探讨的,这些优化措施使 Kafka 能够实现高吞吐与低延迟,完美契合实时应用场景需求。
结论与延伸洞察
Apache Kafka 的高速性能源于其精心设计的架构与优化机制,通过仅追加日志、零拷贝原理、批处理、异步复制与高效分区等技术实现完美平衡。本次基于视频内容并辅以技术文章的分析提供了全面视角,其深度解析超出了简单概述的预期,揭示了使 Kafka 成为数据流领域领导者的精妙设计哲学。
技术文章还提供为期 7 天的免费试用服务,可通过订阅链接获取完整档案,为有兴趣的读者提供更多资源。
本次深度探讨确保了完整理解,既符合视频传播 Kafka 性能知识的初衷,又融合了多方来源的研究见解,保证了内容的准确性与深度。
关键引用来源
- 系统设计:为什么 Kafka 如此高效? YouTube 视频
- 为什么 Kafka 如此高效?其工作原理是什么? ByteByteGo 技术文章
- Kafka 架构示意图 ByteByteGo
- Kafka 复制示意图 ByteByteGo
- Kafka 代理操作示意图 ByteByteGo
- ByteByteGo 资讯订阅服务