LLM-Kosten, Agenten und Codierungswerkzeuge | Original, von KI übersetzt
Inhaltsverzeichnis
- Optimierung der LLM-API-Kosten
- Beginnen Sie mit kostengünstigen Modellen
- Vermeiden Sie unnötige Nutzung hochpreisiger Modelle
- Bevorzugen Sie NLP-Bibliotheken für einfache Aufgaben
- Erstellen Sie spezialisierte Agenten für Effizienz
- Vergleichen Sie Modelle durch umfangreiche Tests
- API-Nutzung von Deepseek und Mistral
- DeepSeek-Kosten skalieren mit Cache-Misses
- Ausgabe-Tokens dominieren Mistral-Kosten
- Grok-Preise begünstigen stark Eingabe-Tokens
- Token-Nutzung variiert nach Aufgabenkomplexität
- Preise entsprechen dokumentierten Sätzen
- Allgemeine Agenten vs. Spezialisierte Agenten
- Allgemeine Agenten scheitern an Komplexität
- Spezialisierte Agenten glänzen in Fachgebieten
- Workflow-Tools schränken Flexibilität ein
- Benutzerdefinierte Python-Agenten bieten Kontrolle
- Abwägung zwischen Komfort und Leistung
- Die Meinung eines wählerischen Ingenieurs zu KI-Codierungstools
- Praktischer Nutzen über Markenhype
- VSCode + Copilot bleibt zuverlässig
- Claude Code beeindruckt mit Diff-Artigen Änderungen
- Grammatik-Tools erfordern manuelle Überprüfung
- Experimentieren schlägt blinde Übernahme
Optimierung der LLM-API-Kosten
2025.08
 Quelle: openrouter.ai
Quelle: openrouter.ai
 Quelle: openrouter.ai
Quelle: openrouter.ai
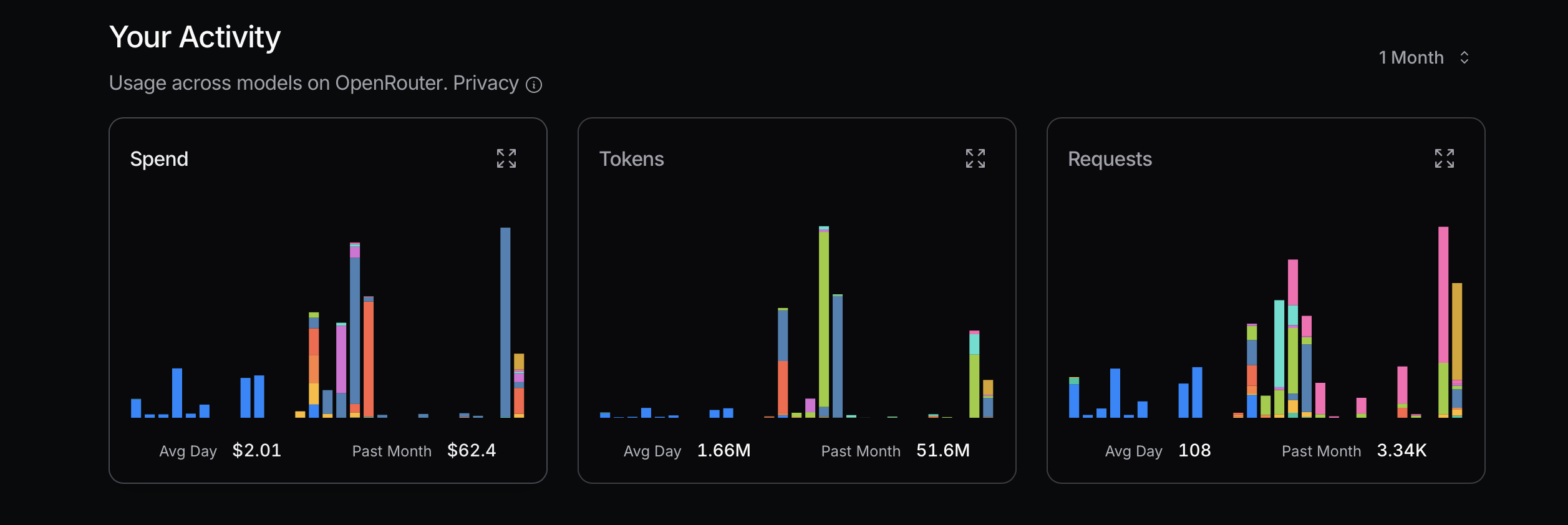
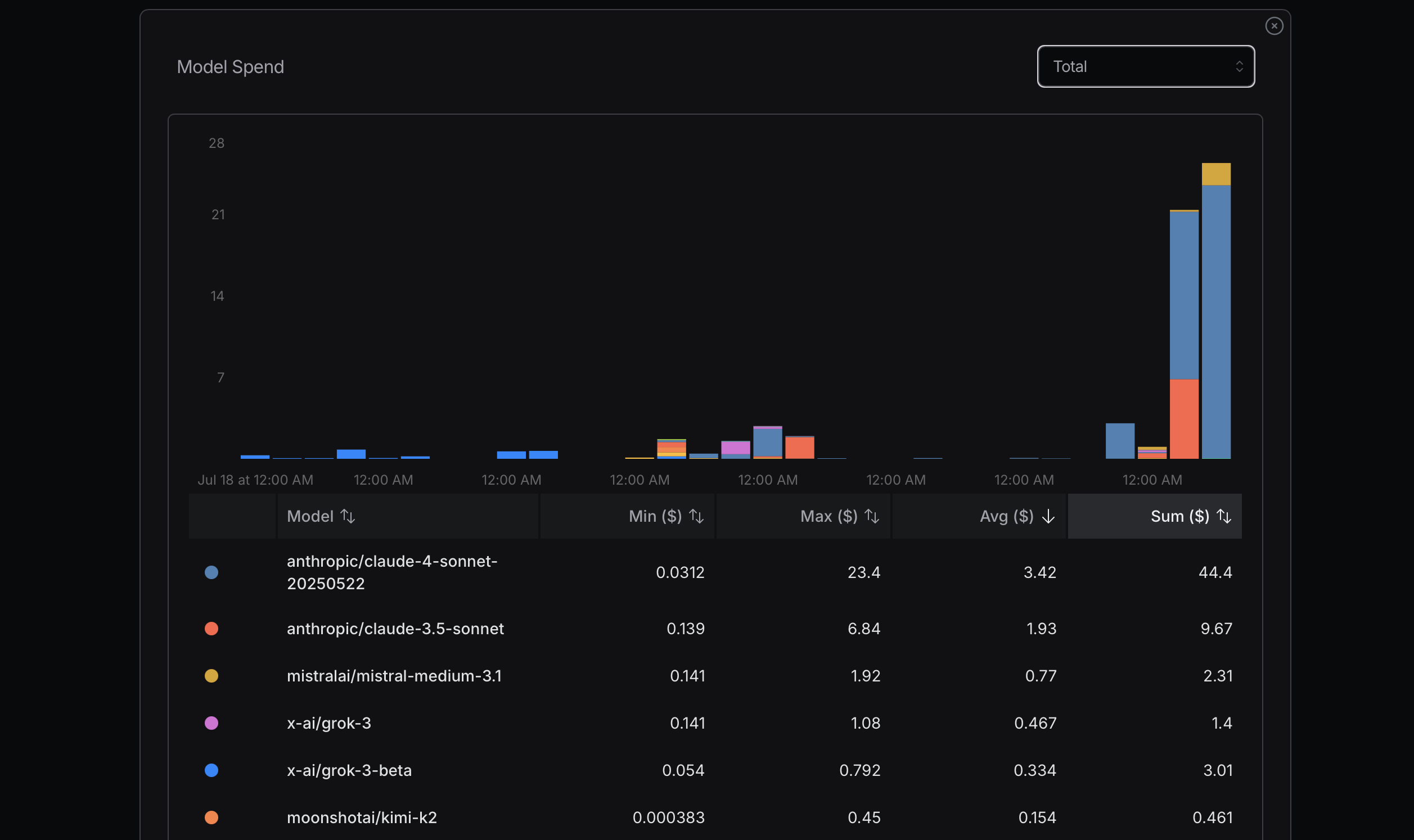
Bei der Optimierung der Token-Nutzung ist es ratsam, mit kostengünstigeren Modellen zu beginnen. Sollten Probleme auftreten, können Sie auf fortschrittlichere Modelle wechseln. Mistral, Gemini Flash und DeepSeek sind in der Regel wirtschaftlich, während Claude Sonnet meist teurer ist. Es ist wichtig zu verstehen, wie Claude Code die unten gezeigten Router nutzt.
In meiner jüngsten Erfahrung habe ich aufgrund der Missachtung dieses Prinzips hohe Kosten verursacht. Ich versuchte, meine maximale Nutzung zu erreichen, um die Kosten zu ermitteln, was keine rationale Herangehensweise ist; es handelt sich um eine einfache Berechnung. Brauche ich beispielsweise wirklich Sonnet 4? Nicht unbedingt. Obwohl ich es als ein fortgeschritteneres Modell von Anthropic wahrnehme und es auf OpenRouter hoch bewertet wird, bin ich mir über die Unterschiede zwischen Sonnet 4 und Sonnet 3.5 nicht im Klaren.
Ich habe etwas Wertvolles aus einem kürzlichen Interview mit dem Replit-Gründer Amjad Masad gelernt. Für viele Aufgaben sind hoch entwickelte Modelle nicht notwendig. Idealerweise wäre es perfekt, wenn wir die LLM-API überhaupt nicht nutzen müssten. Bestimmte NLP-Bibliotheken sind für einfachere Aufgaben effektiv; zum Beispiel ist HanLP hervorragend für chinesische Sprachaufgaben geeignet.
Darüber hinaus können wir benutzerdefinierte oder spezialisierte Agenten entwickeln, um Aufgaben von Anfang an effizient zu bewältigen. Claude Code ist möglicherweise nicht immer die beste oder kostengünstigste Lösung für jede Aufgabe.
Eine Möglichkeit, die Unterschiede zwischen Modellen zu erkennen, besteht darin, sie intensiv zu nutzen und ihre Leistung zu vergleichen. Nach einiger Zeit der Nutzung von Gemini 2.5 Flash finde ich es weniger leistungsfähig als Sonnet 4.
Nach einigen Tagen verwende ich die folgende Konfiguration zur Unterstützung. Der Parameter longContextThreshold ist wirklich wichtig. Sie können die Konsole von Claude Code regelmäßig leeren oder neu starten. Es ist sehr einfach, den Langzeit-Kontext-Schwellenwert zu erreichen, wenn Sie Claude Code zum Schreiben von Code verwenden.
{
"PROXY_URL": "http://127.0.0.1:7890",
"LOG": true,
"Providers": [
{
"name": "openrouter",
"api_base_url": "https://openrouter.ai/api/v1/chat/completions",
"api_key": "",
"models": [
"moonshotai/kimi-k2",
"anthropic/claude-sonnet-4",
"anthropic/claude-3.5-sonnet",
"anthropic/claude-3.7-sonnet:thinking",
"anthropic/claude-opus-4",
"google/gemini-2.5-flash",
"google/gemini-2.5-pro",
"deepseek/deepseek-chat-v3-0324",
"deepseek/deepseek-chat-v3.1",
"deepseek/deepseek-r1",
"mistralai/mistral-medium-3.1",
"qwen/qwen3-coder",
"openai/gpt-oss-120b",
"openai/gpt-5",
"openai/gpt-5-mini",
"x-ai/grok-3-mini",
"x-ai/grok-4"
],
"transformer": {
"use": [
"openrouter"
]
}
}
],
"Router": {
"default": "openrouter,x-ai/grok-4",
"background": "openrouter,deepseek/deepseek-chat-v3.1",
"think": "openrouter,qwen/qwen3-coder",
"longContext": "openrouter,moonshotai/kimi-k2",
"longContextThreshold": 2000,
"webSearch": "openrouter,mistralai/mistral-medium-3.1"
}
}
Allgemeine Agenten vs. Spezialisierte Agenten
2025.08
Manus wird als allgemeines KI-Agenten-Tool beworben, aber es funktioniert wahrscheinlich nicht so gut.
Ein Grund ist, dass es sehr langsam ist, viel unnötige Arbeit verrichtet und ineffizient ist. Ein weiterer Grund ist, dass es bei komplexen Problemen oder Schwachstellen wahrscheinlich bei der Aufgabenerfüllung scheitert.
Spezialisierte Agenten funktionieren hervorragend, weil sie hochgradig spezialisiert sind. Sie sind für sehr spezifische Aufgaben konzipiert. Es gibt Dutzende von Datenbanken und über hundert Webentwicklungs-Frameworks wie Spring. Es gibt auch zahlreiche Web-Frameworks wie Vue oder React.
Dify konzentriert sich darauf, KI zu nutzen, um Workflows zu verbinden, und verwendet eine Drag-and-Connect-Methode zur Definition von KI-Workflows. Sie müssen viel tun, um Informationen, Daten und Plattformen zu verbinden.
Ich habe auch einige einfache Agenten erstellt, wie einen Python-Code-Refactoring-Agenten, einen Grammatik-Korrektur-Agenten, einen Bugfix-Agenten und einen Aufsatz-Zusammenführungs-Agenten.
Code ist sehr flexibel. Daher deckt Dify nur einen kleinen Teil des möglichen Ideenspektrums ab.
Manus führt Aufgaben aus und zeigt Benutzern, wie es funktioniert, indem es eine VNC-Methode verwendet, um einen Computer anzuzeigen.
Ich denke, die Zukunft wird sich auf diese beiden Ansätze einpendeln.
Bei Manus müssen Sie Code oder Text hochladen, um Aufgaben auszuführen, was nicht bequem ist. Bei Dify müssen Sie Workflows mit Drag-and-Drop erstellen, ähnlich wie bei MIT Scratch.
Warum ist Scratch nicht so beliebt wie Python? Weil Sie mit Python so viele Dinge tun können, während Scratch auf einfache Programme zu Bildungszwecken beschränkt ist.
Dify hat wahrscheinlich ähnliche Einschränkungen.
Manus kann viele einfache Aufgaben bewältigen. Bei einigen Aufgaben, insbesondere solchen, die die Schwächen von Manus treffen, wird es jedoch scheitern.
Auch viele Programme oder Dienste brauchen Zeit zur Einrichtung. In Manus’ Ansatz ist dieser Prozess langsam.
Als Programmierer nutze ich KI mit Python, um meine spezialisierten Agenten zu erstellen. Dies ist der einfachste Ansatz für mich. Ich kann auch Prompts und Kontexte einrichten, um eine relativ stabile Ausgabe der LLM-APIs sicherzustellen.
Manus und Dify werden ebenfalls mit diesen LLM-APIs erstellt. Ihr Vorteil ist, dass sie bereits viele Tools oder Code zur Verfügung haben.
Wenn ich einen Twitter-Bot-Agenten erstellen möchte, ist die Verwendung von Dify möglicherweise bequemer, als einen mit Open-Source-Technologien selbst zu erstellen.
Die Meinung eines wählerischen Ingenieurs zu KI-Codierungstools
2025.08
Kürzlich habe ich Claude Code erfolgreich ausgeführt und möchte meine Reise der Tool-Auswahl teilen. Dabei habe ich auch einige KI-Tool-Tipps gesammelt.
Ich habe Claude Code relativ spät übernommen.
Claude Code wurde Ende Februar 2025 veröffentlicht.
Mein Versuch, es zu nutzen, gelang erst vor kurzem. Ein Grund ist, dass es die Anthropic-API erfordert, die keine chinesischen Visa-Karten unterstützt.
Ein weiterer Grund ist, dass Claude Code Router verfügbar wurde, was meinen jüngsten Versuch erfolgreich machte.
Ich höre immer wieder Lob dafür. Ich habe die Gemini CLI im Juli 2025 ausprobiert, aber nach mehreren fehlgeschlagenen Versuchen, meinen Code reparieren zu lassen, aufgegeben.
Ich habe auch Aider ausprobiert, einen weiteren Software-Agenten. Ich habe Cursor nach etwa sechs Monaten nicht mehr genutzt, da viele seiner VSCode-basierten Plugins nicht funktionierten. Außerdem möchte ich Cursor nicht zu viel Anerkennung zollen, da es auf VSCode aufbaut. Da das Copilot-Plugin in VSCode sich kürzlich verbessert hat und nicht weit zurückliegt, bevorzuge ich es öfter zu nutzen.
Allerdings basiert VSCode auf Electron, einer Open-Source-Technologie. Es ist schwierig, die richtige Team oder Person anzuerkennen. Da viele große Unternehmen und Startups von Open-Source-Projekten profitieren, muss ich mich auf mein Budget und das konzentrieren, was für mich am besten funktioniert. Ich sollte mich nicht zu sehr um Anerkennung sorgen. Ich bevorzuge günstige und effektive Tools.
Ich habe kurz mit Cline experimentiert, aber es nicht übernommen.
Ich nutze das Copilot-Plugin in VSCode mit einem angepassten Modell, Grok 3 Beta über OpenRouter, was gut funktioniert.
Ich glaube nicht, dass Claude Code meine Gewohnheiten ändern wird, aber da ich es erfolgreich ausführen kann und die Geduld habe, es ein paar Mal auszuprobieren, werde ich sehen, wie ich mich in den kommenden Wochen fühle.
Ich bin ein wählerischer Benutzer mit 10 Jahren Erfahrung in der Softwareentwicklung. Ich hoffe, dass Tools im tatsächlichen Einsatz großartig sind. Ich kaufe nicht in Marken ein – mir ist nur der tägliche Nutzen wichtig.
Nachdem ich Claude Code zur Grammatikkorrektur dieses Beitrags verwendet habe, habe ich festgestellt, dass es in bestimmten Szenarien gut funktioniert. Obwohl ich KI für Grammatikhilfe schätze (ich habe sogar ein Python-Skript geschrieben, das LLM-APIs dafür aufruft), habe ich ein frustrierendes Muster bemerkt – selbst wenn ich minimale Korrekturen anfordere, bieten die Tools zahlreiche Grammatikvorschläge zur Überprüfung an. Dieser manuelle Überprüfungsprozess macht den Zweck der Automatisierung zunichte. Als Kompromiss lasse ich KI nun ganze Aufsätze bearbeiten, obwohl dieser Ansatz meine Lernmöglichkeiten begrenzt, da ich die spezifischen Korrekturen nicht sehe.
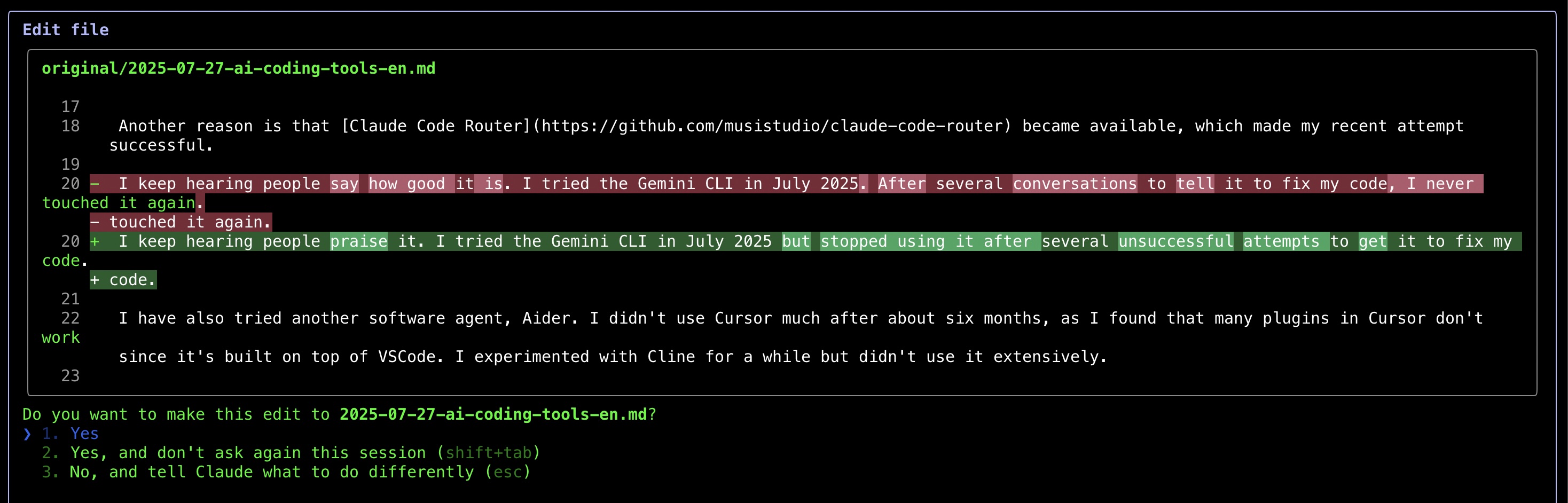
Am meisten beeindruckt hat mich, wie Claude Code Änderungen anzeigt – Vorher-Nachher-Vergleiche ähnlich wie git diffs, was die Überprüfung von Bearbeitungen viel einfacher macht.
Nach einem Tag habe ich Claude auch zur Code-Korrektur verwendet. Dennoch nutze ich weiterhin das Copilot-Plugin mit dem Grok 3 Beta-Modell, da es für mich einfach und bequem ist.
Nach mehreren Tagen der Nutzung von Claude Code muss ich sagen, es ist sehr beeindruckend. Ich mag wirklich, wie es meinen Code korrigiert.
 Quelle: Eigenes Screenshot
Quelle: Eigenes Screenshot
 Quelle: Eigenes Screenshot
Quelle: Eigenes Screenshot
 Quelle: Eigenes Screenshot
Quelle: Eigenes Screenshot
API-Nutzung von Deepseek und Mistral
2025.01.25
DeepSeek
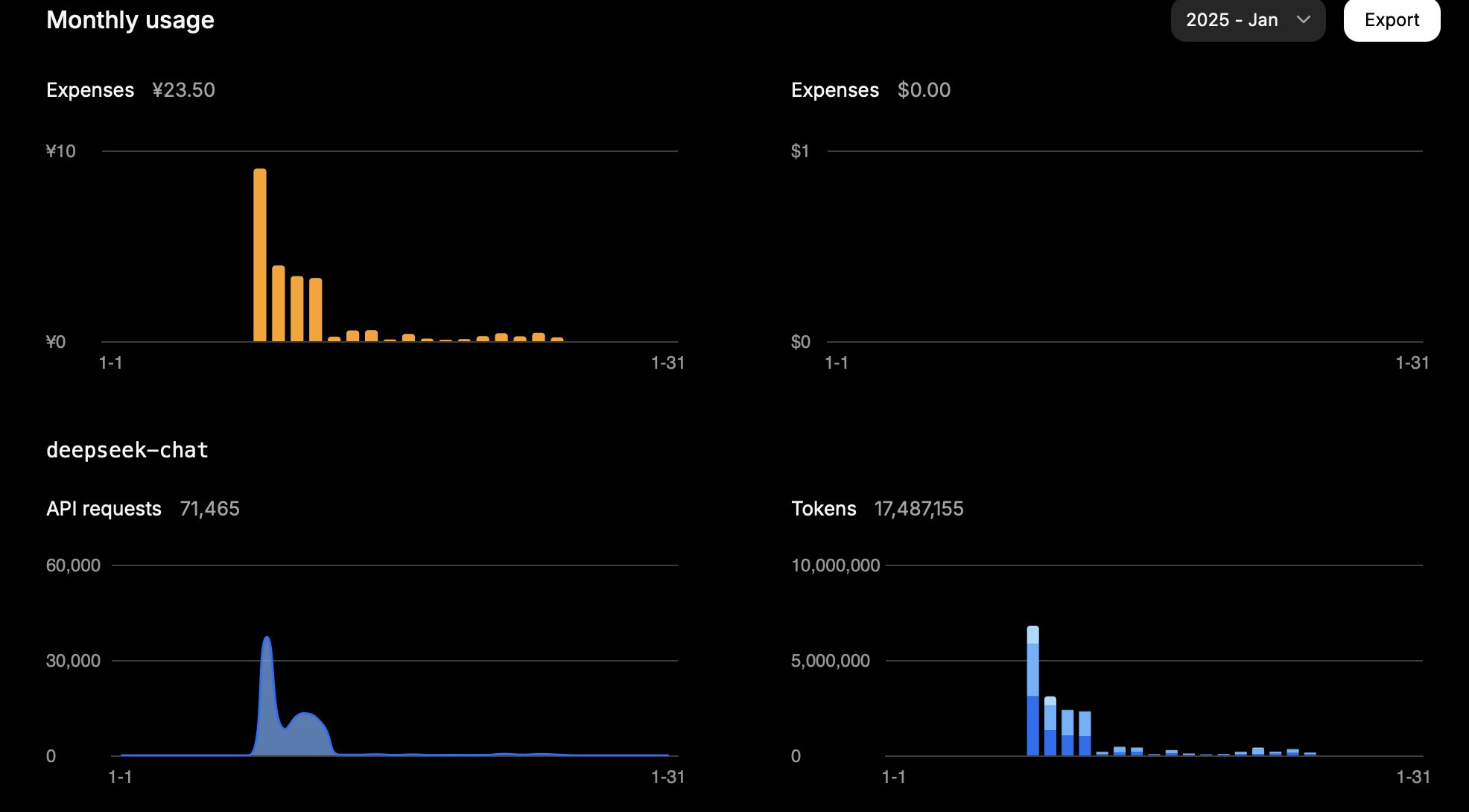
In einem Monat kosteten mich 15 Millionen Token ungefähr 23,5 CNY.
Dies war meine Nutzung an einem Tag:
| Typ | Tokens |
|---|---|
| Eingabe (Cache Hit) | 946.816 |
| Eingabe (Cache Miss) | 2.753.752 |
| Ausgabe | 3.100.977 |
Die Berechnung lautet wie folgt:
0,94 * 0,1 + 2,75 * 1 + 3,10 * 2 = 11,83
Abhängig von der Aufgabe hängt die Token-Nutzung weitgehend von der Eingabe (Cache Miss) und der Ausgabe ab.
Dieses Ergebnis entspricht den erwarteten Kosten.
 Quelle: Eigenes Screenshot
Quelle: Eigenes Screenshot
Mistral
Die Preise für Mistral-Modelle lauten wie folgt:
| Modell | Eingabe (USD pro Million Tokens) | Ausgabe (USD pro Million Tokens) |
|---|---|---|
mistral-large-2411 |
2 | 6 |
mistral-small-latest |
0,2 | 0,6 |
An einem Tag war die Nutzung meines Mistral-Kontos wie folgt (Modell: mistral-large-2411):
| Typ | Tokens | Kosten (USD) |
|---|---|---|
| Gesamt | 772.284 | 3,44 |
| Ausgabe | 474.855 | 2,85 |
| Eingabe | 297.429 | 0,59 |
Für das Modell mistral-small-2409 betrug die Gesamtnutzung 1.022.407 Tokens.
Angenommen, ein Drittel davon waren Eingabe-Tokens und zwei Drittel Ausgabe-Tokens:
Es gab 340.802 Eingabe-Tokens und 681.605 Ausgabe-Tokens.
Daher werden die Gesamtkosten wie folgt berechnet: 340.802 * 0,2 / 1.000.000 + 681.605 * 0,6 / 1.000.000 = 0,07 + 0,41 = 0,48 USD.
Die Mistral-Konsole meldet Gesamtnutzungskosten von 0,43 USD, was ungefähr unserer Berechnung entspricht.
Grok
| Modell | Eingabe (USD pro Million Tokens) | Ausgabe (USD pro Million Tokens) |
|---|---|---|
grok-2-latest |
2 | 10 |