Costos de LLM, Agentes y Herramientas de Codificación | Original, traducido por IA
Índice
- Optimización de costos de API de LLM
- Comienza con modelos rentables primero
- Evita el uso innecesario de modelos avanzados
- Prefiere bibliotecas NLP para tareas simples
- Construye agentes especializados para eficiencia
- Compara modelos mediante pruebas extensivas
- Uso de API de Deepseek y Mistral
- Los costos de DeepSeek escalan con fallos de caché
- Los tokens de salida dominan los gastos de Mistral
- El precio de Grok favorece mucho los tokens de entrada
- El uso de tokens varía según la complejidad de la tarea
- Los precios se alinean con las tarifas documentadas
- Agentes generales vs agentes verticales
- Los agentes generales luchan con la complejidad
- Los agentes verticales sobresalen en especialización
- Las herramientas de flujo de trabajo limitan la flexibilidad
- Los agentes personalizados en Python ofrecen control
- Compromisos entre conveniencia y potencia
- La opinión de un ingeniero exigente sobre herramientas de IA para codificación
- Prefiero utilidad práctica sobre el hype de marca
- VSCode + Copilot sigue siendo confiable
- Claude Code impresiona con ediciones estilo diff
- Las herramientas de gramática requieren verificación manual
- La experimentación supera la adopción ciega
Optimización de costos de API de LLM
2025.08
 Fuente: openrouter.ai
Fuente: openrouter.ai
 Fuente: openrouter.ai
Fuente: openrouter.ai
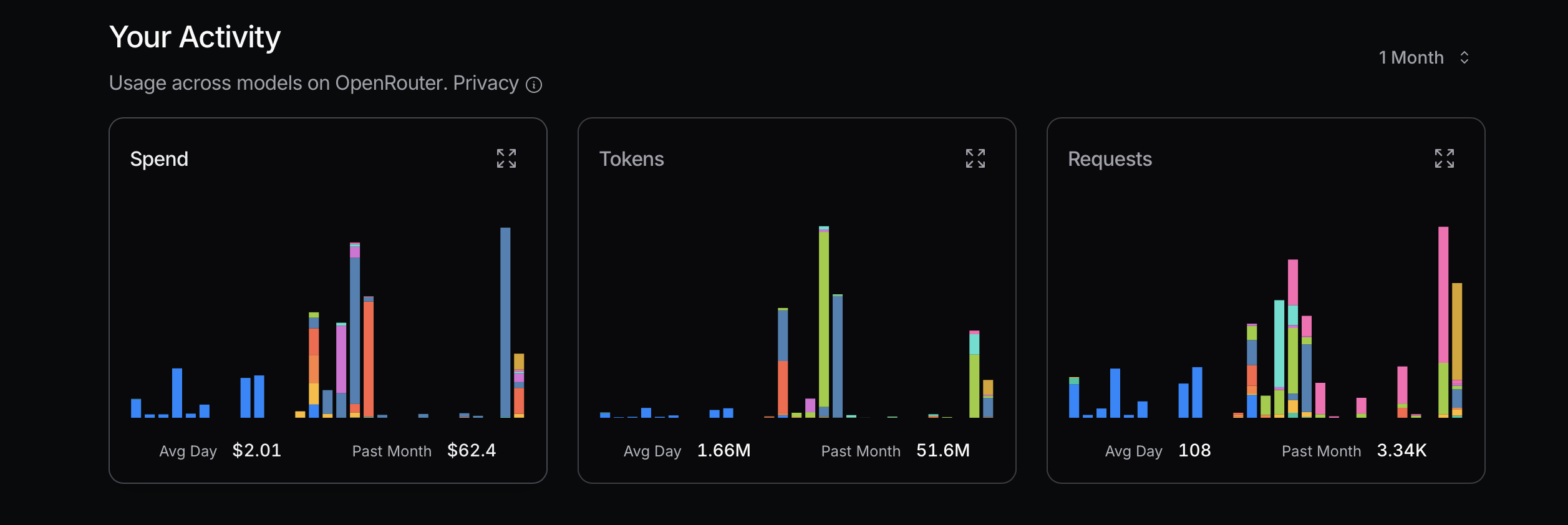
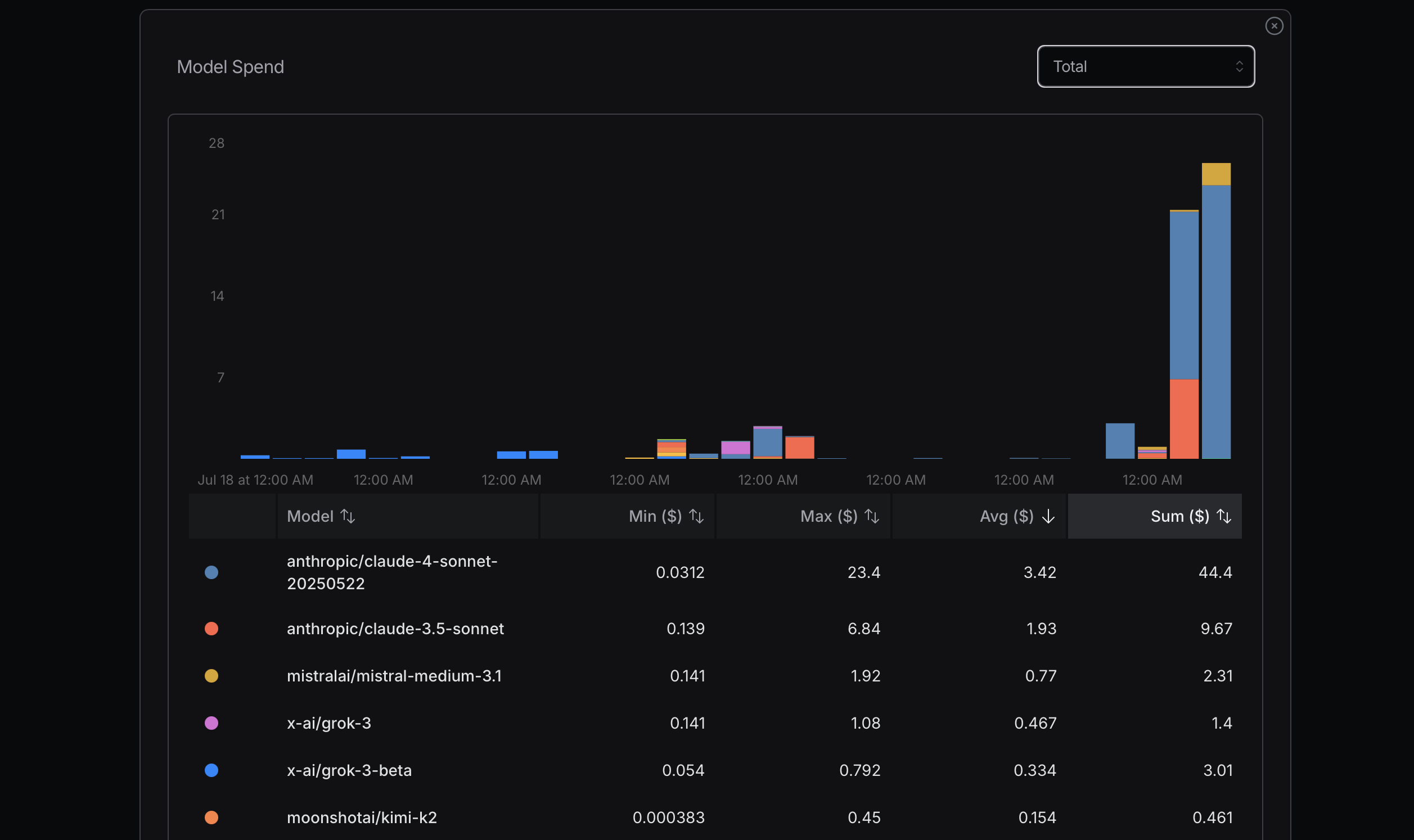
Al optimizar el uso de tokens, es recomendable comenzar con modelos más rentables. Si surgen problemas, considera actualizar a modelos más avanzados. Mistral, Gemini Flash y DeepSeek suelen ser económicos, mientras que Claude Sonnet generalmente es más costoso. Es crucial entender cómo Claude Code utiliza los enrutadores mostrados a continuación.
En mi experiencia reciente, incurrí en costos significativos por descuidar este principio. Intentaba alcanzar mi uso máximo para determinar el costo, lo cual no es un enfoque racional; es un cálculo simple. Por ejemplo, ¿realmente necesito Sonnet 4? No necesariamente. Aunque lo percibo como un modelo más avanzado de Anthropic y tiene una alta clasificación en OpenRouter, no tengo claro las diferencias entre Sonnet 4 y Sonnet 3.5.
Aprendí algo valioso de una entrevista reciente con el fundador de Replit, Amjad Masad. Para muchas tareas, los modelos altamente avanzados no son necesarios. Idealmente, si podemos evitar usar la API de LLM por completo, sería perfecto. Ciertas bibliotecas NLP son efectivas para tareas más simples; por ejemplo, HanLP sobresale en tareas de idioma chino.
Además, podemos desarrollar agentes personalizados o especializados para manejar tareas de manera eficiente desde el principio. Claude Code puede no ser siempre la mejor o más rentable solución para cada tarea.
Una forma de discernir las diferencias entre modelos es usarlos extensamente y comparar su desempeño. Después de algún tiempo usando Gemini 2.5 Flash, encuentro que es menos capaz que Sonnet 4.
Después de unos días, uso la configuración a continuación para ayudar. El parámetro longContextThreshold es realmente importante. Puedes limpiar periódicamente la consola de Claude Code o reiniciarla. Es muy fácil alcanzar el umbral de contexto largo cuando usas Claude Code para escribir código.
{
"PROXY_URL": "http://127.0.0.1:7890",
"LOG": true,
"Providers": [
{
"name": "openrouter",
"api_base_url": "https://openrouter.ai/api/v1/chat/completions",
"api_key": "",
"models": [
"moonshotai/kimi-k2",
"anthropic/claude-sonnet-4",
"anthropic/claude-3.5-sonnet",
"anthropic/claude-3.7-sonnet:thinking",
"anthropic/claude-opus-4",
"google/gemini-2.5-flash",
"google/gemini-2.5-pro",
"deepseek/deepseek-chat-v3-0324",
"deepseek/deepseek-chat-v3.1",
"deepseek/deepseek-r1",
"mistralai/mistral-medium-3.1",
"qwen/qwen3-coder",
"openai/gpt-oss-120b",
"openai/gpt-5",
"openai/gpt-5-mini",
"x-ai/grok-3-mini"
],
"transformer": {
"use": [
"openrouter"
]
}
}
],
"Router": {
"default": "openrouter,openai/gpt-5-mini",
"background": "openrouter,google/gemini-2.5-flash",
"think": "openrouter,qwen/qwen3-coder",
"longContext": "openrouter,deepseek/deepseek-chat-v3.1",
"longContextThreshold": 2000,
"webSearch": "openrouter,mistralai/mistral-medium-3.1"
}
}
Agentes generales vs agentes verticales
2025.08
Manus afirma ser una herramienta de agente de IA general, pero probablemente no funcione tan bien.
Una razón es que es muy lento, haciendo mucho trabajo innecesario y siendo ineficiente. Otra razón es que si encuentra un problema complejo o golpea un punto débil, es probable que fallen en su tarea.
Los agentes verticales funcionan genial porque están altamente especializados. Están diseñados para tareas muy específicas. Hay docenas de bases de datos y más de cien marcos de desarrollo web como Spring. También hay numerosos marcos web, como Vue o React.
Dify se enfoca en usar IA para conectar flujos de trabajo, empleando un método de arrastrar y conectar para definir flujos de trabajo de IA. Necesitan hacer mucho para conectar información, datos y plataformas.
He construido algunos agentes simples también, como un agente de refactorización de código Python, un agente de corrección gramatical, un agente de corrección de errores y un agente de fusión de ensayos.
El código es muy flexible. Entonces, Dify solo cubre una pequeña porción del espacio de ideas posibles.
Manus realiza tareas y muestra a los usuarios cómo funciona usando un método VNC para mostrar una computadora.
Creo que el futuro se asentará en estos dos enfoques.
Para Manus, necesitas subir código o texto para realizar tareas, lo cual no es conveniente. Con Dify, necesitas construir flujos de trabajo usando arrastrar y soltar, similar a MIT Scratch.
¿Por qué Scratch no es tan popular como Python? Porque con Python puedes hacer muchas cosas, mientras que Scratch está limitado a programas simples con fines educativos.
Dify probablemente tiene limitaciones similares.
Manus puede manejar muchas tareas simples. Sin embargo, para algunas tareas, especialmente aquellas que golpean las debilidades de Manus, fallará.
Además, muchos programas o servicios llevan tiempo configurar. En el enfoque de Manus, este proceso es lento.
Como programador, uso IA con Python para construir mis agentes verticales. Este es el enfoque más simple para mí. También puedo configurar mensajes y contextos para asegurar una salida relativamente estable de las APIs de LLM.
Manus y Dify también están construidos con estas APIs de LLM. Su ventaja es que ya tienen muchas herramientas o código listo para usar.
Si quiero construir un agente bot para Twitter, usar Dify puede ser más conveniente que construirlo yo mismo con tecnologías de código abierto.
La opinión de un ingeniero exigente sobre herramientas de IA para codificación
2025.08
Recientemente, ejecuté Claude Code con éxito, así que quiero compartir mi viaje de selección de herramientas. También he recopilado algunos Consejos de herramientas de IA en el camino.
Fui bastante tardío en adoptar Claude Code.
Claude Code fue lanzado alrededor de finales de febrero de 2025.
No logré probarlo con éxito hasta hace poco. Una razón es que requiere la API de Anthropic, que no admite tarjetas Visa chinas.
Otra razón es que Claude Code Router estuvo disponible, lo que hizo que mi intento reciente tuviera éxito.
Sigo escuchando elogios al respecto. Probé la CLI de Gemini en julio de 2025 pero la abandoné después de varios intentos fallidos de hacer que corrigiera mi código.
También probé Aider, otro agente de software. Dejé de usar Cursor después de unos seis meses porque muchos de sus complementos basados en VSCode fallaban. Además, no quiero darle mucho crédito a Cursor ya que está construido sobre VSCode. Como el complemento Copilot en VSCode ha mejorado recientemente y no se queda muy atrás, prefiero usarlo más a menudo.
Sin embargo, VSCode está construido sobre Electron, una tecnología de código abierto. Es difícil atribuir el crédito al equipo o individuo correcto. Considerando que muchas empresas grandes y startups obtienen ganancias de proyectos de código abierto, debo enfocarme en mi presupuesto y lo que mejor me convenga. No debería preocuparme demasiado por dar crédito. Prefiero usar herramientas asequibles y efectivas.
Brevemente experimenté con Cline pero no lo adopté.
Uso el complemento Copilot en VSCode con un modelo personalizado, Grok 3 beta a través de OpenRouter, que funciona bien.
No creo que Claude Code cambie mis hábitos, pero como puedo ejecutarlo con éxito y tengo la paciencia para probarlo algunas veces más, veré cómo me siento en las próximas semanas.
Soy un usuario exigente con 10 años de experiencia en ingeniería de software. Espero que las herramientas sean geniales en el uso real. No me interesa la marca, solo me importa la utilidad diaria.
Después de usar Claude Code para corregir la gramática de esta publicación, encontré que funciona bien en ciertos escenarios. Aunque aprecio la IA para asistencia gramatical (incluso escribí un script en Python para llamar a las APIs de LLM para este propósito), he notado un patrón frustrante: incluso cuando solicito correcciones mínimas, las herramientas siguen mostrando numerosas sugerencias gramaticales para revisión. Este proceso de verificación manual frustra el propósito de la automatización. Como compromiso, ahora permito que la IA maneje ensayos completos, aunque este enfoque limita mis oportunidades de aprendizaje ya que no veo las correcciones específicas que se están haciendo.
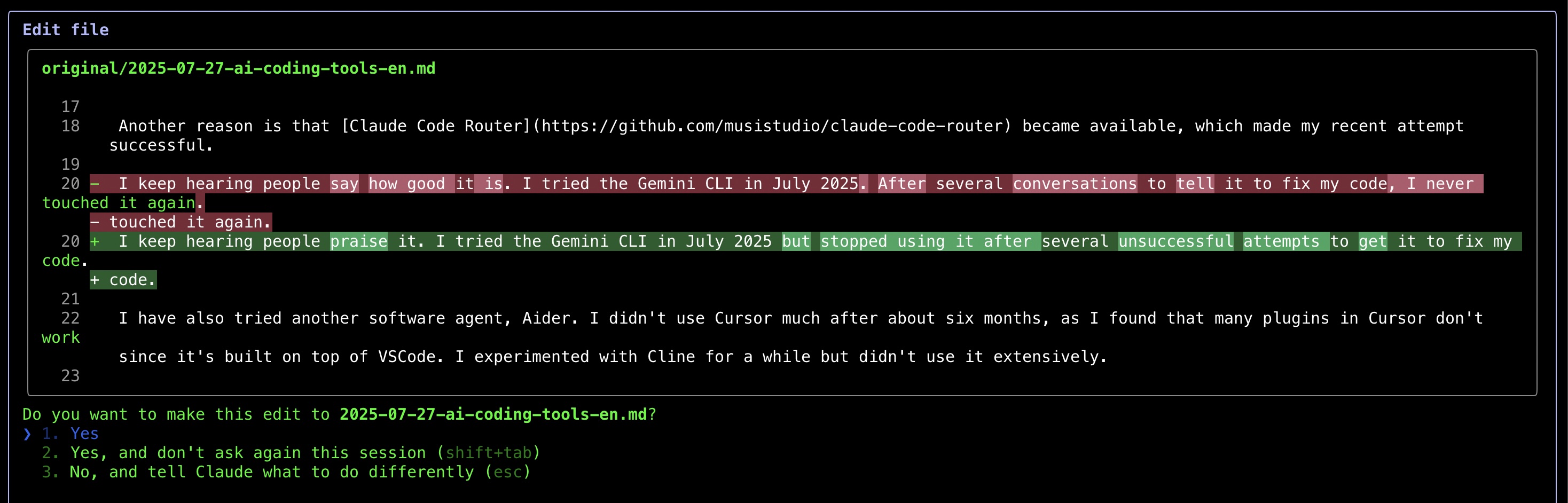
Lo que más me impresionó fue cómo Claude Code muestra los cambios: mostrando comparaciones de antes y después similares a los diffs de git, lo que hace que revisar las ediciones sea mucho más fácil.
Después de un día, usé Claude para corregir algún código también. Sin embargo, sigo usando el complemento Copilot con el modelo Grok 3 beta, ya que es simple y fácil para mí.
Después de usar Claude Code durante varios días, tengo que decir que es muy impresionante. Realmente me gusta cómo corrige mi código.
 Fuente: Captura propia
Fuente: Captura propia
 Fuente: Captura propia
Fuente: Captura propia
 Fuente: Captura propia
Fuente: Captura propia
Uso de API de Deepseek y Mistral
2025.01.25
DeepSeek
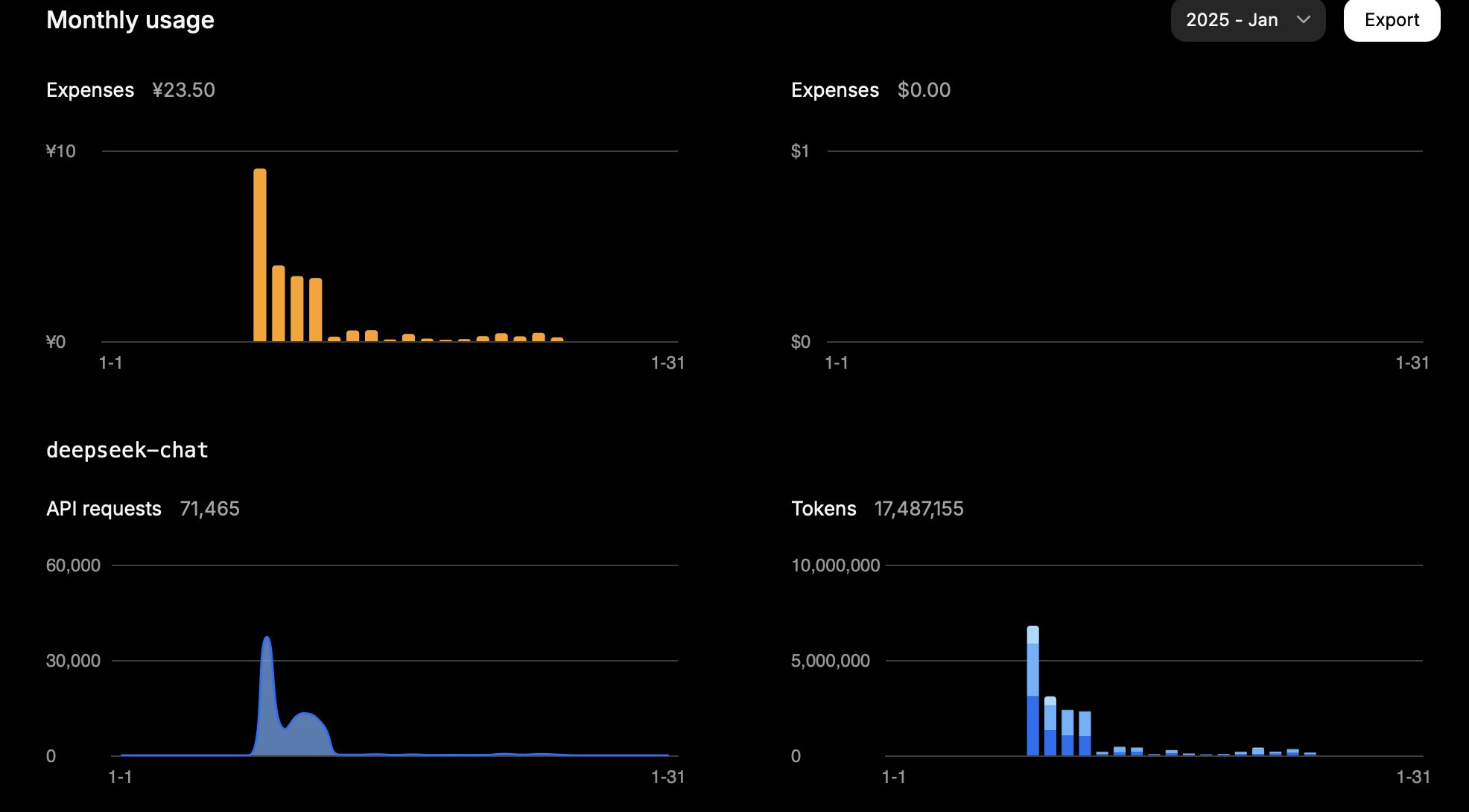
En un mes, 15 millones de tokens me costaron aproximadamente 23.5 CNY.
Este fue mi uso en un día:
| Tipo | Tokens |
|---|---|
| Entrada (Acierto de caché) | 946,816 |
| Entrada (Fallo de caché) | 2,753,752 |
| Salida | 3,100,977 |
El cálculo es el siguiente:
0.94 * 0.1 + 2.75 * 1 + 3.10 * 2 = 11.83
Entonces, dependiendo de la tarea, el uso de tokens depende en gran medida de la entrada (fallo de caché) y la salida.
Este resultado se alinea con el costo esperado.
 Fuente: Captura propia
Fuente: Captura propia
Mistral
Los precios para los modelos de Mistral son los siguientes:
| Modelo | Entrada (USD por millón de tokens) | Salida (USD por millón de tokens) |
|---|---|---|
mistral-large-2411 |
2 | 6 |
mistral-small-latest |
0.2 | 0.6 |
En un día, el uso de mi cuenta Mistral fue el siguiente (Modelo: mistral-large-2411):
| Tipo | Tokens | Costo (USD) |
|---|---|---|
| Total | 772,284 | 3.44 |
| Salida | 474,855 | 2.85 |
| Entrada | 297,429 | 0.59 |
Para el modelo mistral-small-2409, el uso total fue de 1,022,407 tokens.
Suponiendo que 1/3 fueron tokens de entrada y 2/3 fueron tokens de salida:
Hubo 340,802 tokens de entrada y 681,605 tokens de salida.
Por lo tanto, el costo total se calcula como 340,802 * 0.2 / 1,000,000 + 681,605 * 0.6 / 1,000,000 = 0.07 + 0.41 = 0.48 USD.
La consola de Mistral reporta un costo total de uso de 0.43 USD, que coincide aproximadamente con nuestro cálculo.
Grok
| Modelo | Entrada (USD por millón de tokens) | Salida (USD por millón de tokens) |
|---|---|---|
grok-2-latest |
2 | 10 |