大型語言模型成本、代理與編程工具 | 原創,AI翻譯
目錄
- 優化LLM API成本
- 首先使用成本效益較高的模型
- 避免不必要的高端模型使用
- 簡單任務優先選擇NLP庫
- 建立專屬代理以提升效率
- 通過廣泛測試比較模型
- Deepseek與Mistral的API使用
- DeepSeek成本隨緩存失誤增加
- Mistral開支主要來自輸出令牌
- Grok定價明顯偏向輸入令牌
- 任務複雜度影響令牌使用量
- 實際費用符合文件記載費率
- 通用代理與垂直代理
- 通用代理應對複雜問題時表現不佳
- 垂直代理在專業領域表現優異
- 工作流程工具限制靈活性
- 自定義Python代理提供更多控制
- 便利性與功能性的權衡
- 挑剔工程師對AI編程工具的見解
- 重視實用性而非品牌光環
- VSCode + Copilot仍是可靠組合
- Claude Code的差異化編輯令人印象深刻
- 語法工具需手動驗證
- 實踐比盲目採用更重要
優化LLM API成本
2025.08
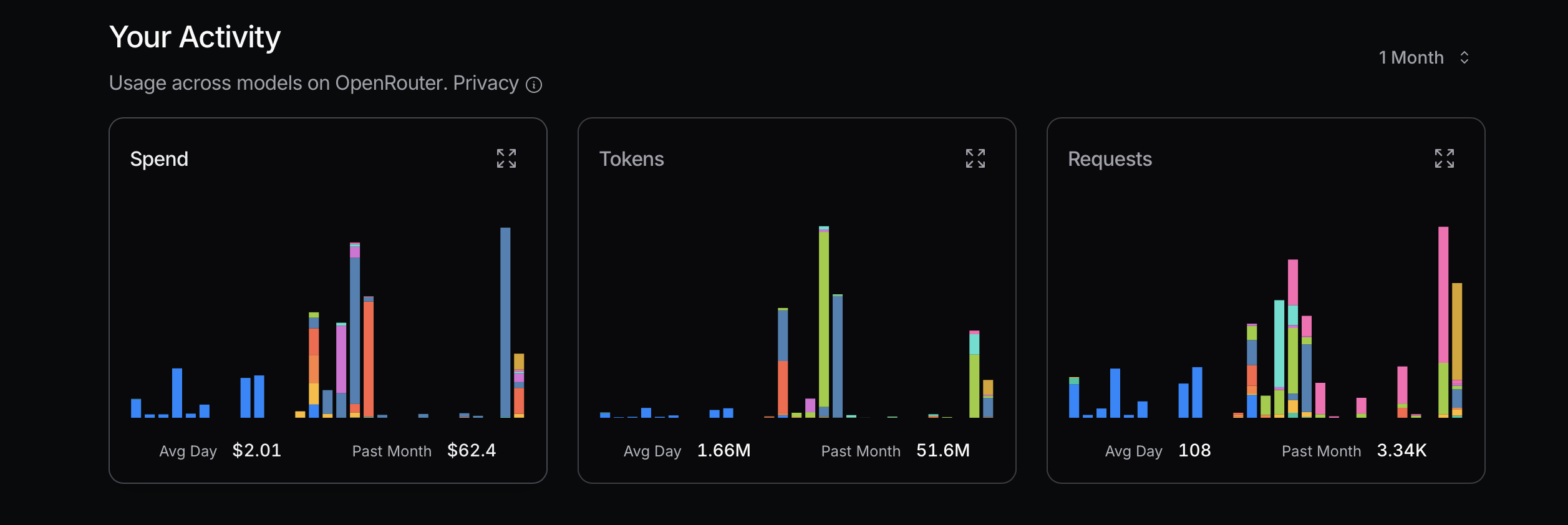 來源:openrouter.ai
來源:openrouter.ai
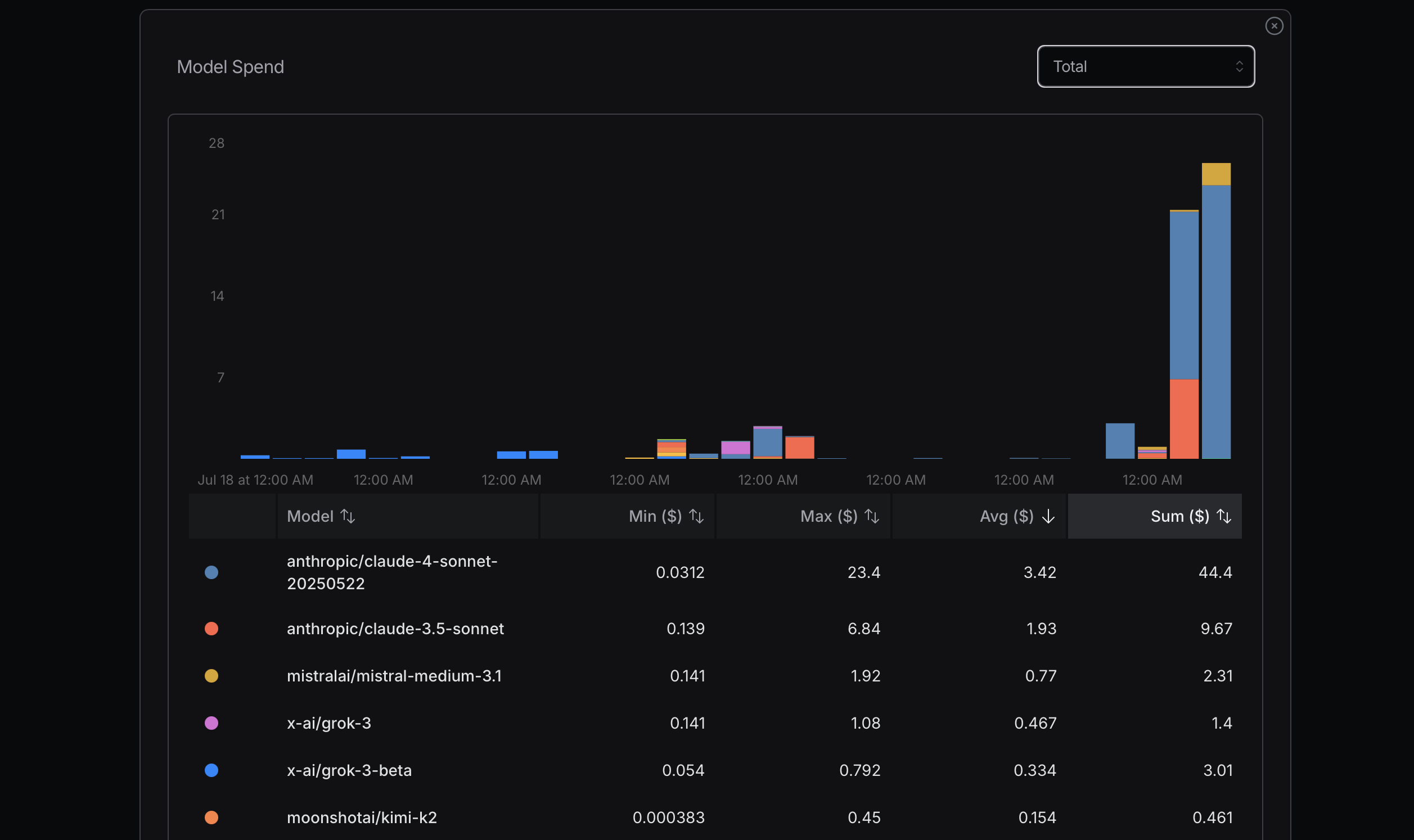 來源:openrouter.ai
來源:openrouter.ai
在優化令牌使用時,建議先從成本效益較高的模型開始。若遇到問題,再考慮升級至更高級的模型。Mistral、Gemini Flash和DeepSeek通常較為經濟實惠,而Claude Sonnet則較為昂貴。重要的是了解Claude Code如何使用以下顯示的路由器。
最近我有一次因忽略此原則而導致高額成本的經歷。當時我為了確定最高使用量而嘗試達到極限,這並非理性做法,只需簡單計算即可。例如,我真的需要Sonnet 4嗎?未必。雖然我認為它是Anthropic更先進的模型,且在OpenRouter上排名靠前,但我並不了解Sonnet 4與Sonnet 3.5之間的具體差異。
最近從Replit創始人Amjad Masad的訪談中學到了一些寶貴的東西。對於許多任務而言,並不需要非常先進的模型。理想情況下,如果能完全避免使用LLM API就更好了。某些NLP庫對於簡單任務非常有效,例如HanLP在處理中文任務時表現出色。
此外,我們可以開發自定義或專屬代理,從一開始就高效處理任務。Claude Code未必是所有任務的最佳或最具成本效益的解決方案。
要了解不同模型之間的差異,可以通過廣泛使用並比較其表現。使用Gemini 2.5 Flash一段時間後,我發現它的能力確實不如Sonnet 4。
幾天後,我使用以下配置來幫助優化。參數longContextThreshold非常重要。你可以定期清除Claude Code的控制台或重啟它。使用Claude Code編寫代碼時,很容易達到長上下文閾值。
{
"PROXY_URL": "http://127.0.0.1:7890",
"LOG": true,
"Providers": [
{
"name": "openrouter",
"api_base_url": "https://openrouter.ai/api/v1/chat/completions",
"api_key": "",
"models": [
"moonshotai/kimi-k2",
"anthropic/claude-sonnet-4",
"anthropic/claude-3.5-sonnet",
"anthropic/claude-3.7-sonnet:thinking",
"anthropic/claude-opus-4",
"google/gemini-2.5-flash",
"google/gemini-2.5-pro",
"deepseek/deepseek-chat-v3-0324",
"deepseek/deepseek-chat-v3.1",
"deepseek/deepseek-r1",
"mistralai/mistral-medium-3.1",
"qwen/qwen3-coder",
"openai/gpt-oss-120b",
"openai/gpt-5",
"openai/gpt-5-mini",
"x-ai/grok-3-mini"
],
"transformer": {
"use": [
"openrouter"
]
}
}
],
"Router": {
"default": "openrouter,openai/gpt-5-mini",
"background": "openrouter,google/gemini-2.5-flash",
"think": "openrouter,qwen/qwen3-coder",
"longContext": "openrouter,deepseek/deepseek-chat-v3.1",
"longContextThreshold": 2000,
"webSearch": "openrouter,mistralai/mistral-medium-3.1"
}
}
通用代理與垂直代理
2025.08
Manus被宣稱為一款通用AI代理工具,但實際效果可能不佳。
其中一個原因是它運作非常緩慢,做了許多不必要的工作且效率低下。另一個原因是,若遇到複雜問題或觸及其弱點,任務很可能會失敗。
垂直代理之所以表現優秀,是因為它們高度專業化,專為特定任務設計。目前有數十種數據庫和上百種如Spring這樣的Web開發框架,還有許多Web框架如Vue或React。
Dify專注於使用AI連接工作流程,通過拖放方式定義AI工作流程。他們需要做很多事情來連接信息、數據和平台。
我也建立了一些簡單的代理,如Python代碼重構代理、語法修正代理、錯誤修復代理和文章合併代理。
代碼非常靈活,因此Dify只涵蓋了可能想法中的一小部分。
Manus通過VNC方法顯示電腦運作方式來執行任務並展示給用戶。
我認為未來將主要集中於這兩種方法。
對於Manus,你需要上傳代碼或文本來執行任務,這不太方便。而Dify則需要通過拖放來構建工作流程,類似於MIT Scratch。
為什麼Scratch沒有Python那麼受歡迎?因為Python可以做很多事情,而Scratch僅限於教育用途的簡單程序。
Dify可能也有類似的限制。
Manus可以處理許多簡單任務。然而,對於某些任務,尤其是觸及Manus弱點的任務,它會失敗。
此外,許多程序或服務需要時間設置。在Manus的方法中,這個過程很慢。
作為一名程序員,我使用Python與AI結合來建立我的垂直代理。這對我來說是最簡單的方法。我還可以設置提示和上下文,以確保LLM API的輸出相對穩定。
Manus和Dify也是基於這些LLM API構建的。它們的優勢在於已經準備了許多工具或代碼供使用。
如果我想建立一個Twitter機器人代理,使用Dify可能比自己使用開源技術構建更方便。
挑剔工程師對AI編程工具的見解
2025.08
最近,我成功運行了Claude Code,因此想分享我的工具選擇歷程。在此過程中,我還收集了一些AI工具技巧。
我採用Claude Code的時間很晚。
Claude Code大約於2025年2月底發布。
直到最近我才成功嘗試使用。其中一個原因是它需要Anthropic API,而該API不支持中國的Visa信用卡。
另一個原因是Claude Code Router的出現,使我最近的嘗試得以成功。
我一直聽到對它的讚譽。2025年7月,我嘗試了Gemini CLI,但在多次失敗後放棄了用它修復我的代碼。
我還嘗試了Aider,另一個軟件代理。大約六個月後,我停止了使用Cursor,因為許多基於VSCode的插件出現了故障。此外,我不太想給Cursor太多功勞,因為它是基於VSCode構建的。隨著VSCode中的Copilot插件最近有所改進且差距不大,我更傾向於使用它。
然而,VSCode是基於開源技術Electron構建的。很難將功勞歸於某個團隊或個人。考慮到許多大公司和初創企業都從開源項目中獲利,我必須關注我的預算和適合我的工具。我不必過於擔心功勞歸屬。我更喜歡使用經濟實惠且有效的工具。
我短暫嘗試過Cline,但並未採用。
我在VSCode中使用Copilot插件,並通過OpenRouter自定義模型Grok 3 beta,效果不錯。
我不認為Claude Code會改變我的習慣,但既然我能成功運行它,且有耐心再嘗試幾次,我將在未來幾週觀察感受。
作為擁有10年軟件工程經驗的挑剔用戶,我希望工具在實際使用中表現出色。我不在乎品牌,只在乎日常實用性。
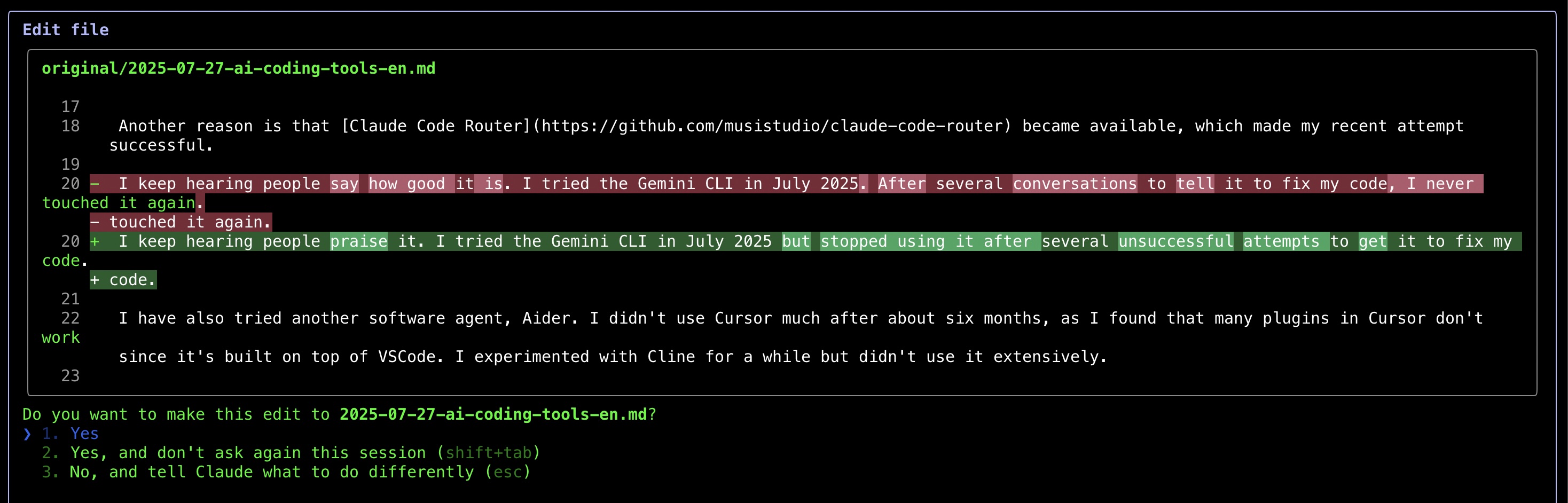
在使用Claude Code修正這篇文章的語法後,我發現它在某些情況下表現良好。雖然我感謝AI在語法幫助方面的貢獻(我甚至寫了一個Python腳本來調用LLM API完成此任務),但我注意到了一個令人沮喪的模式——即使我要求最小限度的修正,工具仍會不斷顯示大量語法建議供審查。這種手動驗證過程違背了自動化的初衷。作為折衷方案,我現在讓AI處理整篇文章,儘管這種方式限制了我的學習機會,因為我無法看到具體的修正內容。
最讓我印象深刻的是Claude Code顯示變更的方式——類似git diff的前後對比,使審查編輯變得更加容易。
一天後,我還使用Claude修正了一些代碼。不過,我繼續使用Grok 3 beta模型的Copilot插件,因為它對我很簡單易用。
在使用Claude Code幾天後,我不得不說它非常令人印象深刻。我真的很喜歡它修正代碼的方式。
 來源:自截圖
來源:自截圖
 來源:自截圖
來源:自截圖
 來源:自截圖
來源:自截圖
Deepseek與Mistral的API使用
2025.01.25
DeepSeek
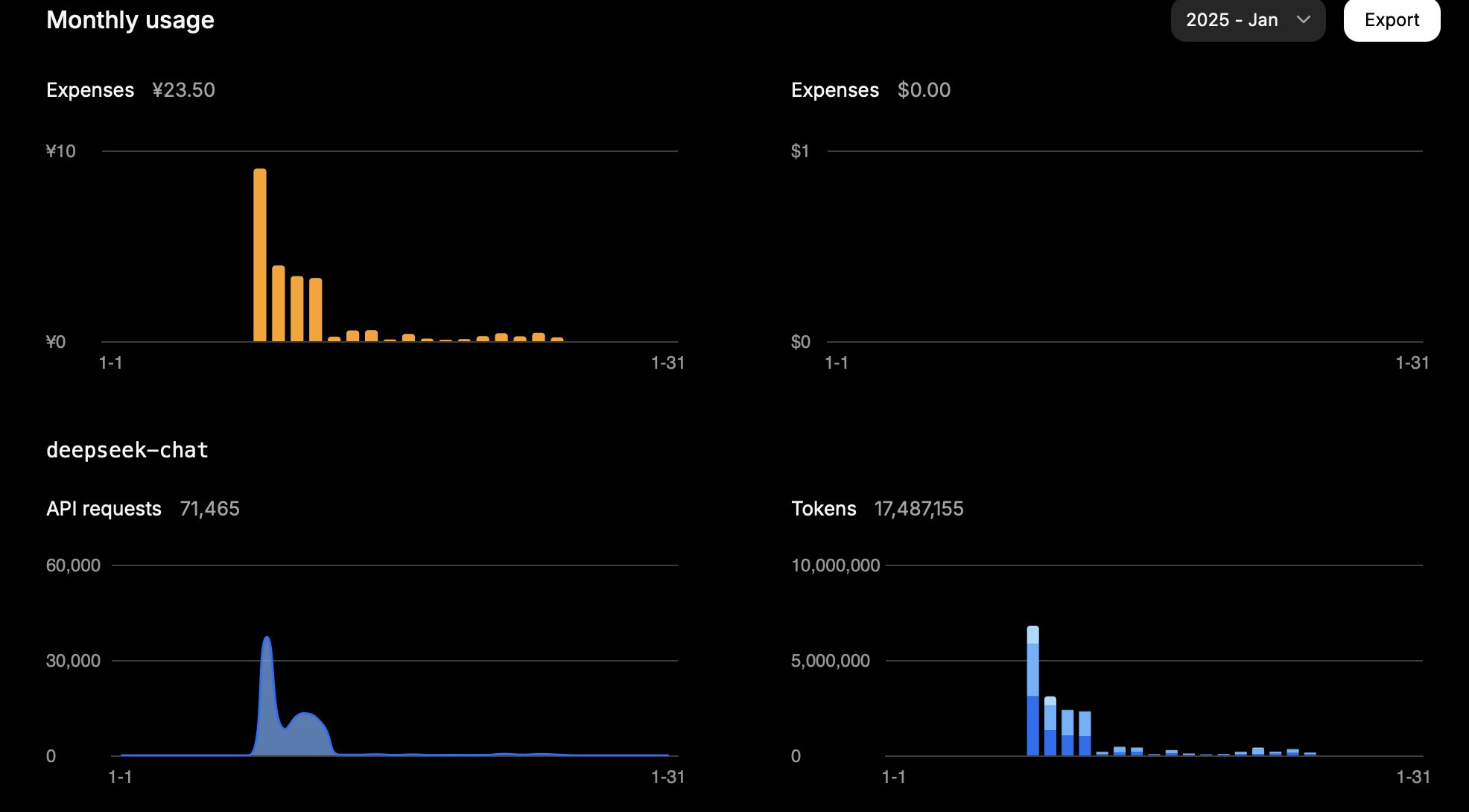
一個月內,1500萬令牌花費了大約23.5元人民幣。
這是我一天的使用情況:
| 類型 | 令牌數量 |
|---|---|
| 輸入(緩存命中) | 946,816 |
| 輸入(緩存未命中) | 2,753,752 |
| 輸出 | 3,100,977 |
計算如下:
0.94 * 0.1 + 2.75 * 1 + 3.10 * 2 = 11.83
因此,根據任務的不同,令牌使用量主要取決於輸入(緩存未命中)和輸出。
這一結果符合預期成本。
 來源:自截圖
來源:自截圖
Mistral
Mistral模型的定價如下:
| 模型 | 輸入(每百萬令牌美元) | 輸出(每百萬令牌美元) |
|---|---|---|
mistral-large-2411 |
2 | 6 |
mistral-small-latest |
0.2 | 0.6 |
一天內,我的Mistral帳戶使用情況如下(模型:mistral-large-2411):
| 類型 | 令牌數量 | 成本(美元) |
|---|---|---|
| 總計 | 772,284 | 3.44 |
| 輸出 | 474,855 | 2.85 |
| 輸入 | 297,429 | 0.59 |
對於mistral-small-2409模型,總使用量為1,022,407令牌。
假設其中1/3為輸入令牌,2/3為輸出令牌:
輸入令牌為340,802,輸出令牌為681,605。
因此,總成本計算為340,802 * 0.2 / 1,000,000 + 681,605 * 0.6 / 1,000,000 = 0.07 + 0.41 = 0.48美元。
Mistral控制台報告的總使用成本為0.43美元,與我們的計算大致相符。
Grok
| 模型 | 輸入(每百萬令牌美元) | 輸出(每百萬令牌美元) |
|---|---|---|
grok-2-latest |
2 | 10 |