LLM Porridge — Simple Porridge Views the World | Original
Simple porridge, quick eat. This is surprisingly close to LLM training and inference with FlashAttention. You could say they are exactly the same in one key aspect.
To eat quickly, you need shallow plates laid out flat. When shallow plates can’t hold enough, you need multiple shallow plates. This is the same logic as GPU tiles — bricks of compute.

Simple porridge views the world. Simple porridge views large language models. The great way is simple (大道至简).

The Analogy
FlashAttention works by tiling the attention matrix into small blocks that fit in GPU SRAM — shallow plates, laid flat. Each tile (a GPU brick) processes a piece of the matrix without needing to materialize the full O(n²) attention matrix in HBM. When one tile isn’t enough, you use multiple tiles in sequence. Same as porridge: one shallow plate can’t hold a bowl of porridge, so you spread it across several.
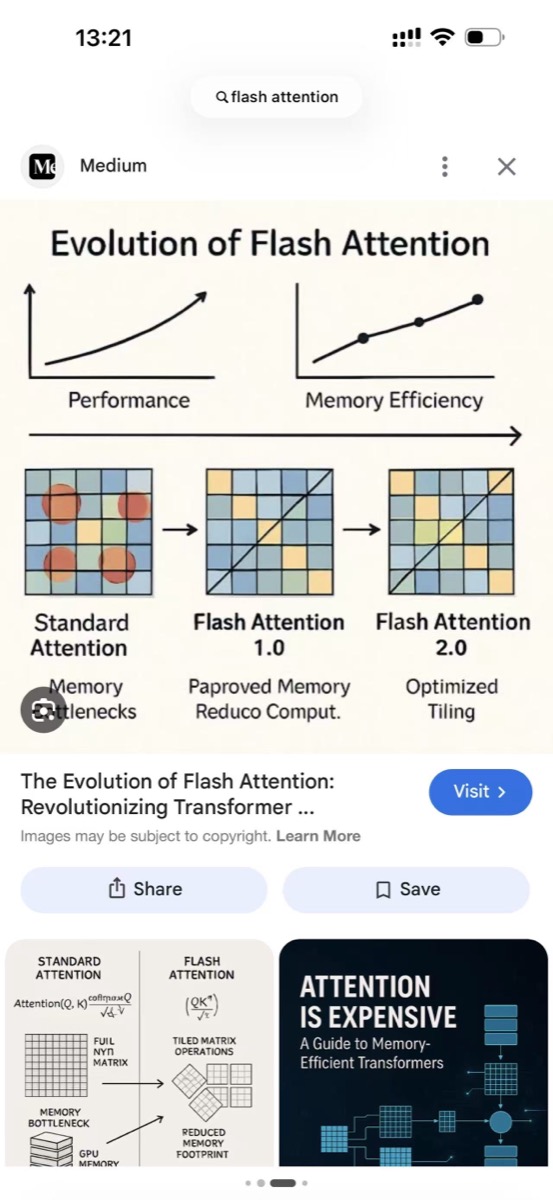
Image credit: from the internet
Clean Plate — Inference Successful
Clean plate. Token porridge grains successfully passed through shallow plates (GPU bricks) and into my stomach. Inference successful.
The only blemish: I used three plates instead of four. Can’t do parallel computation.

Four plates would have meant four GPU tiles running in parallel — full utilization. Three plates means one tile sits idle. That’s the difference between 75% and 100% hardware utilization. The porridge is eaten either way, but the throughput story changes.
The great way is simple: spread the work flat, use multiple tiles, consume everything. Porridge and transformers share the same wisdom.
Original. Curating and sharing still takes effort.
If you find it useful, feel free to
donate.
WeChat: @lzwjava ·
X: @lzwjava ·
Say hi 👋
·
X: @lzwjava ·
Say hi 👋