Benchmark de MMLU | Original, traducido por IA
Prólogo
Esta publicación evalúa un modelo de lenguaje utilizando la prueba MMLU (Massive Multitask Language Understanding).
La prueba MMLU es un examen exhaustivo de la capacidad de un modelo para realizar diversas tareas en una amplia gama de temas. Consiste en preguntas de opción múltiple que abarcan áreas diversas como matemáticas, historia, derecho y medicina.
Enlaces al Conjunto de Datos:
llama-server
Para ejecutar el servidor llama:
build/bin/llama-server -m models/7B/mistral-7b-instruct-v0.2.Q4_K_M.gguf --port 8080
Prueba MMLU
Este script evalúa la prueba MMLU utilizando tres backends diferentes: ollama, llama-server y deepseek.
Para ejecutar el código de la prueba MMLU:
import torch
from datasets import load_dataset
import requests
import json
from tqdm import tqdm
import argparse
import os
from openai import OpenAI
from dotenv import load_dotenv
import time
import random
load_dotenv()
# Configurar el análisis de argumentos
parser = argparse.ArgumentParser(description="Evaluar el conjunto de datos MMLU con diferentes backends.")
parser.add_argument("--type", type=str, default="ollama", choices=["ollama", "llama", "deepseek", "gemini", "mistral"], help="Tipo de backend: ollama, llama, deepseek, gemini o mistral")
parser.add_argument("--model", type=str, default="", help="Nombre del modelo")
args = parser.parse_args()
# Cargar el conjunto de datos MMLU
subject = "college_computer_science" # Elige tu tema
dataset = load_dataset("cais/mmlu", subject, split="test")
# Formatear el prompt con un ejemplo de un solo disparo
def format_mmlu_prompt(example):
prompt = f"Pregunta: {example['question']}\n"
prompt += "Opciones:\n"
for i, choice in enumerate(example['choices']):
prompt += f"{chr(ord('A') + i)}. {choice}\n"
prompt += "Da tu respuesta. Solo da la opción.\n"
return prompt
# Inicializar el cliente DeepSeek si es necesario
def initialize_deepseek_client():
api_key = os.environ.get("DEEPSEEK_API_KEY")
if not api_key:
print("Error: La variable de entorno DEEPSEEK_API_KEY no está definida.")
exit()
return OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
def call_gemini_api(prompt, retries=3, backoff_factor=1):
gemini_api_key = os.environ.get("GEMINI_API_KEY")
if not gemini_api_key:
print("Error: La variable de entorno GEMINI_API_KEY no está definida.")
exit()
url = f"https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent"
params = {"key": gemini_api_key}
payload = {"contents": [{"parts": [{"text": prompt}]}]}
print(f"Entrada a la API de Gemini: {payload}")
for attempt in range(retries):
response = requests.post(url, json=payload, params=params)
response_json = response.json()
print(response_json)
if response.status_code == 200:
return response_json
elif response.status_code == 429:
time.sleep(backoff_factor * (2 ** attempt)) # Retroceso exponencial
else:
raise Exception(f"Error de la API de Gemini: {response.status_code} - {response_json}")
return None
def call_mistral_api(prompt, model="mistral-small-2501", process_response=True):
api_key = os.environ.get("MISTRAL_API_KEY")
if not api_key:
print("Error: La variable de entorno MISTRAL_API_KEY no está definida.")
return None
url = "https://api.mistral.ai/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": model,
"messages": [
{
"role": "user",
"content": prompt
}
]
}
print(f"Entrada a la API de Mistral: {data}")
print(f"URL de la API de Mistral: {url}")
print(f"Encabezados de la API de Mistral: {headers}")
try:
response = requests.post(url, headers=headers, json=data)
response.raise_for_status()
response_json = response.json()
print(response_json)
if response_json and response_json['choices']:
content = response_json['choices'][0]['message']['content']
if process_response:
return process_mistral_response(content)
else:
return content
else:
print(f"Error de la API de Mistral: Formato de respuesta no válido: {response_json}")
return None
except requests.exceptions.RequestException as e:
print(f"Error de la API de Mistral: {e}")
stre = f"{e}"
if '429' in stre:
# print(f"Código de estado de la respuesta: {e.response.status_code}")
# print(f"Contenido de la respuesta: {e.response.text}")
print("Demasiadas solicitudes, durmiendo por 10 segundos y volviendo a intentar")
time.sleep(10)
return call_mistral_api(prompt, model, process_response)
raise e
import re
def process_ollama_response(response):
if response.status_code == 200:
print(f"Salida de la API: {response.json()}")
output_text = response.json()["choices"][0]["message"]["content"]
match = re.search(r"Answer:\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"\*\*Answer\*\*:\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct answer is\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct choice is\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct choice would be\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The answer is\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The answer appears to be\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct answer should be\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct answer would be\s*([A-D])", output_text, re.IGNORECASE)
if match:
predicted_answer = match.group(1).upper()
else:
stripped_output = output_text.strip()
if len(stripped_output) > 0:
first_word = stripped_output.split(" ")[0]
if len(first_word) == 1:
predicted_answer = first_word
else:
first_word_comma = stripped_output.split(",")[0]
if len(first_word_comma) == 1:
predicted_answer = first_word_comma
else:
first_word_period = stripped_output.split(".")[0]
if len(first_word_period) == 1:
predicted_answer = first_word_period
else:
print(f"No se pudo extraer una respuesta de un solo carácter de la salida: {output_text}, devolviendo respuesta aleatoria")
predicted_answer = random.choice(["A", "B", "C", "D"])
else:
predicted_answer = ""
return predicted_answer
else:
print(f"Error: {response.status_code} - {response.text}")
return ""
def process_llama_response(response):
if response.status_code == 200:
output_text = response.json()["choices"][0]["message"]["content"]
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"Salida de la API: {output_text}")
return predicted_answer
else:
print(f"Error: {response.status_code} - {response.text}")
return ""
def process_deepseek_response(client, prompt, model="deepseek-chat", retries=3, backoff_factor=1):
print(f"Entrada a la API de Deepseek: {prompt}")
for attempt in range(retries):
try:
response = client.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": prompt}
],
max_tokens=100
)
if response and response.choices:
output_text = response.choices[0].message.content.strip()
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"Salida de la API: {output_text}")
return predicted_answer
else:
print("Error: No hay respuesta de la API.")
return ""
except Exception as e:
if "502" in str(e):
print(f"Error de la puerta de enlace (502) durante la llamada a la API, volviendo a intentar en {backoff_factor * (2 ** attempt)} segundos...")
time.sleep(backoff_factor * (2 ** attempt))
else:
print(f"Error durante la llamada a la API: {e}")
return ""
return ""
def process_mistral_response(response):
if response:
output_text = response.strip()
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"Salida de la API: {output_text}")
return predicted_answer
else:
print("Error: No hay respuesta de la API de Mistral")
return ""
def process_gemini_response(prompt):
json_response = call_gemini_api(prompt)
if not json_response:
print("No hay respuesta de la API de Gemini después de los reintentos.")
return ""
if 'candidates' not in json_response or not json_response['candidates']:
print("No se encontraron candidatos en la respuesta, volviendo a intentar...")
json_response = call_gemini_api(prompt)
print(json_response)
if not json_response or 'candidates' not in json_response or not json_response['candidates']:
print("No se encontraron candidatos en la respuesta después del reintento.")
return ""
first_candidate = json_response['candidates'][0]
if 'content' in first_candidate and 'parts' in first_candidate['content']:
first_part = first_candidate['content']['parts'][0]
if 'text' in first_part:
output_text = first_part['text']
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"Salida de la API: {output_text}")
return predicted_answer
else:
print("No se encontró texto en la respuesta")
return ""
else:
print("Formato de respuesta inesperado: falta contenido o partes")
return ""
def _call_ollama_api(prompt, model):
url = "http://localhost:11434/v1/chat/completions"
data = {
"messages": [{"role": "user", "content": prompt}],
"model": model,
"max_tokens": 300
}
headers = {"Content-Type": "application/json"}
print(f"Entrada a la API: {data}")
response = requests.post(url, headers=headers, data=json.dumps(data))
return process_ollama_response(response)
def _call_llama_api(prompt):
url = "http://localhost:8080/v1/chat/completions"
data = {
"messages": [{"role": "user", "content": prompt}]
}
headers = {"Content-Type": "application/json"}
print(f"Entrada a la API: {data}")
response = requests.post(url, headers=headers, data=json.dumps(data))
return process_llama_response(response)
def _get_predicted_answer(args, prompt, client):
predicted_answer = ""
if args.type == "ollama":
predicted_answer = _call_ollama_api(prompt, args.model)
elif args.type == "llama":
predicted_answer = _call_llama_api(prompt)
elif args.type == "deepseek":
predicted_answer = process_deepseek_response(client, prompt, args.model)
elif args.type == "gemini":
predicted_answer = process_gemini_response(prompt)
elif args.type == "mistral":
predicted_answer = call_mistral_api(prompt, args.model)
else:
raise ValueError("Tipo de backend no válido")
return predicted_answer
def evaluate_model(args, dataset):
correct = 0
total = 0
client = None
if args.type == "deepseek":
client = initialize_deepseek_client()
if args.model == "":
if args.type == "ollama":
args.model = "mistral:7b"
elif args.type == "deepseek":
args.model = "deepseek-chat"
elif args.type == "mistral":
args.model = "mistral-small-latest"
for i, example in tqdm(enumerate(dataset), total=len(dataset), desc="Evaluando"):
prompt = format_mmlu_prompt(example)
predicted_answer = _get_predicted_answer(args, prompt, client)
answer_map = {0: "A", 1: "B", 2: "C", 3: "D"}
ground_truth_answer = answer_map.get(example["answer"], "")
is_correct = predicted_answer.upper() == ground_truth_answer
if is_correct:
correct += 1
total += 1
print(f"Pregunta: {example['question']}")
print(f"Opciones: A. {example['choices'][0]}, B. {example['choices'][1]}, C. {example['choices'][2]}, D. {example['choices'][3]}")
print(f"Respuesta Predicha: {predicted_answer}, Verdadera: {ground_truth_answer}, Correcta: {is_correct}")
print("-" * 30)
if (i+1) % 10 == 0:
accuracy = correct / total
print(f"Procesado {i+1}/{len(dataset)}. Exactitud actual: {accuracy:.2%} ({correct}/{total})")
return correct, total
# Bucle de evaluación
correct, total = evaluate_model(args, dataset)
# Calcular la exactitud
accuracy = correct / total
print(f"Tema: {subject}")
print(f"Exactitud: {accuracy:.2%} ({correct}/{total})")
Resultados
Evaluación de Zero-Shot
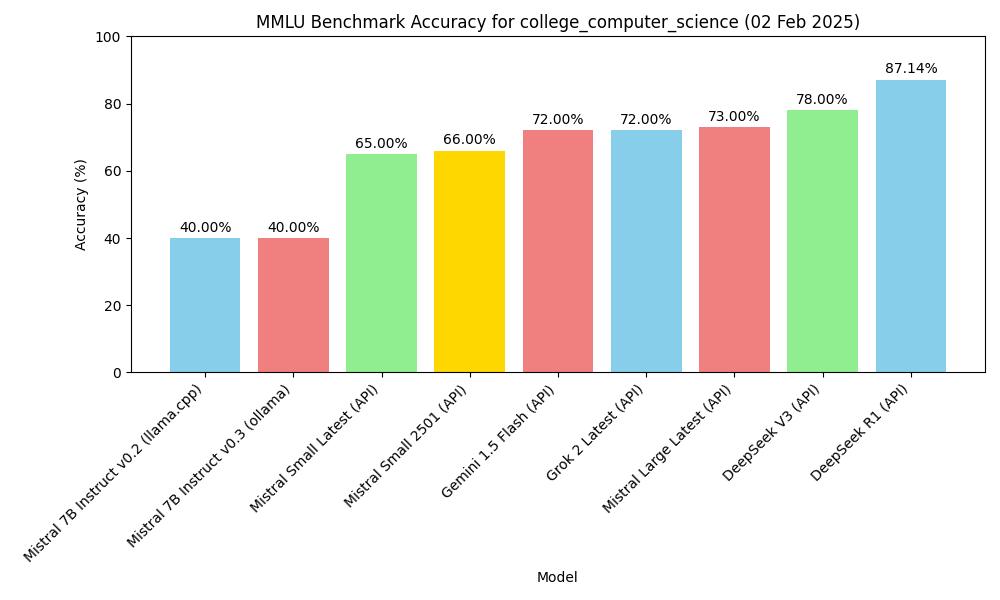
| Modelo | Forma | Tema | Exactitud |
|---|---|---|---|
| mistral-7b-instruct-v0.2, Q4_K_M | macOS m2, 16GB, llama-server | MMLU college_computer_science | 40.00% (40/100) |
| Mistral-7B-Instruct-v0.3, Q4_0 | macOS m2, 16GB, ollama | MMLU college_computer_science | 40.00% (40/100) |
| deepseek v3 (API) | API, 2025.1.25 | MMLU college_computer_science | 78.00% (78/100) |
| gemini-1.5-flash (API) | API, 2025.1.25 | MMLU college_computer_science | 72.00% (72/100) |
| deepseek r1 (API) | API, 2025.1.26 | MMLU college_computer_science | 87.14% (61/70) |
| Mistral Small Latest (API) | API, 2025.01.31 | MMLU college_computer_science | 65.00% (65/100) |
| Mistral Large Latest (API) | API, 2025.01.31 | MMLU college_computer_science | 73.00% (73/100) |
| Mistral Small 2501 (API) | API, 2025.01.31 | MMLU college_computer_science | 66.00% (66/100) |
| Grok 2 Latest | API, 2025.02.02 | MMLU college_computer_science | 72.00% (72/100) |
Figura
Vamos a crear una figura basada en la tabla anterior.
import matplotlib.pyplot as plt
import os
# Datos de ejemplo (reemplaza con tus datos reales)
models = ['mistral-7b-instruct-v0.2 (llama.cpp)', 'Mistral-7B-Instruct-v0.3 (ollama)', 'deepseek v3 (API)', 'gemini-1.5-flash (API)', 'deepseek r1 (API)']
accuracy = [40.00, 40.00, 78.00, 72.00, 87.14]
subject = "college_computer_science"
# Crear el gráfico de barras
plt.figure(figsize=(10, 6))
plt.bar(models, accuracy, color=['skyblue', 'lightcoral', 'lightgreen', 'gold', 'lightcoral'])
plt.xlabel('Modelo')
plt.ylabel('Exactitud (%)')
plt.title(f'Exactitud en la Prueba MMLU para {subject}')
plt.ylim(0, 100) # Establecer el límite del eje y a 0-100 para el porcentaje
plt.xticks(rotation=45, ha="right") # Rotar las etiquetas del eje x para una mejor legibilidad
plt.tight_layout()
# Añadir valores de exactitud encima de las barras
for i, val in enumerate(accuracy):
plt.text(i, val + 1, f'{val:.2f}%', ha='center', va='bottom')
# Guardar el gráfico como un archivo JPG en el directorio actual
plt.savefig(os.path.join(os.path.dirname(__file__), f'mmlu_accuracy_chart.jpg'))
plt.show()
 Exactitud en la Prueba MMLU
Exactitud en la Prueba MMLU