多模态多任務評估基準 | 原創,AI翻譯
前言
本文將評估一個語言模型,使用MMLU(Massive Multitask Language Understanding)基準。
MMLU基準是對模型在各種主題上的多任務執行能力的全面測試。它包含多項選擇問題,涵蓋了數學、歷史、法律、醫學等多種領域。
數據集連結:
llama-server
要運行llama-server:
build/bin/llama-server -m models/7B/mistral-7b-instruct-v0.2.Q4_K_M.gguf --port 8080
MMLU基準
這段程序使用三種不同的後端來評估MMLU基準:ollama、llama-server和deepseek。
要運行MMLU基準代碼:
import torch
from datasets import load_dataset
import requests
import json
from tqdm import tqdm
import argparse
import os
from openai import OpenAI
from dotenv import load_dotenv
import time
import random
load_dotenv()
# 設置參數解析
parser = argparse.ArgumentParser(description="使用不同後端評估MMLU數據集。")
parser.add_argument("--type", type=str, default="ollama", choices=["ollama", "llama", "deepseek", "gemini", "mistral"], help="後端類型:ollama, llama, deepseek, gemini 或 mistral")
parser.add_argument("--model", type=str, default="", help="模型名稱")
args = parser.parse_args()
# 加載MMLU數據集
subject = "college_computer_science" # 選擇您的主題
dataset = load_dataset("cais/mmlu", subject, split="test")
# 使用一個例子格式提示
def format_mmlu_prompt(example):
prompt = f"Question: {example['question']}\n"
prompt += "Choices:\n"
for i, choice in enumerate(example['choices']):
prompt += f"{chr(ord('A') + i)}. {choice}\n"
prompt += "Give your answer. Just give the choice.\n"
return prompt
# 如果需要初始化DeepSeek客戶端
def initialize_deepseek_client():
api_key = os.environ.get("DEEPSEEK_API_KEY")
if not api_key:
print("錯誤:DEEPSEEK_API_KEY環境變量未設置。")
exit()
return OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
def call_gemini_api(prompt, retries=3, backoff_factor=1):
gemini_api_key = os.environ.get("GEMINI_API_KEY")
if not gemini_api_key:
print("錯誤:GEMINI_API_KEY環境變量未設置。")
exit()
url = f"https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent"
params = {"key": gemini_api_key}
payload = {"contents": [{"parts": [{"text": prompt}]}]}
print(f"輸入到Gemini API: {payload}")
for attempt in range(retries):
response = requests.post(url, json=payload, params=params)
response_json = response.json()
print(response_json)
if response.status_code == 200:
return response_json
elif response.status_code == 429:
time.sleep(backoff_factor * (2 ** attempt)) # 指數退避
else:
raise Exception(f"Gemini API錯誤:{response.status_code} - {response_json}")
return None
def call_mistral_api(prompt, model="mistral-small-2501", process_response=True):
api_key = os.environ.get("MISTRAL_API_KEY")
if not api_key:
print("錯誤:MISTRAL_API_KEY環境變量未設置。")
return None
url = "https://api.mistral.ai/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": model,
"messages": [
{
"role": "user",
"content": prompt
}
]
}
print(f"輸入到Mistral API: {data}")
print(f"Mistral API URL: {url}")
print(f"Mistral API Headers: {headers}")
try:
response = requests.post(url, headers=headers, json=data)
response.raise_for_status()
response_json = response.json()
print(response_json)
if response_json and response_json['choices']:
content = response_json['choices'][0]['message']['content']
if process_response:
return process_mistral_response(content)
else:
return content
else:
print(f"Mistral API錯誤:無效的回應格式:{response_json}")
return None
except requests.exceptions.RequestException as e:
print(f"Mistral API錯誤:{e}")
stre = f"{e}"
if '429' in stre:
print("請求過多,暫停10秒並重試")
time.sleep(10)
return call_mistral_api(prompt, model, process_response)
raise e
import re
def process_ollama_response(response):
if response.status_code == 200:
print(f"API輸出: {response.json()}")
output_text = response.json()["choices"][0]["message"]["content"]
match = re.search(r"Answer:\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"\*\*Answer\*\*:\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct answer is\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct choice is\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct choice would be\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The answer is\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The answer appears to be\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct answer should be\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct answer would be\s*([A-D])", output_text, re.IGNORECASE)
if match:
predicted_answer = match.group(1).upper()
else:
stripped_output = output_text.strip()
if len(stripped_output) > 0:
first_word = stripped_output.split(" ")[0]
if len(first_word) == 1:
predicted_answer = first_word
else:
first_word_comma = stripped_output.split(",")[0]
if len(first_word_comma) == 1:
predicted_answer = first_word_comma
else:
first_word_period = stripped_output.split(".")[0]
if len(first_word_period) == 1:
predicted_answer = first_word_period
else:
print(f"無法從輸出中提取單字母答案:{output_text},返回隨機答案")
predicted_answer = random.choice(["A", "B", "C", "D"])
else:
predicted_answer = ""
return predicted_answer
else:
print(f"錯誤:{response.status_code} - {response.text}")
return ""
def process_llama_response(response):
if response.status_code == 200:
output_text = response.json()["choices"][0]["message"]["content"]
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"API輸出: {output_text}")
return predicted_answer
else:
print(f"錯誤:{response.status_code} - {response.text}")
return ""
def process_deepseek_response(client, prompt, model="deepseek-chat", retries=3, backoff_factor=1):
print(f"輸入到Deepseek API: {prompt}")
for attempt in range(retries):
try:
response = client.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": prompt}
],
max_tokens=100
)
if response and response.choices:
output_text = response.choices[0].message.content.strip()
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"API輸出: {output_text}")
return predicted_answer
else:
print("錯誤:無API回應。")
return ""
except Exception as e:
if "502" in str(e):
print(f"單向錯誤(502)期間API呼叫,{backoff_factor * (2 ** attempt)}秒後重試...")
time.sleep(backoff_factor * (2 ** attempt))
else:
print(f"API呼叫期間錯誤:{e}")
return ""
return ""
def process_mistral_response(response):
if response:
output_text = response.strip()
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"API輸出: {output_text}")
return predicted_answer
else:
print("錯誤:無Mistral API回應")
return ""
def process_gemini_response(prompt):
json_response = call_gemini_api(prompt)
if not json_response:
print("在重試後,Gemini API無回應。")
return ""
if 'candidates' not in json_response or not json_response['candidates']:
print("在回應中找不到候選人,重試...")
json_response = call_gemini_api(prompt)
print(json_response)
if not json_response or 'candidates' not in json_response or not json_response['candidates']:
print("在重試後,回應中找不到候選人。")
return ""
first_candidate = json_response['candidates'][0]
if 'content' in first_candidate and 'parts' in first_candidate['content']:
first_part = first_candidate['content']['parts'][0]
if 'text' in first_part:
output_text = first_part['text']
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"API輸出: {output_text}")
return predicted_answer
else:
print("回應中找不到文本")
return ""
else:
print("意外的回應格式:缺少內容或部分")
return ""
def _call_ollama_api(prompt, model):
url = "http://localhost:11434/v1/chat/completions"
data = {
"messages": [{"role": "user", "content": prompt}],
"model": model,
"max_tokens": 300
}
headers = {"Content-Type": "application/json"}
print(f"輸入到API: {data}")
response = requests.post(url, headers=headers, data=json.dumps(data))
return process_ollama_response(response)
def _call_llama_api(prompt):
url = "http://localhost:8080/v1/chat/completions"
data = {
"messages": [{"role": "user", "content": prompt}]
}
headers = {"Content-Type": "application/json"}
print(f"輸入到API: {data}")
response = requests.post(url, headers=headers, data=json.dumps(data))
return process_llama_response(response)
def _get_predicted_answer(args, prompt, client):
predicted_answer = ""
if args.type == "ollama":
predicted_answer = _call_ollama_api(prompt, args.model)
elif args.type == "llama":
predicted_answer = _call_llama_api(prompt)
elif args.type == "deepseek":
predicted_answer = process_deepseek_response(client, prompt, args.model)
elif args.type == "gemini":
predicted_answer = process_gemini_response(prompt)
elif args.type == "mistral":
predicted_answer = call_mistral_api(prompt, args.model)
else:
raise ValueError("無效的後端類型")
return predicted_answer
def evaluate_model(args, dataset):
correct = 0
total = 0
client = None
if args.type == "deepseek":
client = initialize_deepseek_client()
if args.model == "":
if args.type == "ollama":
args.model = "mistral:7b"
elif args.type == "deepseek":
args.model = "deepseek-chat"
elif args.type == "mistral":
args.model = "mistral-small-latest"
for i, example in tqdm(enumerate(dataset), total=len(dataset), desc="評估"):
prompt = format_mmlu_prompt(example)
predicted_answer = _get_predicted_answer(args, prompt, client)
answer_map = {0: "A", 1: "B", 2: "C", 3: "D"}
ground_truth_answer = answer_map.get(example["answer"], "")
is_correct = predicted_answer.upper() == ground_truth_answer
if is_correct:
correct += 1
total += 1
print(f"Question: {example['question']}")
print(f"Choices: A. {example['choices'][0]}, B. {example['choices'][1]}, C. {example['choices'][2]}, D. {example['choices'][3]}")
print(f"Predicted Answer: {predicted_answer}, Ground Truth: {ground_truth_answer}, Correct: {is_correct}")
print("-" * 30)
if (i+1) % 10 == 0:
accuracy = correct / total
print(f"處理了{i+1}/{len(dataset)}。當前準確率:{accuracy:.2%} ({correct}/{total})")
return correct, total
# 評估迴圈
correct, total = evaluate_model(args, dataset)
# 計算準確率
accuracy = correct / total
print(f"主題: {subject}")
print(f"準確率: {accuracy:.2%} ({correct}/{total})")
結果
零次射評估
| 模型 | 類型 | 主題 | 準確率 |
|---|---|---|---|
| mistral-7b-instruct-v0.2, Q4_K_M | macOS m2, 16GB, llama-server | MMLU college_computer_science | 40.00% (40/100) |
| Mistral-7B-Instruct-v0.3, Q4_0 | macOS m2, 16GB, ollama | MMLU college_computer_science | 40.00% (40/100) |
| deepseek v3 (API) | API, 2025.1.25 | MMLU college_computer_science | 78.00% (78/100) |
| gemini-1.5-flash (API) | API, 2025.1.25 | MMLU college_computer_science | 72.00% (72/100) |
| deepseek r1 (API) | API, 2025.1.26 | MMLU college_computer_science | 87.14% (61/70) |
| Mistral Small Latest (API) | API, 2025.01.31 | MMLU college_computer_science | 65.00% (65/100) |
| Mistral Large Latest (API) | API, 2025.01.31 | MMLU college_computer_science | 73.00% (73/100) |
| Mistral Small 2501 (API) | API, 2025.01.31 | MMLU college_computer_science | 66.00% (66/100) |
| Grok 2 Latest | API, 2025.02.02 | MMLU college_computer_science | 72.00% (72/100) |
圖表
讓我們根據上表創建一個圖表。
import matplotlib.pyplot as plt
import os
# 模型數據(請替換為您的實際數據)
models = ['mistral-7b-instruct-v0.2 (llama.cpp)', 'Mistral-7B-Instruct-v0.3 (ollama)', 'deepseek v3 (API)', 'gemini-1.5-flash (API)', 'deepseek r1 (API)']
accuracy = [40.00, 40.00, 78.00, 72.00, 87.14]
subject = "college_computer_science"
# 創建條形圖
plt.figure(figsize=(10, 6))
plt.bar(models, accuracy, color=['skyblue', 'lightcoral', 'lightgreen', 'gold', 'lightcoral'])
plt.xlabel('模型')
plt.ylabel('準確率 (%)')
plt.title(f'MMLU基準準確率{subject}')
plt.ylim(0, 100) # 設置y軸限制0-100
plt.xticks(rotation=45, ha="right") # 旋轉x軸標籤以提高可讀性
plt.tight_layout()
# 在條形上方添加準確率值
for i, val in enumerate(accuracy):
plt.text(i, val + 1, f'{val:.2f}%', ha='center', va='bottom')
# 將圖表保存為當前目錄中的JPG文件
plt.savefig(os.path.join(os.path.dirname(__file__), f'mmlu_accuracy_chart.jpg'))
plt.show()
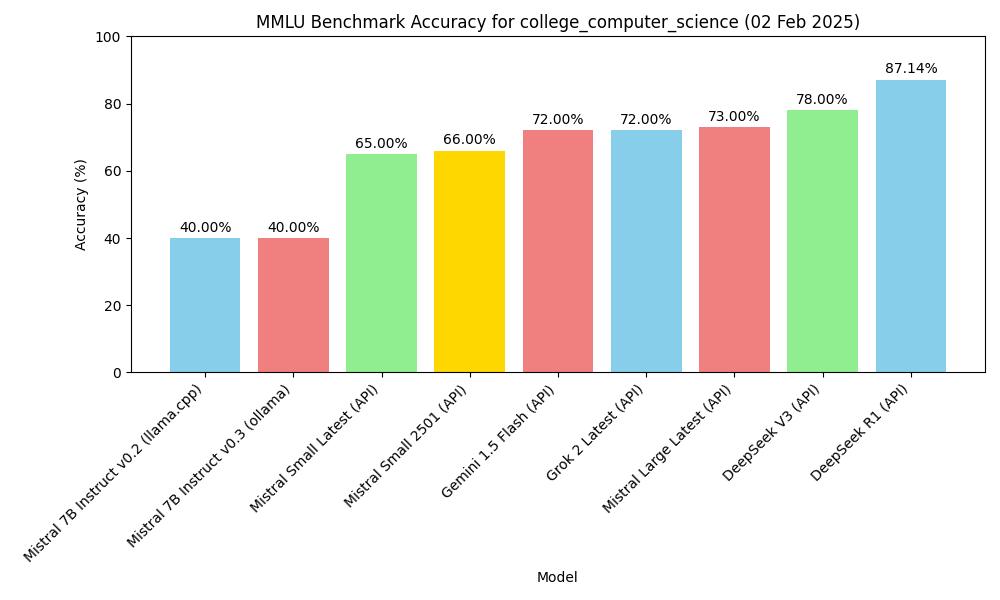 MMLU基準準確率
MMLU基準準確率