MMLU Benchmark का हिंदी अनुवाद | मूल, AI द्वारा अनुवादित
प्रस्तावना
इस पोस्ट में, एक भाषा मॉडल को MMLU (Massive Multitask Language Understanding) बेंचमार्क का उपयोग करके मूल्यांकन किया गया है।
MMLU बेंचमार्क एक व्यापक परीक्षा है जिसका उद्देश्य एक मॉडल के विभिन्न कार्यों को और एक व्यापक स्तर पर विभिन्न विषयों में करने की क्षमता को परखना है। यह कई विकल्पों वाले प्रश्नों से बना है जो गणित, इतिहास, कानून और चिकित्सा जैसे विविध क्षेत्रों को कवर करता है।
डेटासेट लिंक:
llama-server
llama-server चलाने के लिए:
build/bin/llama-server -m models/7B/mistral-7b-instruct-v0.2.Q4_K_M.gguf --port 8080
MMLU बेंचमार्क
इस स्क्रिप्ट में MMLU बेंचमार्क का तीन अलग-अलग बैकएंडों: ollama, llama-server, और deepseek का उपयोग करके मूल्यांकन किया जाता है।
MMLU बेंचमार्क कोड को चलाने के लिए:
import torch
from datasets import load_dataset
import requests
import json
from tqdm import tqdm
import argparse
import os
from openai import OpenAI
from dotenv import load_dotenv
import time
import random
load_dotenv()
# तर्क परामर्श सेटअप करें
parser = argparse.ArgumentParser(description="के साथ MMLU डेटासेट का मूल्यांकन करें।")
parser.add_argument("--type", type=str, default="ollama", choices=["ollama", "llama", "deepseek", "gemini", "mistral"], help="बैकएंड प्रकार: ollama, llama, deepseek, gemini या mistral")
parser.add_argument("--model", type=str, default="", help="मॉडल नाम")
args = parser.parse_args()
# MMLU डेटासेट लोड करें
विषय = "college_computer_science" # अपने विषय का चयन करें
डेटासेट = load_dataset("cais/mmlu", विषय, split="test")
# एक-शॉट उदाहरण के साथ प्रोम्प्ट को फॉर्मेट करें
def format_mmlu_prompt(example):
प्रोम्प्ट = f"प्रश्न: {example['question']}\n"
प्रोम्प्ट += "विकल्प:\n"
for i, चय in enumerate(example['choices']):
प्रोम्प्ट += f"{chr(ord('A') + i)}. {चय}\n"
प्रोम्प्ट += "अपना जवाब दें। केवल विकल्प दें.\n"
return प्रोम्प्ट
# गहरी खोज क्लाइंट को सेटअप करें यदि आवश्यक हो
def initialize_deepseek_client():
api_key = os.environ.get("DEEPSEEK_API_KEY")
if not api_key:
print("त्रुटि: DEEPSEEK_API_KEY पर्यावरण चर नहीं सेट है।")
exit()
return OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
def call_gemini_api(प्रोम्प्ट, retries=3, backoff_factor=1):
gemini_api_key = os.environ.get("GEMINI_API_KEY")
if not gemini_api_key:
print("त्रुटि: GEMINI_API_KEY पर्यावरण चर नहीं सेट है।")
exit()
url = f"https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent"
params = {"key": gemini_api_key}
Payload = {"contents": [{"parts": [{"text": prompt}]}]}
print(f"GEMINI API को इनपुट: {Payload}")
for attempt in range(retries):
response = requests.post(url, json=Payload, params=params)
response_json = response.json()
print(response_json)
if response.status_code == 200:
return response_json
elif response.status_code == 429:
time.sleep(backoff_factor * (2 ** attempt)) # Exponential backoff
else:
raise Exception(f"GEMINI API Error: {response.status_code} - {response_json}")
return None
def call_mistral_api(प्रोम्प्ट, model="mistral-small-2501", process_response=True):
api_key = os.environ.get("MISTRAL_API_KEY")
if not api_key:
print("त्रुटि: MISTRAL_API_KEY पर्यावरण चर नहीं सेट है।")
return None
url = "https://api.mistral.ai/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": model,
"messages": [
{
"role": "user",
"content": prompt
}
]
}
print(f"Mistral API को इनपुट: {data}")
print(f"Mistral API URL: {url}")
print(f"Mistral API Headers: {headers}")
try:
response = requests.post(url, headers=headers, json=data)
response.raise_for_status()
response_json = response.json()
print(response_json)
if response_json and response_json['choices']:
content = response_json['choices'][0]['message']['content']
if process_response:
return process_mistral_response(content)
else:
return content
else:
print(f"Mistral API Error: Invalid response format: {response_json}")
return None
except requests.exceptions.RequestException as e:
print(f"Mistral API Error: {e}")
stre = f"{e}"
if '429' in stre:
# print(f"Response status code: {e.response.status_code}")
# print(f"Response content: {e.response.text}")
print("Too many requests, sleeping for 10 seconds and retrying")
time.sleep(10)
return call_mistral_api(प्रोम्प्ट, model, process_response)
raise e
import re
def process_ollama_response(response):
if response.status_code == 200:
print(f"API से आउटपुट: {response.json()}")
output_text = response.json()["choices"][0]["message"]["content"]
match = re.search(r"Answer:\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"\*\*Answer\*\*:\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct answer is\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct choice is\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct choice would be\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The answer is\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The answer appears to be\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct answer should be\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct answer would be\s*([A-D])", output_text, re.IGNORECASE)
if match:
predicted_answer = match.group(1).upper()
else:
stripped_output = output_text.strip()
if len(stripped_output) > 0:
first_word = stripped_output.split(" ")[0]
if len(first_word) == 1:
predicted_answer = first_word
else:
first_word_comma = stripped_output.split(",")[0]
if len(first_word_comma) == 1:
predicted_answer = first_word_comma
else:
first_word_period = stripped_output.split(".")[0]
if len(first_word_period) == 1:
predicted_answer = first_word_period
else:
print(f"Output से एक अक्षर उत्तर को निकाल नहीं कर सका: {output_text}, रैंडम उत्तर लौट रहा है")
predicted_answer = random.choice(["A", "B", "C", "D"])
else:
predicted_answer = ""
return predicted_answer
else:
print(f"त्रुटि: {response.status_code} - {response.text}")
return ""
def process_llama_response(response):
if response.status_code == 200:
output_text = response.json()["choices"][0]["message"]["content"]
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"API से आउटपुट: {output_text}")
return predicted_answer
else:
print(f"त्रुटि: {response.status_code} - {response.text}")
return ""
def process_deepseek_response(client, prompt, model="deepseek-chat", retries=3, backoff_factor=1):
print(f"Deepseek API को इनपुट: {prompt}")
for attempt in range(retries):
try:
response = client.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": prompt}
],
max_tokens=100
)
if response and response.choices:
output_text = response.choices[0].message.content.strip()
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"API से आउटपुट: {output_text}")
return predicted_answer
else:
print("त्रुटि: API से कोई जवाब नहीं मिला।")
return ""
except Exception as e:
if "502" in str(e):
print(f"Bad gateway error (502) during API call, retrying in {backoff_factor * (2 ** attempt)} seconds...")
time.sleep(backoff_factor * (2 ** attempt))
else:
print(f"API call के दौरान त्रुटि: {e}")
return ""
return ""
def process_mistral_response(response):
if response:
output_text = response.strip()
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"API से आउटपुट: {output_text}")
return predicted_answer
else:
print("त्रुटि: Mistral API से कोई जवाब नहीं मिला")
return ""
def process_gemini_response(prompt):
json_response = call_gemini_api(prompt)
if not json_response:
print("Retry के बाद Gemini API से कोई जवाब नहीं मिला।")
return ""
if 'candidates' not in json_response or not json_response['candidates']:
print("Response में कोई उम्मीदवार नहीं मिला, पुन: प्रयास कर रहा है...")
json_response = call_gemini_api(prompt)
print(json_response)
if not json_response or 'candidates' not in json_response or not json_response['candidates']:
print("Retry के बाद response में कोई उम्मीदवार नहीं मिला।")
return ""
first_candidate = json_response['candidates'][0]
if 'content' in first_candidate and 'parts' in first_candidate['content']:
first_part = first_candidate['content']['parts'][0]
if 'text' in first_part:
output_text = first_part['text']
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"API से आउटपुट: {output_text}")
return predicted_answer
else:
print("Response में कोई पाठ नहीं मिला")
return ""
else:
print("अप्रत्याशित response format: content या parts missing")
return ""
def _call_ollama_api(प्रोम्प्ट, model):
url = "http://localhost:11434/v1/chat/completions"
data = {
"messages": [{"role": "user", "content": prompt}],
"model": model,
"max_tokens": 300
}
headers = {"Content-Type": "application/json"}
print(f"API को इनपुट: {data}")
response = requests.post(url, headers=headers, data=json.dumps(data))
return process_ollama_response(response)
def _call_llama_api(प्रोम्प्ट):
url = "http://localhost:8080/v1/chat/completions"
data = {
"messages": [{"role": "user", "content": prompt}]
}
headers = {"Content-Type": "application/json"}
print(f"API को इनपुट: {data}")
response = requests.post(url, headers=headers, data=json.dumps(data))
return process_llama_response(response)
def _get_predicted_answer(args, prompt, client):
predicted_answer = ""
if args.type == "ollama":
predicted_answer = _call_ollama_api(prompt, args.model)
elif args.type == "llama":
predicted_answer = _call_llama_api(prompt)
elif args.type == "deepseek":
predicted_answer = process_deepseek_response(client, prompt, args.model)
elif args.type == "gemini":
predicted_answer = process_gemini_response(prompt)
elif args.type == "mistral":
predicted_answer = call_mistral_api(prompt, args.model)
else:
raise ValueError("अवैध बैकएंड प्रकार")
return predicted_answer
def evaluate_model(args, dataset):
सही = 0
कुल = 0
client = None
if args.type == "deepseek":
client = initialize_deepseek_client()
if args.model == "":
if args.type == "ollama":
args.model = "mistral:7b"
elif args.type == "deepseek":
args.model = "deepseek-chat"
elif args.type == "mistral":
args.model = "mistral-small-latest"
for i, example in tqdm(enumerate(dataset), total=len(dataset), desc="Evaluating"):
prompt = format_mmlu_prompt(example)
predicted_answer = _get_predicted_answer(args, prompt, client)
answer_map = {0: "A", 1: "B", 2: "C", 3: "D"}
ground_truth_answer = answer_map.get(example["answer"], "")
is_correct = predicted_answer.upper() == ground_truth_answer
if is_correct:
सही += 1
कुल += 1
print(f"प्रश्न: {example['question']}")
print(f"विकल्प: A. {example['choices'][0]}, B. {example['choices'][1]}, C. {example['choices'][2]}, D. {example['choices'][3]}")
print(f"Predicted Answer: {predicted_answer}, Ground Truth: {ground_truth_answer}, Correct: {is_correct}")
print("-" * 30)
if (i+1) % 10 == 0:
accuracy = सही / कुल
print(f"Processed {i+1}/{len(dataset)}. Current Accuracy: {accuracy:.2%} ({सही}/{कुल})")
return सही, कुल
# मूल्यांकन लूप
सही, कुल = evaluate_model(args, dataset)
# दक़ीका
accuracy = सही / कुल
print(f"Subject: {subject}")
print(f"Accuracy: {accuracy:.2%} ({सही}/{कुल})")
परिणाम
Zero-Shot मूल्यांकन
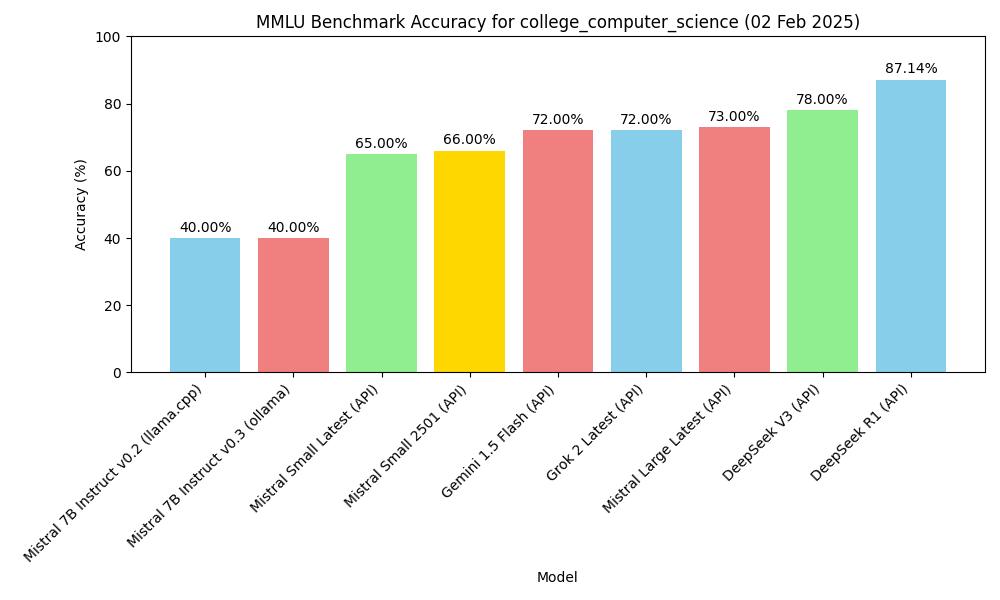
| मॉडल | तरीका | विषय | दक़ीका |
|---|---|---|---|
| mistral-7b-instruct-v0.2, Q4_K_M | macOS m2, 16GB, llama-server | MMLU college_computer_science | 40.00% (40/100) |
| Mistral-7B-Instruct-v0.3, Q4_0 | macOS m2, 16GB, ollama | MMLU college_computer_science | 40.00% (40/100) |
| deepseek v3 (API) | API, 2025.1.25 | MMLU college_computer_science | 78.00% (78/100) |
| gemini-1.5-flash (API) | API, 2025.1.25 | MMLU college_computer_science | 72.00% (72/100) |
| deepseek r1 (API) | API, 2025.1.26 | MMLU college_computer_science | 87.14% (61/70) |
| Mistral Small Latest (API) | API, 2025.01.31 | MMLU college_computer_science | 65.00% (65/100) |
| Mistral Large Latest (API) | API, 2025.01.31 | MMLU college_computer_science | 73.00% (73/100) |
| Mistral Small 2501 (API) | API, 2025.01.31 | MMLU college_computer_science | 66.00% (66/100) |
| Grok 2 Latest | API, 2025.02.02 | MMLU college_computer_science | 72.00% (72/100) |
चित्र
चालू डेटा के आधार पर चित्र बनाएं।
import matplotlib.pyplot as plt
import os
# नमूना डेटा (अपनी वास्तविक डेटा से बदलें)
मॉडल = ['mistral-7b-instruct-v0.2 (llama.cpp)', 'Mistral-7B-Instruct-v0.3 (ollama)', 'deepseek v3 (API)', 'gemini-1.5-flash (API)', 'deepseek r1 (API)']
accuracy = [40.00, 40.00, 78.00, 72.00, 87.14]
subject = "college_computer_science"
# बार चार्ट बनाने के लिए
plt.figure(figsize=(10, 6))
plt.bar(मॉडल, accuracy, color=['skyblue', 'lightcoral', 'lightgreen', 'gold', 'lightcoral'])
plt.xlabel('Model')
plt.ylabel('Accuracy (%)')
plt.title(f'MMLU Benchmark Accuracy for {subject}')
plt.ylim(0, 100) # Set y-axis limit to 0-100 for percentage
plt.xticks(rotation=45, ha="right") # Rotate x-axis labels for better readability
plt.tight_layout()
# बारों पर दक़ीका मूल्य जोड़ें
for i, val in enumerate(accuracy):
plt.text(i, val + 1, f'{val:.2f}%', ha='center', va='bottom')
# चार्ट को वर्तमान डायरेक्टरी में एक JPG फाइल के रूप में सcoal
plt.savefig(os.path.join(os.path.dirname(__file__), f'mmlu_accuracy_chart.jpg'))
plt.show()
 MMLU Benchmark Accuracy
MMLU Benchmark Accuracy