MMLU ベンチマーク | オリジナル、AI翻訳
はじめに
この投稿では、MMLU(Massive Multitask Language Understanding)ベンチマークを使用して言語モデルを評価します。
MMLUベンチマークは、モデルが数学、歴史、法、医学など、さまざまな分野でさまざまなタスクを実行する能力を評価する包括的なテストです。多項選択問題で構成されており、数学、歴史、法、医療など、多様な分野をカバーしています。
データセットのリンク:
llama-server
llama-serverを実行するには:
build/bin/llama-server -m models/7B/mistral-7b-instruct-v0.2.Q4_K_M.gguf --port 8080
MMLUベンチマーク
このスクリプトは、ollama、llama-server、deepseekの3つの異なるバックエンドを使用してMMLUベンチマークを評価します。
MMLUベンチマークコードを実行するには:
import torch
from datasets import load_dataset
import requests
import json
from tqdm import tqdm
import argparse
import os
from openai import OpenAI
from dotenv import load_dotenv
import time
import random
load_dotenv()
# 引数解析の設定
parser = argparse.ArgumentParser(description="異なるバックエンドでMMLUデータセットを評価します。")
parser.add_argument("--type", type=str, default="ollama", choices=["ollama", "llama", "deepseek", "gemini", "mistral"], help="バックエンドの種類: ollama, llama, deepseek, geminiまたはmistral")
parser.add_argument("--model", type=str, default="", help="モデル名")
args = parser.parse_args()
# MMLUデータセットをロード
subject = "college_computer_science" # あなたのSubjectを選択してください
dataset = load_dataset("cais/mmlu", subject, split="test")
# 一回の例を使用してプロンプトをフォーマット
def format_mmlu_prompt(example):
prompt = f"質問: {example['question']}\n"
prompt += "選択肢:\n"
for i, choice in enumerate(example['choices']):
prompt += f"{chr(ord('A') + i)}. {choice}\n"
prompt += "あなたの答えを教えてください。選択肢だけを教えてください。\n"
return prompt
# DeepSeekクライアントを初期化する必要がある場合
def initialize_deepseek_client():
api_key = os.environ.get("DEEPSEEK_API_KEY")
if not api_key:
print("エラー: DEEPSEEK_API_KEY環境変数が設定されていません。")
exit()
return OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
def call_gemini_api(prompt, retries=3, backoff_factor=1):
gemini_api_key = os.environ.get("GEMINI_API_KEY")
if not gemini_api_key:
print("エラー: GEMINI_API_KEY環境変数が設定されていません。")
exit()
url = f"https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent"
params = {"key": gemini_api_key}
payload = {"contents": [{"parts": [{"text": prompt}]}]}
print(f"Gemini APIに入力された内容: {payload}")
for attempt in range(retries):
response = requests.post(url, json=payload, params=params)
response_json = response.json()
print(response_json)
if response.status_code == 200:
return response_json
elif response.status_code == 429:
time.sleep(backoff_factor * (2 ** attempt)) # 指数バックオフ
else:
raise Exception(f"Gemini APIエラー: {response.status_code} - {response_json}")
return None
def call_mistral_api(prompt, model="mistral-small-2501", process_response=True):
api_key = os.environ.get("MISTRAL_API_KEY")
if not api_key:
print("エラー: MISTRAL_API_KEY環境変数が設定されていません。")
return None
url = "https://api.mistral.ai/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": model,
"messages": [
{
"role": "user",
"content": prompt
}
]
}
print(f"Mistral APIに入力された内容: {data}")
print(f"Mistral API URL: {url}")
print(f"Mistral API ヘッダー: {headers}")
try:
response = requests.post(url, headers=headers, json=data)
response.raise_for_status()
response_json = response.json()
print(response_json)
if response_json and response_json['choices']:
content = response_json['choices'][0]['message']['content']
if process_response:
return process_mistral_response(content)
else:
return content
else:
print(f"Mistral APIエラー: 無効な応答形式: {response_json}")
return None
except requests.exceptions.RequestException as e:
print(f"Mistral APIエラー: {e}")
stre = f"{e}"
if '429' in stre:
print("リクエストが多すぎますので、10秒間休憩してから再試行します")
time.sleep(10)
return call_mistral_api(prompt, model, process_response)
raise e
import re
def process_ollama_response(response):
if response.status_code == 200:
print(f"APIからの出力: {response.json()}")
output_text = response.json()["choices"][0]["message"]["content"]
match = re.search(r"Answer:\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"\*\*Answer\*\*:\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct answer is\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct choice is\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct choice would be\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The answer is\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The answer appears to be\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct answer should be\s*([A-D])", output_text, re.IGNORECASE)
if not match:
match = re.search(r"The correct answer would be\s*([A-D])", output_text, re.IGNORECASE)
if match:
predicted_answer = match.group(1).upper()
else:
stripped_output = output_text.strip()
if len(stripped_output) > 0:
first_word = stripped_output.split(" ")[0]
if len(first_word) == 1:
predicted_answer = first_word
else:
first_word_comma = stripped_output.split(",")[0]
if len(first_word_comma) == 1:
predicted_answer = first_word_comma
else:
first_word_period = stripped_output.split(".")[0]
if len(first_word_period) == 1:
predicted_answer = first_word_period
else:
print(f"出力から1文字の回答を抽出できませんでした: {output_text},ランダムな回答を返します")
predicted_answer = random.choice(["A", "B", "C", "D"])
else:
predicted_answer = ""
return predicted_answer
else:
print(f"エラー: {response.status_code} - {response.text}")
return ""
def process_llama_response(response):
if response.status_code == 200:
output_text = response.json()["choices"][0]["message"]["content"]
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"APIからの出力: {output_text}")
return predicted_answer
else:
print(f"エラー: {response.status_code} - {response.text}")
return ""
def process_deepseek_response(client, prompt, model="deepseek-chat", retries=3, backoff_factor=1):
print(f"Deepseek APIに入力された内容: {prompt}")
for attempt in range(retries):
try:
response = client.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": prompt}
],
max_tokens=100
)
if response and response.choices:
output_text = response.choices[0].message.content.strip()
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"APIからの出力: {output_text}")
return predicted_answer
else:
print("エラー: APIからの応答がありません。")
return ""
except Exception as e:
if "502" in str(e):
print(f"API呼び出し中にゲートウェイエラー(502)が発生しました。再試行します。{backoff_factor * (2 ** attempt)}秒後に...")
time.sleep(backoff_factor * (2 ** attempt))
else:
print(f"API呼び出し中にエラーが発生しました: {e}")
return ""
return ""
def process_mistral_response(response):
if response:
output_text = response.strip()
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"APIからの出力: {output_text}")
return predicted_answer
else:
print("Mistral APIからの応答がありません")
return ""
def process_gemini_response(prompt):
json_response = call_gemini_api(prompt)
if not json_response:
print("再試行後にGemini APIからの応答がありません。")
return ""
if 'candidates' not in json_response or not json_response['candidates']:
print("応答に候補が見つからないため、再試行しています...")
json_response = call_gemini_api(prompt)
print(json_response)
if not json_response or 'candidates' not in json_response or not json_response['candidates']:
print("再試行後に応答に候補が見つかりません。")
return ""
first_candidate = json_response['candidates'][0]
if 'content' in first_candidate and 'parts' in first_candidate['content']:
first_part = first_candidate['content']['parts'][0]
if 'text' in first_part:
output_text = first_part['text']
predicted_answer = output_text.strip()[0] if len(output_text.strip()) > 0 else ""
print(f"APIからの出力: {output_text}")
return predicted_answer
else:
print("応答にテキストが見つかりません。")
return ""
else:
print("予期せぬ応答形式: contentまたはpartsが見つかりません。")
return ""
def _call_ollama_api(prompt, model):
url = "http://localhost:11434/v1/chat/completions"
data = {
"messages": [{"role": "user", "content": prompt}],
"model": model,
"max_tokens": 300
}
headers = {"Content-Type": "application/json"}
print(f"APIに入力された内容: {data}")
response = requests.post(url, headers=headers, data=json.dumps(data))
return process_ollama_response(response)
def _call_llama_api(prompt):
url = "http://localhost:8080/v1/chat/completions"
data = {
"messages": [{"role": "user", "content": prompt}]
}
headers = {"Content-Type": "application/json"}
print(f"APIに入力された内容: {data}")
response = requests.post(url, headers=headers, data=json.dumps(data))
return process_llama_response(response)
def _get_predicted_answer(args, prompt, client):
predicted_answer = ""
if args.type == "ollama":
predicted_answer = _call_ollama_api(prompt, args.model)
elif args.type == "llama":
predicted_answer = _call_llama_api(prompt)
elif args.type == "deepseek":
predicted_answer = process_deepseek_response(client, prompt, args.model)
elif args.type == "gemini":
predicted_answer = process_gemini_response(prompt)
elif args.type == "mistral":
predicted_answer = call_mistral_api(prompt, args.model)
else:
raise ValueError("無効なバックエンドの種類")
return predicted_answer
def evaluate_model(args, dataset):
correct = 0
total = 0
client = None
if args.type == "deepseek":
client = initialize_deepseek_client()
if args.model == "":
if args.type == "ollama":
args.model = "mistral:7b"
elif args.type == "deepseek":
args.model = "deepseek-chat"
elif args.type == "mistral":
args.model = "mistral-small-latest"
for i, example in tqdm(enumerate(dataset), total=len(dataset), desc="評価中"):
prompt = format_mmlu_prompt(example)
predicted_answer = _get_predicted_answer(args, prompt, client)
answer_map = {0: "A", 1: "B", 2: "C", 3: "D"}
ground_truth_answer = answer_map.get(example["answer"], "")
is_correct = predicted_answer.upper() == ground_truth_answer
if is_correct:
correct += 1
total += 1
print(f"質問: {example['question']}")
print(f"選択肢: A. {example['choices'][0]}, B. {example['choices'][1]}, C. {example['choices'][2]}, D. {example['choices'][3]}")
print(f"予測された回答: {predicted_answer}, 正解: {ground_truth_answer}, 正しい: {is_correct}")
print("-" * 30)
if (i+1) % 10 == 0:
accuracy = correct / total
print(f"{i+1}/{len(dataset)}を処理しました。現在の正確性: {accuracy:.2%} ({correct}/{total})")
return correct, total
# 評価ループ
correct, total = evaluate_model(args, dataset)
# 正確性を計算
accuracy = correct / total
print(f"Subject: {subject}")
print(f"正確性: {accuracy:.2%} ({correct}/{total})")
結果
ゼロショット評価
| モデル | 方法 | Subject | 正確性 |
|---|---|---|---|
| mistral-7b-instruct-v0.2, Q4_K_M | macOS m2, 16GB, llama-server | MMLU college_computer_science | 40.00% (40/100) |
| Mistral-7B-Instruct-v0.3, Q4_0 | macOS m2, 16GB, ollama | MMLU college_computer_science | 40.00% (40/100) |
| deepseek v3 (API) | API, 2025.1.25 | MMLU college_computer_science | 78.00% (78/100) |
| gemini-1.5-flash (API) | API, 2025.1.25 | MMLU college_computer_science | 72.00% (72/100) |
| deepseek r1 (API) | API, 2025.1.26 | MMLU college_computer_science | 87.14% (61/70) |
| Mistral Small Latest (API) | API, 2025.01.31 | MMLU college_computer_science | 65.00% (65/100) |
| Mistral Large Latest (API) | API, 2025.01.31 | MMLU college_computer_science | 73.00% (73/100) |
| Mistral Small 2501 (API) | API, 2025.01.31 | MMLU college_computer_science | 66.00% (66/100) |
| Grok 2 Latest | API, 2025.02.02 | MMLU college_computer_science | 72.00% (72/100) |
フィギュア
上記のチャートに基づいて図を作成します。
import matplotlib.pyplot as plt
import os
# サンプルデータ(実際のデータに変更してください)
models = ['mistral-7b-instruct-v0.2 (llama.cpp)', 'Mistral-7B-Instruct-v0.3 (ollama)', 'deepseek v3 (API)', 'gemini-1.5-flash (API)', 'deepseek r1 (API)']
accuracy = [40.00, 40.00, 78.00, 72.00, 87.14]
subject = "college_computer_science"
# 棒グラフを作成
plt.figure(figsize=(10, 6))
plt.bar(models, accuracy, color=['skyblue', 'lightcoral', 'lightgreen', 'gold', 'lightcoral'])
plt.xlabel('モデル')
plt.ylabel('正確性 (%)')
plt.title(f'{subject}のMMLUベンチマーク正確性')
plt.ylim(0, 100) # 正確性の範囲を0-100に設定
plt.xticks(rotation=45, ha="right") # x軸のラベルを回転させて読みやすくします
plt.tight_layout()
# 棒の上に正確性値を追加
for i, val in enumerate(accuracy):
plt.text(i, val + 1, f'{val:.2f}%', ha='center', va='bottom')
# チャートをJPGファイルとして現行ディレクトリに保存
plt.savefig(os.path.join(os.path.dirname(__file__), f'mmlu_accuracy_chart.jpg'))
plt.show()
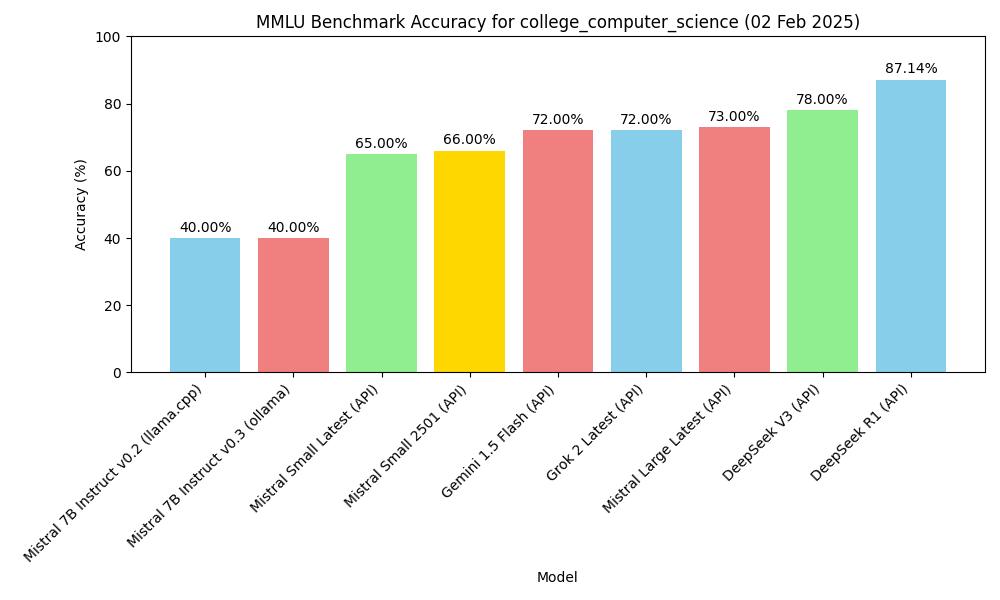 MMLUベンチマーク正確性
MMLUベンチマーク正確性