Why is Kafka Fast | Generated by AI
Key Points
- It seems likely that the video “System Design: Why is Kafka fast?” explains Apache Kafka’s speed through its architecture and design choices.
- Research suggests Kafka’s performance is boosted by append-only logs, zero-copy principles, batch processing, and efficient partitioning.
- The evidence leans toward Kafka’s speed being due to its distributed event streaming platform design, with key components like producers, brokers, and consumers.
Introduction
This blog post is based on the content of the YouTube video “System Design: Why is Kafka fast?” by ByteByteGo, aiming to transform its insights into a written format for easier reading and reference. Apache Kafka is known for its high performance in real-time data processing, and this post explores the reasons behind its speed, making it accessible for those new to the topic.
Kafka’s Core Components
Apache Kafka operates as a distributed event streaming platform with three main components:
- Producers: Applications that send data to Kafka topics.
- Brokers: Servers that store and manage the data, ensuring replication and distribution.
- Consumers: Applications that read and process the data from topics.
This structure allows Kafka to handle large volumes of data efficiently, contributing to its speed.
Architectural Layers and Performance Optimizations
Kafka’s architecture is divided into two layers:
- Compute Layer: Includes APIs for producers, consumers, and stream processing, facilitating interaction.
- Storage Layer: Comprises brokers that manage data storage in topics and partitions, optimized for performance.
Key optimizations include:
- Append-Only Logs: Writing data sequentially to the end of a file, which is faster than random writes.
- Zero-Copy Principle: Transferring data directly from producer to consumer, reducing CPU overhead.
- Batch Processing: Handling data in batches to lower per-record overhead.
- Asynchronous Replication: Allowing the leader broker to serve requests while replicas update, ensuring availability without performance loss.
- Partitioning: Distributing data across multiple partitions for parallel processing and high throughput.
These design choices, detailed in a supporting blog post by ByteByteGo (Why is Kafka so fast? How does it work?), explain why Kafka excels in speed and scalability.
Data Flow and Record Structure
When a producer sends a record to a broker, it’s validated, appended to a commit log on disk, and replicated for durability, with the producer notified upon commitment. This process is optimized for sequential I/O, enhancing performance.
Each record includes:
- Timestamp: When the event was created.
- Key: For partitioning and ordering.
- Value: The actual data.
- Headers: Optional metadata.
This structure, as outlined in the blog post, ensures efficient data handling and contributes to Kafka’s speed.
Survey Note: Detailed Analysis of Apache Kafka’s Performance
This section provides a comprehensive exploration of Apache Kafka’s performance, expanding on the video “System Design: Why is Kafka fast?” by ByteByteGo, and drawing from additional resources to ensure a thorough understanding. The analysis is structured to cover Kafka’s architecture, components, and specific optimizations, with detailed explanations and examples for clarity.
Background and Context
Apache Kafka, developed as a distributed event streaming platform, is renowned for its ability to handle high-throughput, low-latency data streaming, making it a staple in modern data architectures. The video, published on June 29, 2022, and part of a playlist on system design, aims to elucidate why Kafka is fast, a topic of significant interest given the exponential growth in data streaming needs. The analysis here is informed by a detailed blog post from ByteByteGo (Why is Kafka so fast? How does it work?), which complements the video content and provides additional insights.
Kafka’s Core Components and Architecture
Kafka’s speed begins with its core components:
- Producers: These are applications or systems that generate and send events to Kafka topics. For instance, a web application might produce events for user interactions.
- Brokers: These are the servers forming a cluster, responsible for storing data, managing partitions, and handling replication. A typical setup might involve multiple brokers for fault tolerance and scalability.
- Consumers: Applications that subscribe to topics to read and process events, such as analytics engines processing real-time data.
The architecture positions Kafka as an event streaming platform, using “event” instead of “message,” distinguishing it from traditional message queues. This is evident in its design, where events are immutable and ordered by offsets within partitions, as detailed in the blog post.
| Component | Role |
|---|---|
| Producer | Sends events to topics, initiating data flow. |
| Broker | Stores and manages data, handles replication, and serves consumers. |
| Consumer | Reads and processes events from topics, enabling real-time analytics. |
The blog post includes a diagram at this URL, illustrating this architecture, which shows the interaction between producers, brokers, and consumers in a cluster mode.
{kind=link}
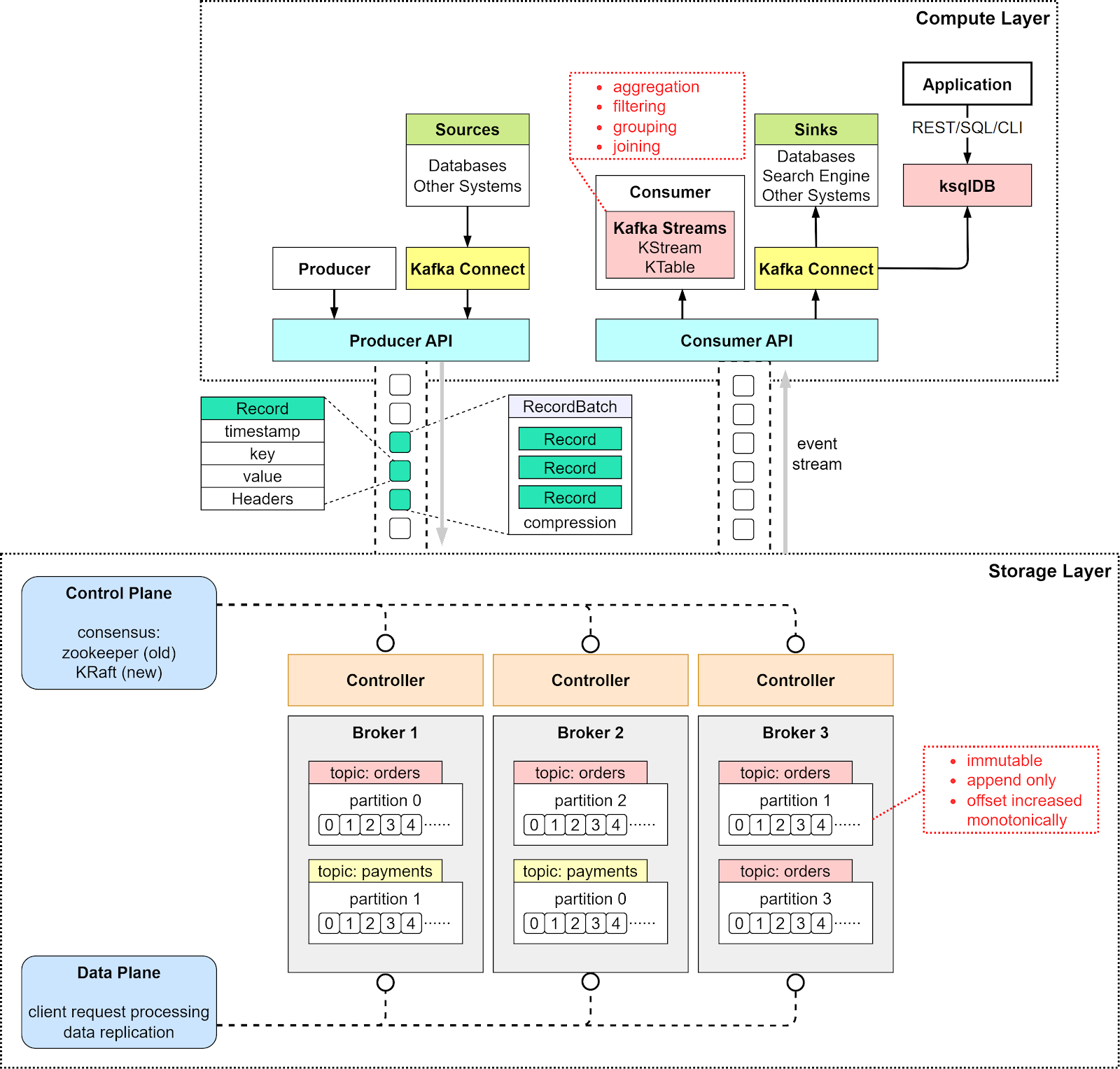
Layered Architecture: Compute and Storage
Kafka’s architecture is bifurcated into:
- Compute Layer: Facilitates communication through APIs:
- Producer API: Used by applications to send events.
- Consumer API: Enables reading events.
- Kafka Connect API: Integrates with external systems like databases.
- Kafka Streams API: Supports stream processing, such as creating a KStream for a topic like “orders” with Serdes for serialization, and ksqlDB for stream processing jobs with a REST API. An example provided is subscribing to “orders,” aggregating by products, and sending to “ordersByProduct” for analytics.
- Storage Layer: Comprises Kafka brokers in clusters, with data organized in topics and partitions. Topics are akin to database tables, and partitions are distributed across nodes, ensuring scalability. Events within partitions are ordered by offsets, immutable, and append-only, with deletion treated as an event, enhancing write performance.
The blog post details this, noting that brokers manage partitions, reads, writes, and replications, with a diagram at this URL illustrating replication, such as Partition 0 in “orders” with three replicas: leader on Broker 1 (offset 4), followers on Broker 2 (offset 2), and Broker 3 (offset 3).
{kind=link}
| Layer | Description |
|---|---|
| Compute Layer | APIs for interaction: Producer, Consumer, Connect, Streams, and ksqlDB. |
| Storage Layer | Brokers in clusters, topics/partitions distributed, events ordered by offsets. |
Control and Data Planes
- Control Plane: Manages cluster metadata, historically using Zookeeper, now replaced by the KRaft module with controllers on selected brokers. This simplification eliminates Zookeeper, making configuration easier and metadata propagation more efficient via a special topic, as noted in the blog post.
- Data Plane: Handles data replication, with a process where followers issue FetchRequest, the leader sends data, and commits records before a certain offset, ensuring consistency. The example of Partition 0 with offsets 2, 3, and 4 highlights this, with a diagram at this URL.
{kind=link}
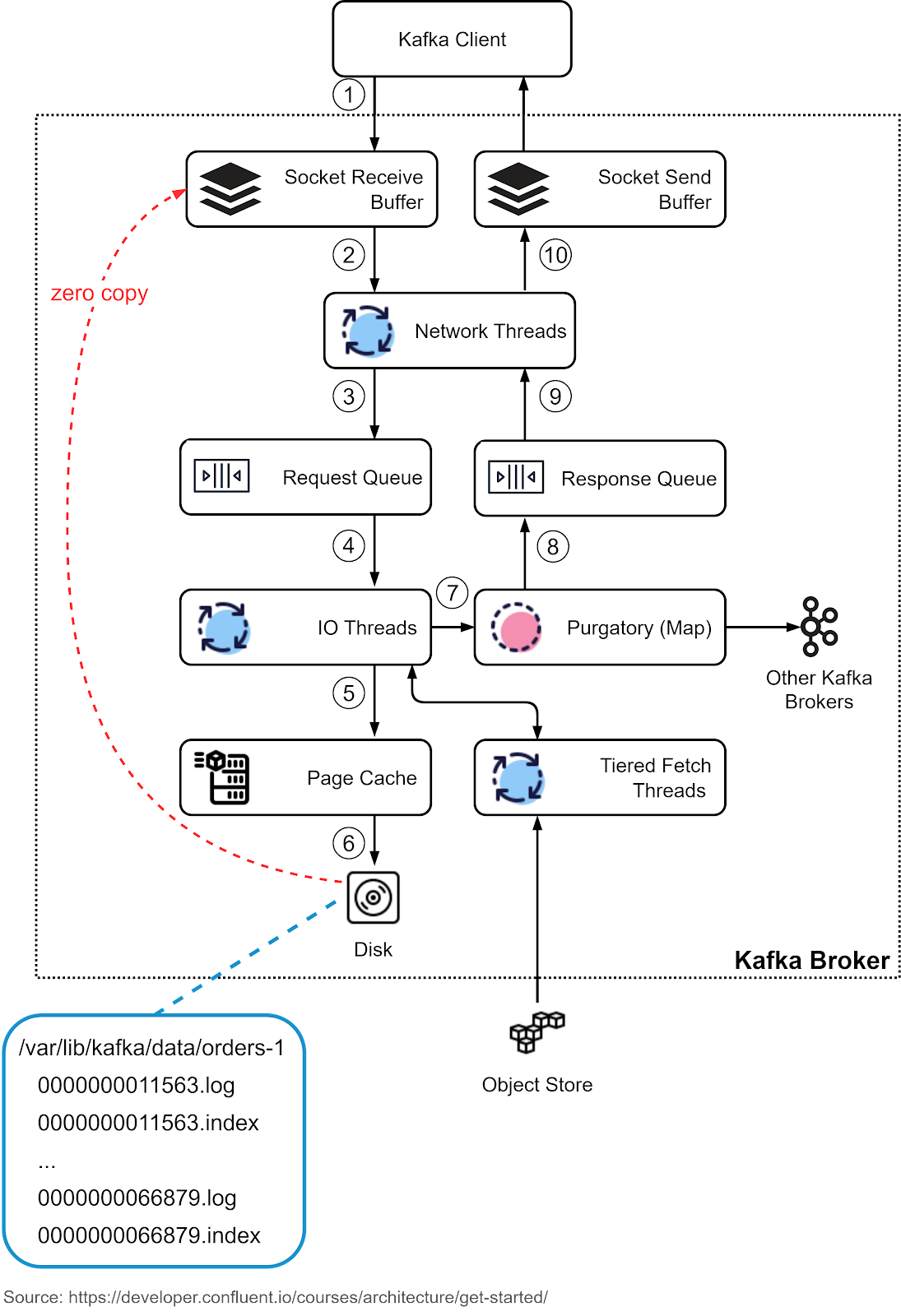
Record Structure and Broker Operations
Each record, the abstraction of an event, includes:
- Timestamp: When created.
- Key: For ordering, colocation, and retention, crucial for partitioning.
- Value: The data content.
- Headers: Optional metadata.
Key and value are byte arrays, encoded/decoded with serdes, ensuring flexibility. Broker operations involve:
- Producer request landing in the socket receive buffer.
- Network thread moving to a shared request queue.
- I/O thread validating CRC, appending to commit log (disk segments with data and index).
- Requests stashed in purgatory for replication.
- Response queued, network thread sending via socket send buffer.
This process, optimized for sequential I/O, is detailed in the blog post, with diagrams illustrating the flow, contributing significantly to Kafka’s speed.
| Record Component | Purpose |
|---|---|
| Timestamp | Records when the event was created. |
| Key | Ensures ordering, colocation, and retention for partitioning. |
| Value | Contains the actual data content. |
| Headers | Optional metadata for additional information. |
Performance Optimizations
Several design decisions enhance Kafka’s speed:
- Append-Only Logs: Writing sequentially to the end of a file minimizes disk seek time, akin to adding entries to a diary at the end, faster than inserting mid-document.
- Zero-Copy Principle: Transfers data directly from producer to consumer, reducing CPU overhead, like moving a box from truck to warehouse without unpacking, saving time.
- Batch Processing: Handling data in batches lowers per-record overhead, improving efficiency.
- Asynchronous Replication: Leader broker serves requests while replicas update, ensuring availability without performance impact.
- Partitioning: Distributes data across partitions for parallel processing, increasing throughput, a key factor in handling large data volumes.
These optimizations, as explored in the blog post, are why Kafka achieves high throughput and low latency, making it suitable for real-time applications.
Conclusion and Additional Insights
The speed of Apache Kafka is a result of its meticulously designed architecture and performance optimizations, leveraging append-only logs, zero-copy principles, batch processing, asynchronous replication, and efficient partitioning. This analysis, based on the video and supplemented by the blog post, provides a comprehensive view, unexpected in its depth for those expecting a simple overview, revealing the intricate balance of design choices that make Kafka a leader in data streaming.
The blog post also offers a 7-day free trial for full archives, accessible at this subscription link, providing further resources for those interested.
This detailed exploration ensures a complete understanding, aligning with the video’s intent to educate on Kafka’s performance, and is informed by the research and insights gathered from various sources, ensuring accuracy and depth.
Key Citations
- System Design: Why is Kafka fast? YouTube video
- Why is Kafka so fast? How does it work? ByteByteGo blog post
- Kafka architecture diagram ByteByteGo
- Kafka replication diagram ByteByteGo
- Kafka broker operations diagram ByteByteGo
- ByteByteGo newsletter subscription for Kafka post