GFW、プロキシアピ、VPN検出 | オリジナル、AI翻訳
目次
- プロキシサーバー内のAPIはGFWによるブロックを回避できるか?
- プロキシとAPIトラフィックの混在でGFWブロックを回避
- GFWはプロキシと通常のHTTP/HTTPSトラフィックを区別
- GFWはプロキシ専用トラフィックに基づいてブロック
- GFWはトラフィック解析に時間ウィンドウを使用
- 定期的なAPIアクセスで検出を回避可能
- Great Firewall(GFW)の仕組み
- GFWはリクエストの送信元と宛先データをログ記録
- 不正アクティビティ関連IPをブロック
- 特定プロトコルの検出ルールを使用
- 不正リクエストの割合に基づいてブロック
- AIによるインテリジェントなトラフィックパターン検出を採用
- ChatGPT iOSのVPN検出分析
- ChatGPT iOSは一部VPNで利用可能に
- アクセスはVPNサーバーのロケーションに依存
- 検出は特定IPアドレスに基づく
- 一部クラウドプロバイダーのIPがブロック対象
プロキシサーバー内のAPIはGFWによるブロックを回避できるか?
Shadowsocksインスタンス上で以下のコードを使用した簡易サーバーを運用しています:
from flask import Flask, jsonify
from flask_cors import CORS
import subprocess
app = Flask(__name__)
CORS(app) # 全てのルートでCORSを有効化
@app.route('/bandwidth', methods=['GET'])
def get_bandwidth():
# eth0の5分間隔トラフィック統計をvnstatコマンドで取得
result = subprocess.run(['vnstat', '-i', 'eth0', '-5', '--json'], capture_output=True, text=True)
data = result.stdout
# JSONレスポンスとしてデータを返却
return jsonify(data)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
また、nginxを使用して443ポートを以下のように設定しています:
server {
listen 443 ssl;
server_name www.some-domain.xyz;
ssl_certificate /etc/letsencrypt/live/www.some-domain.xyz/fullchain.pem; # managed by
# ...
location / {
proxy_pass http://127.0.0.1:5000/;
# ...
}
}
このサーバープログラムはネットワークデータを提供し、プロキシサーバーとして使用することで、ブログ上にネットワークデータを基にオンラインステータスを表示しています。
興味深いのは、このサーバーがGreat Firewall(GFW)やその他のネットワーク制御システムによるブロックを数日間受けていない点です。通常、私が設定したプロキシサーバーは1〜2日以内にブロックされます。このサーバーは51939ポートでShadowsocksプログラムを実行しているため、Shadowsocksトラフィックと通常のAPIトラフィックが混在しています。この混在がGFWに対して、このサーバーが専用プロキシではなく通常のサーバーであると誤認させ、IPブロックを回避しているようです。
この観察結果は興味深いものです。GFWは特定のロジックを使用してプロキシトラフィックと通常トラフィックを区別していると考えられます。TwitterやYouTubeなど多くのウェブサイトが中国でブロックされている一方で、国際的な大学や企業のウェブサイトなど、多くの海外サイトはアクセス可能です。
これはGFWが通常のHTTP/HTTPSトラフィックとプロキシ関連トラフィックを区別するルールに基づいて動作していることを示唆しています。両方のトラフィックを処理するサーバーはブロックを回避しやすい一方、プロキシトラフィックのみを処理するサーバーはブロックされやすいようです。
疑問点は、GFWがブロック判定のためにデータを蓄積する時間範囲です—1日なのか1時間なのか。この時間範囲内でトラフィックがプロキシ専用かどうかを検出し、プロキシ専用であればサーバーのIPがブロックされる仕組みです。
私はブログを頻繁に訪問して記事を確認していますが、今後数週間はブログ記事の執筆よりも他のタスクに集中する予定です。これにより、443ポート経由のbandwidth APIへのアクセスが減少します。再びブロックされた場合は、GFWを欺くために定期的にこのAPIにアクセスするプログラムを作成するべきでしょう。
Great Firewall(GFW)の仕組み
ステップ1:リクエストのログ記録
import time
# リクエストデータを保存するデータベース
request_log = []
# リクエストをログ記録する関数
def log_request(source_ip, target_ip, target_port, body):
request_log.append({
'source_ip': source_ip,
'target_ip': target_ip,
'target_port': target_port,
'body': body,
'timestamp': time.time()
})
log_request関数は、送信元IP、宛先IP、宛先ポート、リクエストボディ、タイムスタンプなどの重要な情報を含む着信リクエストを記録します。
ステップ2:IPのチェックとブロック
# リクエストをチェックしIPをブロックする関数
def check_and_ban_ips():
banned_ips = set()
# ログ記録された全リクエストをイテレーション
for request in request_log:
if is_illegal(request):
banned_ips.add(request['target_ip'])
else:
banned_ips.discard(request['target_ip'])
# 識別されたIPをブロック
ban_ips(banned_ips)
check_and_ban_ips関数は、ログ記録された全リクエストをイテレーションし、不正アクティビティに関連するIPを識別・ブロックします。
ステップ3:不正リクエストの定義
# リクエストが不正かどうかをチェックする関数
def is_illegal(request):
# 実際の不正リクエストチェックロジックのプレースホルダー
# 例:リクエストボディや宛先のチェック
return "illegal" in request['body']
ここで、is_illegalはリクエストボディに「illegal」という単語が含まれているかどうかをチェックします。不正アクティビティの定義に応じて、より高度なロジックに拡張可能です。
ステップ4:識別されたIPのブロック
# IPリストをブロックする関数
def ban_ips(ip_set):
for ip in ip_set:
print(f"Banning IP: {ip}")
不正IPが識別されると、ban_ips関数がそれらのIPをブロックします(実際のシステムではブロック処理を行います)。
ステップ5:80%以上の不正リクエストに基づくIPブロック
# 80%以上の不正リクエストに基づいてIPをブロックする関数
def check_and_ban_ips():
banned_ips = set()
illegal_count = 0
total_requests = 0
# ログ記録された全リクエストをイテレーション
for request in request_log:
total_requests += 1
if is_illegal(request):
illegal_count += 1
# 80%以上のリクエストが不正の場合、該当IPをブロック
if total_requests > 0 and (illegal_count / total_requests) >= 0.8:
for request in request_log:
if is_illegal(request):
banned_ips.add(request['target_ip'])
# 識別されたIPをブロック
ban_ips(banned_ips)
この代替手法は、IPがブロックされるかどうかを不正リクエストの割合に基づいて評価します。IPからのリクエストの80%以上が不正の場合、そのIPはブロックされます。
ステップ6:不正リクエストチェックの強化(ShadowsocksやTrojanプロトコルの検出)
def is_illegal(request):
# Shadowsocksプロトコルの使用をチェック(ボディにバイナリデータが含まれる場合)
if request['target_port'] == 443:
if is_trojan(request):
return True
elif is_shadowsocks(request):
return True
return False
is_illegal関数は、ShadowsocksやTrojanなどの特定プロトコルもチェックします:
- Shadowsocks:リクエストボディに暗号化またはバイナリデータが含まれるか。
- Trojan:リクエストが443ポート(HTTPS)を経由し、特定パターン(Trojanトラフィックの特徴)に一致する場合、不正と判定。
ステップ7:合法リクエストの例
例えば、GET https://some-domain.xyz/bandwidthのようなリクエストは明らかに合法であり、ブロックメカニズムをトリガーしません。
ステップ8:プロキシサーバートラフィックの特徴
プロキシサーバーのトラフィック特徴は、通常のウェブやAPIサーバーと大きく異なります。GFWは通常のウェブサーバートラフィックとプロキシサーバートラフィックを区別する必要があり、これらは全く異なるパターンを示します。
ステップ9:機械学習とAIモデルによるスマート検出
インターネットを通過する様々なリクエストとレスポンスを考慮すると、GFWはAIや機械学習モデルを使用してトラフィックパターンを分析し、不正行為をインテリジェントに検出する可能性があります。システムを様々なトラフィックタイプでトレーニングし、高度な技術を使用することで、観察されたパターンに基づいてより効果的にトラフィックをブロックまたはフィルタリングできます。
更新情報
私の努力にもかかわらず、プロキシサーバーは引き続きブロックされています。これを緩和するため、Digital OceanのリバースIP機能を使用して、ブロックが発生するたびに新しいIPアドレスを迅速に割り当てる回避策を実装しました。
ChatGPT iOSのVPN検出分析
2024.12.26
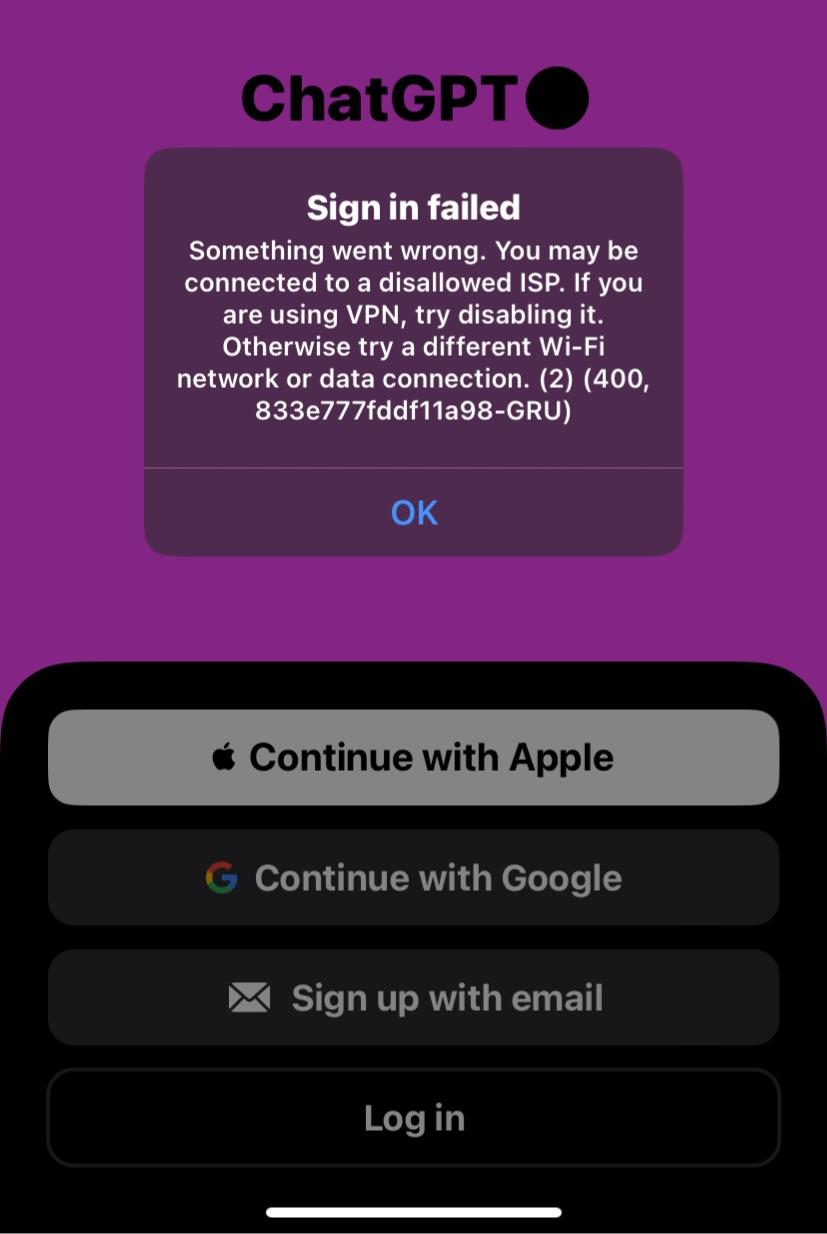
本日、ChatGPTのiOSアプリが中国国内でVPNを使用してログイン可能になったことを確認しました。以前は、以下のようなブロックプロンプトが表示されていました。
しかし、現在はVPNを使用しても問題なく動作します。
ChatGPT iOSアプリが最初にリリースされた際は、VPNを使用しても問題なかったことを覚えています。その後、VPN検出が厳格化され、ログインが困難になりました。最近になってこの制限が緩和されたようです。
さらにテストしたところ、DigitalOceanのシンガポールリジョンのVPNを使用した場合はアプリにアクセスできませんでしたが、台湾や英国のVPN(https://zhs.cloud提供)を使用した場合は正常に動作しました。
ChatGPT iOSのVPN検出は特定のIPアドレスに基づいて行われているようです。一部のクラウドプロバイダーまたは特定のIPアドレスがブロックされているため、VPNサーバーのロケーションによって動作が不一致になる可能性があります。