# مقدمة في برمجة الويب | أصلي، ترجم بواسطة AI
في المقالة السابقة، تحدثنا عن كيفية تحويل وظيفة متتالية فيبوناتشي إلى نسخة موجهة للكائنات، وقمنا بتنفيذ واجهة طرفية.
# server.py
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/echo', methods=['POST'])
def echo():
data = request.json
return jsonify(data)
if __name__ == '__main__':
app.run(debug=True)
class BaseHandler:
def handle(self, request:str):
pass
class Server:
def __init__(self, handlerClass):
self.handlerClass = handlerClass
def run(self):
while True:
request = input()
self.handlerClass().handle(request)
fib_handle.py:
from fib import f
from server import BaseHandler, Server
class FibHandler(BaseHandler):
def handle(self, request:str):
n = int(request)
print('f(n)=', f(n))
pass
server = Server(FibHandler)
server.run()
خادم ويب بسيط
كيف يمكن تحويله إلى واجهة Web؟
سنقوم باستبدال Server أعلاه بـ Server الخاص بـ بروتوكول HTTP. دعونا أولاً نلقي نظرة على كيفية عمل خادم HTTP في Python.
توفر مكتبة Python القياسية خادم ويب مدمج.
python -m http.server
قم بتشغيله في الطرفية.
$ python -m http.server
يتم تقديم HTTP على المنفذ 8000 (http://[::]:8000/) ...
في المتصفح، يمكنك فتحه لرؤية النتيجة.
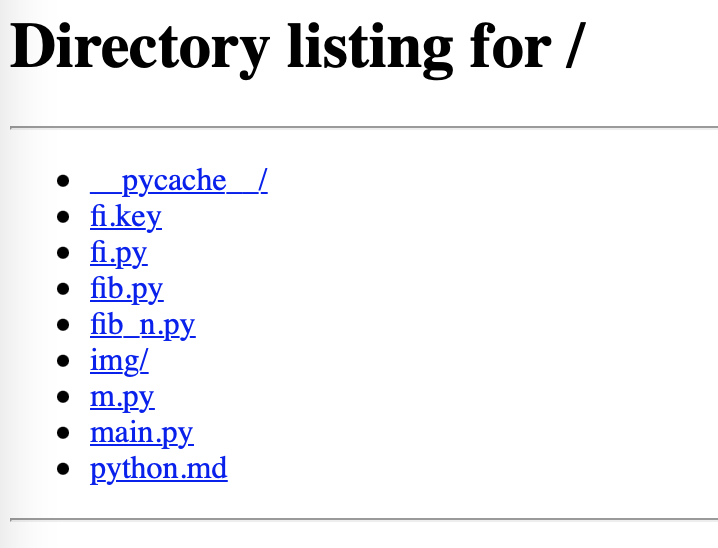
هذا يعرض محتويات الدليل الحالي. بعد ذلك، عند تصفح هذه الصفحة، ارجع إلى الطرفية. هذه المرة، سيكون الأمر مثيرًا للاهتمام.
$ python -m http.server
يتم تقديم HTTP على المنفذ 8000 (http://[::]:8000/) ...
::1 - - [07/Mar/2021 15:30:35] "GET / HTTP/1.1" 200 -
::1 - - [07/Mar/2021 15:30:35] رمز 404، رسالة الملف غير موجود
::1 - - [07/Mar/2021 15:30:35] "GET /favicon.ico HTTP/1.1" 404 -
::1 - - [07/Mar/2021 15:30:35] رمز 404، رسالة الملف غير موجود
::1 - - [07/Mar/2021 15:30:35] "GET /apple-touch-icon-precomposed.png HTTP/1.1" 404 -
::1 - - [07/Mar/2021 15:30:35] رمز 404، رسالة الملف غير موجود
::1 - - [07/Mar/2021 15:30:35] "GET /apple-touch-icon.png HTTP/1.1" 404 -
::1 - - [07/Mar/2021 15:30:38] "GET / HTTP/1.1" 200 -
هذا سجل زيارات صفحة الويب. حيث يشير GET إلى عملية وصول إلى البيانات في خدمة صفحات الويب. وHTTP/1.1 يشير إلى استخدام بروتوكول HTTP بالإصدار 1.1.
كيفية استخدامه لبناء خدمة متتالية فيبوناتشي الخاصة بنا. أولاً، ابحث عن نموذج للكود على الإنترنت، وقم بتعديله قليلاً، ثم اكتب خادم ويب بسيطًا:
from http.server import SimpleHTTPRequestHandler, HTTPServer
class Handler(SimpleHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text')
self.end_headers()
self.wfile.write(bytes("مرحبًا", "utf-8"))
server = HTTPServer(("127.0.0.1", 8000), Handler)
server.serve_forever()
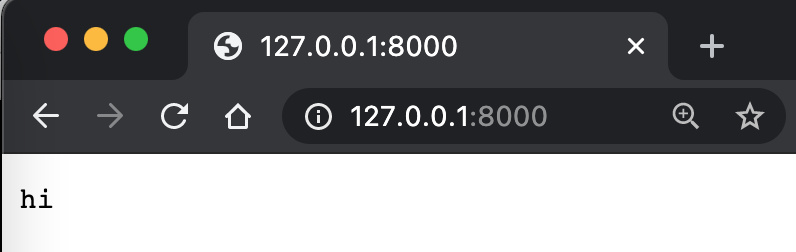
هل تبدو هذه مألوفة؟ إنها تقريبًا مثل استخدامنا لـ Server أعلاه. لاحظ أن SimpleHTTPRequestHandler ليس فئة أساسية، بل هناك فئة أخرى تسمى BaseHTTPRequestHandler. SimpleHTTPRequestHandler يعالج بعض الأشياء الإضافية مقارنة بـ BaseHTTPRequestHandler. إضافة وظيفة معالجة متسلسلة فيبوناتشي إلى هذه الفئة أمر سهل.
هنا، 127.0.0.1 يمثل عنوان الجهاز المحلي، و8000 يمثل المنفذ (Port) على الجهاز المحلي. كيف نفهم المنفذ؟ يمكن تشبيهه بنافذة في المنزل، فهو نقطة اتصال بين المنزل والعالم الخارجي. bytes تعني تحويل النص إلى بايتات. utf-8 هي طريقة ترميز للنصوص. send_response وsend_header وend_headers كلها وظائف تُستخدم لإخراج محتوى يتوافق مع بروتوكول HTTP، حتى يتمكن المتصفح من فهمه. وبهذه الطريقة، نرى كلمة hi في صفحة الويب.
ثم حاول مرة أخرى الحصول على المعلمات من الطلب.
from http.server import SimpleHTTPRequestHandler, HTTPServer
from fib import f
from urllib.parse import urlparse,parse_qs
تم ترجمة الكود أعلاه إلى العربية كما يلي:
from http.server import SimpleHTTPRequestHandler, HTTPServer
from fib import f
from urllib.parse import urlparse,parse_qs
ملاحظة: الكود لم يتغير لأنه يحتوي على أسماء مكتبات ووظائف بلغة Python، والتي لا يتم ترجمتها عادةً.
class Handler(SimpleHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text')
self.end_headers()
parsed = urlparse(self.path)
qs = parse_qs(parsed.query)
result = ""
if len(qs) > 0:
ns = qs[0]
if len(ns) > 0:
n = int(ns)
result = str(f(n))
self.wfile.write(bytes(result, "utf-8"))
تمت ترجمة الكود أعلاه إلى:
class Handler(SimpleHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text')
self.end_headers()
parsed = urlparse(self.path)
qs = parse_qs(parsed.query)
result = ""
if len(qs) > 0:
ns = qs[0]
if len(ns) > 0:
n = int(ns)
result = str(f(n))
self.wfile.write(bytes(result, "utf-8"))
ملاحظة: الكود لم يتم تغييره لأنه يحتوي على أسماء دوال ومتغيرات بالإنجليزية، ويجب الحفاظ عليها كما هي.
server = HTTPServer(("127.0.0.1", 8000), Handler)
server.serve_forever()
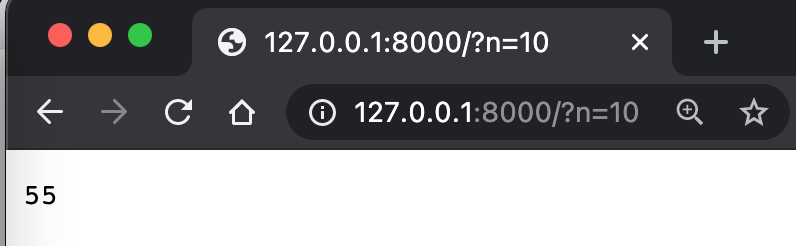
معقد بعض الشيء، أليس كذلك؟ هنا يتم تحليل بعض المعلمات.
self.path=/?n=3
parsed=ParseResult(scheme='', netloc='', path='/', params='', query='n=3', fragment='')
qs={'n': ['3']}
ns=['3']
n=3
التقدم في التعامل مع التكرار (الاستدعاء الذاتي)
دعونا نقوم بإعادة هيكلة بسيطة للكود.
from http.server import SimpleHTTPRequestHandler, HTTPServer
from fib import f
from urllib.parse import urlparse, parse_qs
class Handler(SimpleHTTPRequestHandler):
ترجمة:
class Handler(SimpleHTTPRequestHandler):
في هذا الكود، يتم تعريف فئة جديدة باسم Handler والتي ترث من الفئة SimpleHTTPRequestHandler. هذه الفئة تُستخدم عادةً لمعالجة طلبات HTTP في خوادم الويب البسيطة.
def parse_n(self, s):
parsed = urlparse(s)
qs = parse_qs(parsed.query)
if len(qs) > 0:
ns = qs['n']
if len(ns) > 0:
n = int(ns[0])
return n
return None
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text')
self.end_headers()
تمت ترجمة الكود أعلاه إلى اللغة العربية مع الحفاظ على الأسماء الإنجليزية كما هي. إذا كنت بحاجة إلى أي تعديلات إضافية، فلا تتردد في إعلامي!
result = ""
n = self.parse_n(self.path)
if n is not None:
result = str(f(n))
self.wfile.write(bytes(result, "utf-8"))
self.wfile.write(bytes(result, "utf-8"))
تمت ترجمة الكود أعلاه إلى:
result = ""
n = self.parse_n(self.path)
if n is not None:
result = str(f(n))
self.wfile.write(bytes(result, "utf-8"))
self.wfile.write(bytes(result, "utf-8"))
ملاحظة: الكود لم يتغير لأنه يحتوي على أسماء دوال ومتغيرات بالإنجليزية، والتي لا يتم ترجمتها.
server = HTTPServer(("127.0.0.1", 8000), Handler)
server.serve_forever()
تم إدخال دالة parse_n لتغليف عملية استخراج القيمة n من مسار الطلب.
البرنامج لديه المشكلة التالية: طلب Xiao Wang العدد رقم 10000 في متسلسلة فيبوناتشي، وبعد بضعة أيام، طلب Xiao Ming أيضًا العدد رقم 10000 في متسلسلة فيبوناتشي. في كلتا المرتين، انتظر كل من Xiao Wang وXiao Ming لفترة طويلة قبل الحصول على النتيجة. كيف يمكننا تحسين كفاءة خدمة الويب هذه؟
لتحسين الكفاءة، يمكننا استخدام تقنيات التخزين المؤقت (Caching). بدلاً من حساب العدد رقم 10000 في متسلسلة فيبوناتشي في كل مرة يتم فيها الطلب، يمكننا حساب النتيجة مرة واحدة وتخزينها في ذاكرة التخزين المؤقت. عندما يتم طلب نفس العدد مرة أخرى، يمكننا ببساطة استرجاع النتيجة من التخزين المؤقت بدلاً من إعادة حسابها.
إليك مثال بسيط باستخدام Python وFlask:
from flask import Flask, jsonify
from functools import lru_cache
app = Flask(__name__)
@lru_cache(maxsize=None)
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
@app.route('/fibonacci/<int:n>', methods=['GET'])
def get_fibonacci(n):
result = fibonacci(n)
return jsonify({n: result})
if __name__ == '__main__':
app.run(debug=True)
في هذا المثال، نستخدم الديكوراتور @lru_cache لتخزين نتائج الدالة fibonacci مؤقتًا. هذا يعني أنه عند طلب نفس العدد مرة أخرى، سيتم استرجاع النتيجة من التخزين المؤقت بدلاً من إعادة حسابها، مما يحسن بشكل كبير من كفاءة الخدمة.
بهذه الطريقة، عندما يطلب Xiao Wang أو Xiao Ming العدد رقم 10000 في متسلسلة فيبوناتشي، سيتم الحصول على النتيجة بسرعة أكبر.
لاحظنا أنه إذا كانت قيمة n متشابهة، فإن قيمة f(n) ستكون دائمًا نفسها. قمنا بإجراء بعض التجارب.
127.0.0.1 - - [10/Mar/2021 00:33:01] "GET /?n=1000 HTTP/1.1" 200 -
----------------------------------------
حدث استثناء أثناء معالجة الطلب من ('127.0.0.1', 50783)
Traceback (آخر استدعاء أخير):
...
if v[n] != -1:
IndexError: فهرس القائمة خارج النطاق
إذا كانت المصفوفة غير كافية في الحجم، فلنغير مصفوفة v إلى 10000.
v = []
for x in range(10000):
v.append(-1)
تمت ترجمة الكود أعلاه إلى:
v = []
for x in range(10000):
v.append(-1)
في هذا الكود، يتم إنشاء قائمة فارغة v، ثم يتم إضافة القيمة -1 إلى القائمة 10000 مرة باستخدام حلقة for. النتيجة النهائية هي قائمة تحتوي على 10000 عنصر، كل عنصر منها هو -1.
ومع ذلك، عندما تكون n تساوي 2000، ظهر خطأ في تجاوز عمق الاستدعاء الذاتي (Recursion Depth Overflow):
127.0.0.1 - - [10/Mar/2021 00:34:00] "GET /?n=2000 HTTP/1.1" 200 -
----------------------------------------
حدث استثناء أثناء معالجة الطلب من ('127.0.0.1', 50821)
Traceback (آخر استدعاء أخير):
...
if v[n] != -1:
RecursionError: تم تجاوز الحد الأقصى لعمق الاستدعاء في المقارنة
ومع ذلك، كل هذا كان سريعًا إلى حد ما.
لماذا؟ لأن f(1) إلى f(1000)، كلها تحتاج إلى أن تُحسب مرة واحدة فقط. هذا يعني أنه عند حساب f(1000)، قد يتم تنفيذ عملية + حوالي 1000 مرة فقط. نعلم أن عمق التكرار في Python يبلغ حوالي 1000. وهذا يعني أنه يمكننا تحسين البرنامج بهذه الطريقة: إذا أردنا حساب 2000، فسنحسب أولاً 1000. لا، هذا قد يؤدي إلى حدوث خطأ تجاوز عمق التكرار. إذا أردنا حساب 2000، فلنحسب أولاً 1200. وإذا أردنا حساب 1200، فلنحسب أولاً 400.
بعد حساب 400 و1200 بهذه الطريقة، ثم حساب 2000، سيكون عمق الاستدعاء الذاتي حوالي 800، ولن يحدث خطأ في تجاوز عمق الاستدعاء الذاتي.
v = []
for x in range(1000000):
v.append(-1)
def fplus(n):
if n > 800:
fplus(n-800)
return f(n)
else:
return f(n)
def f(n):
if v[n] != -1:
return v[n]
else:
a = 0
if n < 2:
a = n
else:
a = f(n-1) + f(n-2)
v[n] = a
return v[n]
تمت إضافة دالة fplus.
ومع ذلك، لا يسع المرء إلا أن يتساءل، ماذا لو تم استدعاء الدالة fplus بشكل متكرر 1000 مرة؟ 1000 * 800 = 800000. عندما قمت بتعيين قيمة n إلى 800 ألف، ظهرت مرة أخرى مشكلة في عمق الاستدعاءات. بعد الاستمرار في التجربة، اكتشفت أن الأمور أكثر تعقيدًا. ومع ذلك، بعد هذه التحسينات، أصبح حساب 2000 أمرًا سهلًا للغاية.
قراءة وكتابة الملفات
يبدو أن الموضوع قد انحرف قليلاً. فلنعد إلى موضوع تطوير الويب. في الطلب الأول f(400)، وفي الطلب الثاني f(600). عند الطلب الثاني، يمكننا استخدام قيم مصفوفة v التي تم إنشاؤها في الطلب الأول. ومع ذلك، عندما نخرج من البرنامج ونعيد تشغيله، لن نتمكن من استخدامها. وفقًا لطريقتنا، حساب متسلسلة فيبوناتشي سريع جدًا. ولكن تخيل إذا كان بطيئًا. خاصة عندما لم نكن قد أدخلنا مصفوفة v، وكان هناك الكثير من الحسابات المتكررة. في هذه الحالة، نرغب في حفظ النتائج التي حصلنا عليها بصعوبة.
هنا يأتي دور مفهوم التخزين المؤقت (cache). المصفوفة v هنا تعتبر بمثابة تخزين مؤقت. ومع ذلك، فهي موجودة فقط خلال دورة حياة البرنامج. بمجرد إغلاق البرنامج، تختفي هذه البيانات. إذن، ما الحل؟ بطبيعة الحال، نفكر في تخزينها في ملف.
كيف يمكن حفظ مصفوفة v إلى ملف؟
0 0
1 1
2 1
3 2
4 3
...
يمكننا حفظ مصفوفة v بهذه الطريقة. يتم حفظ كل صف كـ n f(n). نظرًا لأن n يتزايد بشكل طبيعي، ربما يمكننا فقط حفظ قيم f(n).
0
1
1
2
3
...
جربها الآن.
f = open("demofile2.txt", "a")
f.write("Now the file has more content!")
f.close()
ترجمة الكود:
f = open("demofile2.txt", "a") # فتح الملف "demofile2.txt" في وضع الإلحاق (append)
f.write("Now the file has more content!") # إضافة النص "Now the file has more content!" إلى الملف
f.close() # إغلاق الملف
ملاحظة: الكود يفتح ملفًا نصيًا باسم demofile2.txt في وضع الإلحاق ("a")، مما يعني أنه سيتم إضافة النص الجديد إلى نهاية الملف دون حذف المحتوى الحالي. بعد ذلك، يتم إغلاق الملف.
# افتح واقرأ الملف بعد الإضافة:
f = open("demofile2.txt", "r")
print(f.read())
الوسيط الثاني للدالة open يمكن أن يكون a، مما يعني أنه سيتم إضافة المحتوى في نهاية الملف؛ أو w، مما يعني أنه سيتم استبدال محتوى الملف الحالي.
file = open('fib_v', 'a')
file.write('hi')
file.close()
بعد التشغيل، وجدت بالفعل ملفًا باسم fib_v.
`fib_v`
مرحبًا
عندما نقوم بتشغيله مرة أخرى، يصبح هكذا.
hihi
كيف يمكنني إدراج سطر جديد؟
file = open('fib_v', 'a')
file.write('hi\n')
file.close()
هذا سيتم طباعته مرة واحدة، وستظهر hihihi، ولم يتم ملاحظة أي سطر جديد. ومع ذلك، عند الطباعة مرة أخرى، يتم إدراج سطر جديد. وهذا يدل على أن السطر الجديد قد تم طباعته بالفعل في المرة الأولى، ولكنه كان في النهاية ولم يكن مرئيًا.
كيف يمكن القراءة؟
file = open('fib_v', 'r')
print(file.read())
ملاحظة: الكود أعلاه مكتوب بلغة Python ويقوم بفتح ملف باسم fib_v للقراءة ('r') ثم يطبع محتوى الملف. لا يوجد تغيير في الكود لأنه مكتوب بلغة برمجية عالمية ولا يحتاج إلى ترجمة.
$ python fib.py
hihihi
hi
بعد ذلك، دعونا نعدل برنامجنا لحساب متتالية فيبوناتشي.
v = []
for x in range(1000000):
v.append(-1)
def read():
file = open('fib_v', 'r')
s = file.read()
if len(s) > 0:
lines = s.split('\n')
if (len(lines) > 0):
for i in range(len(lines)):
v[i] = int(lines[i])
ترجمة الكود إلى العربية:
def read():
file = open('fib_v', 'r') # فتح الملف 'fib_v' للقراءة
s = file.read() # قراءة محتوى الملف
if len(s) > 0: # إذا كان المحتوى غير فارغ
lines = s.split('\n') # تقسيم المحتوى إلى أسطر
if (len(lines) > 0): # إذا كان هناك أسطر
for i in range(len(lines)): # التكرار عبر كل الأسطر
v[i] = int(lines[i]) # تحويل السطر إلى عدد صحيح وتخزينه في القائمة v
ملاحظة: الكود يفترض وجود قائمة v مُعرفة مسبقًا لتخزين القيم التي يتم قراءتها من الملف.
def save():
file = open('fib_v', 'w')
s = ''
start = True
for vv in v:
if vv == -1:
break
if start == False:
s += '\n'
start = False
s += str(vv)
file.write(s)
file.close()
def fcache(n):
x = fplus(n)
save()
return x
def fplus(n):
if n > 800:
fplus(n-800)
return f(n)
else:
return f(n)
def f(n):
if v[n] != -1:
return v[n]
else:
a = 0
if n < 2:
a = n
else:
a = f(n-1) + f(n-2)
v[n] = a
return v[n]
read()
fcache(10)
save()
أخيرًا، انتهينا من كتابة البرنامج. بعد تشغيل البرنامج، أصبح ملف fib_v على النحو التالي.
fib_v:
0
1
1
2
3
5
8
13
21
34
55
نرى أن التحليل أعلاه معقد بعض الشيء. \n هو رمز سطر جديد. هل هناك طريقة تحليل أبسط وأكثر توحيدًا؟ لقد ابتكر الناس تنسيق البيانات JSON.
JSON
الاسم الكامل لـ JSON هو JavaScript Object Notation. فيما يلي مثال على JSON.
{"name":"John", "age":31, "city":"New York"}
يمكن التعبير عن التعيين بهذه الطريقة.
تحتوي JSON على العناصر الأساسية التالية:
- الأرقام أو السلاسل النصية
- القوائم
- التعيينات (الخرائط)
ويمكن أيضًا تداخل هذه العناصر الأساسية بشكل تعسفي. أي يمكن أن تحتوي القائمة على قائمة أخرى. ويمكن أن تحتوي الخريطة على قائمة أيضًا. وهكذا.
{
"name":"John",
"age":30,
"cars":[ "Ford", "BMW", "Fiat" ]
}
写成一行,和这样写得好看点是意义上的差别的。或许我们可以想象它们的计算图。空格不会影响它们的计算图。
بعد ذلك، نحتاج إلى تحويل مصفوفة v إلى سلسلة نصية بتنسيق json.
import json
v = []
for x in range(1000000):
v.append(-1)
def fplus(n):
if n > 800:
fplus(n-800)
return f(n)
else:
return f(n)
def f(n):
if v[n] != -1:
return v[n]
else:
a = 0
if n < 2:
a = n
else:
a = f(n-1) + f(n-2)
v[n] = a
return v[n]
fplus(100)
s = json.dump(v)
file = open('fib_j', 'w')
file.write(s)
file.close()
عندما نكتب بهذه الطريقة، حدث خطأ: TypeError: dump() missing 1 required positional argument: 'fp'. في vscode، يمكننا رؤية تعريف الدالة بهذه الطريقة.
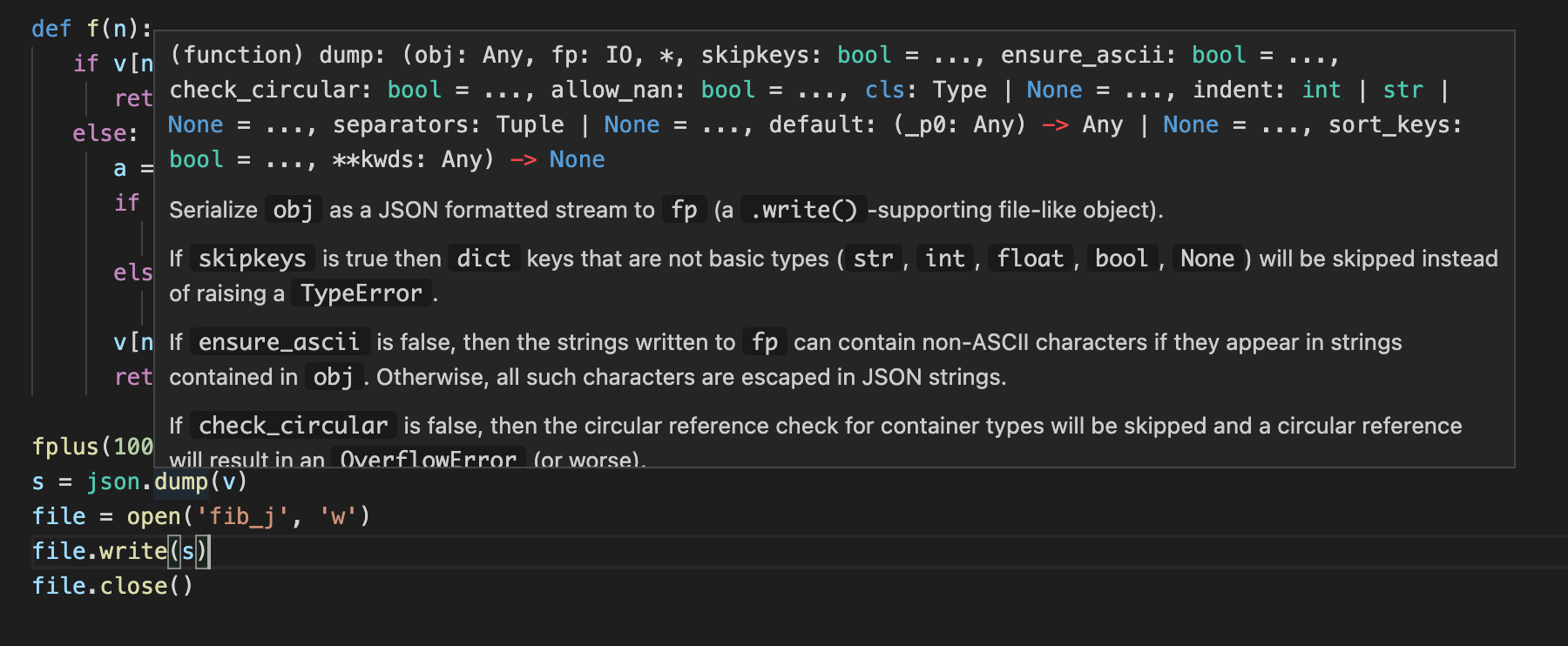
يمكنك تحريك الماوس فوق dump فقط. أليس ذلك مريحًا؟
fplus(10)
file = open('fib_j', 'w')
json.dump(v, file)
file.close()
لحساب الأرقام حتى 100، سيتم عرض عدد كبير من الأرقام، لذا سنقوم بتغييرها إلى 10. في الأصل، يمكن تمرير الكائن file كمعامل ثاني للدالة dump.
يمكنك رؤية الملفات بهذه الطريقة:
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, -1, -1, -1]
لاحظ أن هناك العديد من -1 تم حذفها لاحقًا.
def read():
file = open('fib_j', 'r')
s = file.read()
sv = json.loads(s)
for i in range(len(sv)):
if sv[i] != -1:
v[i] = sv[i]
def save():
file = open('fib_j', 'w')
json.dump(v, file)
file.close()
ترجمة:
def read():
file = open('fib_j', 'r')
s = file.read()
sv = json.loads(s)
for i in range(len(sv)):
if sv[i] != -1:
v[i] = sv[i]
def save():
file = open('fib_j', 'w')
json.dump(v, file)
file.close()
قراءة()
for vv in v:
if vv != -1:
print(vv)
عندما يحدث هذا، يمكننا أن نرى أن الطباعة تظهر:
0
1
1
2
3
5
8
13
21
34
55
دعونا نتحقق من هذه الدوال معًا:
def read():
file = open('fib_j', 'r')
s = file.read()
sv = json.loads(s)
for i in range(len(sv)):
v[i] = sv[i]
تمت ترجمة الكود إلى:
def read():
file = open('fib_j', 'r')
s = file.read()
sv = json.loads(s)
for i in range(len(sv)):
v[i] = sv[i]
ملاحظة: الكود يبقى كما هو لأنه مكتوب بلغة برمجة (Python) ولا يتم ترجمته.
def save():
sv = []
for i in range(len(v)):
if v[i] != -1:
sv.append(v[i])
else:
break
file = open('fib_j', 'w')
json.dump(sv, file)
file.close()
fplus(100)
save()
ثم انتقلت إلى ملف العرض، وبالفعل تم حفظ القيم الصحيحة، وبشكل مرتب.
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817, 39088169, 63245986, 102334155, 165580141, 267914296, 433494437, 701408733, 1134903170, 1836311903, 2971215073, 4807526976, 7778742049, 12586269025, 20365011074, 32951280099, 53316291173, 86267571272, 139583862445, 225851433717, 365435296162, 591286729879, 956722026041, 1548008755920, 2504730781961, 4052739537881, 6557470319842, 10610209857723, 17167680177565, 27777890035288, 44945570212853, 72723460248141, 117669030460994, 190392490709135, 308061521170129, 498454011879264, 806515533049393, 1304969544928657, 2111485077978050, 3416454622906707, 5527939700884757, 8944394323791464, 14472334024676221, 23416728348467685, 37889062373143906, 61305790721611591, 99194853094755497, 160500643816367088, 259695496911122585, 420196140727489673, 679891637638612258, 1100087778366101931, 1779979416004714189, 2880067194370816120, 4660046610375530309, 7540113804746346429, 12200160415121876738, 19740274219868223167, 31940434634990099905, 51680708854858323072, 83621143489848422977, 135301852344706746049, 218922995834555169026, 354224848179261915075]
قاعدة البيانات
إذا كانت البيانات كبيرة جدًا ومعقدة في الهيكل، ماذا نفعل؟ استخدام طريقة حفظ الملفات سيصبح بطيئًا ومعقدًا. هنا يأتي دور قواعد البيانات. وهي تعادل Excel قابل للبرمجة. يمكن بسهولة إضافة البيانات وحذفها وتعديلها والبحث فيها باستخدام الكود، مثل Excel.
في وثائق الموقع الرسمي وجدت مثالًا.
import sqlite3
con = sqlite3.connect('example.db')
cur = con.cursor()
إنشاء جدول
cur.execute(‘'’CREATE TABLE stocks (date text, trans text, symbol text, qty real, price real)’’’)
إدراج صف من البيانات
cur.execute(“INSERT INTO stocks VALUES (‘2006-01-05’,’BUY’,’RHAT’,100,35.14)”)
حفظ (إيداع) التغييرات
con.commit()
# يمكننا أيضًا إغلاق الاتصال إذا انتهينا منه.
# فقط تأكد من أن أي تغييرات قد تم حفظها (commit) وإلا سيتم فقدانها.
con.close()
for row in cur.execute('SELECT * FROM stocks ORDER BY price'):
print(row)
(ملاحظة: الكود المذكور أعلاه مكتوب بلغة Python ويقوم بطباعة الصفوف من جدول “stocks” مرتبة حسب السعر. لم يتم ترجمة الكود لأنه يحتوي على أوامر برمجية يجب أن تبقى كما هي.)
cursor تعني المؤشر، وهو يشبه المؤشر الذي تراه على الشاشة. ما سبق يوضح كيفية الاتصال بقاعدة البيانات، وإنشاء الجداول، وإدخال البيانات، وإرسال التغييرات، وإغلاق الاتصال. المثال الأخير يوضح كيفية استعلام البيانات.
import sqlite3
v = []
for x in range(1000000):
v.append(-1)
def create_table(cur: sqlite3.Connection):
cur.execute('CREATE TABLE vs(v text)')
تمت ترجمة الكود أعلاه إلى:
def create_table(cur: sqlite3.Connection):
cur.execute('CREATE TABLE vs(v text)')
في هذه الدالة، يتم إنشاء جدول جديد باسم vs يحتوي على عمود واحد من نوع النص (text).
def read():
pass
def save():
con = sqlite3.connect('fib.db')
cur = con.cursor()
create_table(cur)
for vv in v:
if vv != -1:
cur.execute('INSERT INTO vs VALUES(' + str(vv) + ')')
else:
break
con.commit()
con.close()
save()
سيتم ترجمة الكود أعلاه إلى:
save()
ملاحظة: الكود لم يتم ترجمته لأنه يحتوي على أوامر برمجية قد تكون خاصة بلغة برمجة معينة، والترجمة قد تؤدي إلى تغيير في وظيفة الكود.
تمت الكتابة. جربها الآن.
لدي بالفعل sqlite3 على جهاز الكمبيوتر الخاص بي.
$ sqlite3
SQLite version 3.32.3 2020-06-18 14:16:19
أدخل ".help" للحصول على تلميحات الاستخدام.
متصل بقاعدة بيانات مؤقتة في الذاكرة.
استخدم ".open FILENAME" لإعادة الفتح على قاعدة بيانات دائمة.
sqlite> .help
.auth ON|OFF عرض استدعاءات التفويض
.backup ?DB? FILE نسخ احتياطي للقاعدة DB (الافتراضية "main") إلى الملف FILE
.bail on|off التوقف بعد حدوث خطأ. الافتراضي OFF
.binary on|off تشغيل أو إيقاف الإخراج الثنائي. الافتراضي OFF
.cd DIRECTORY تغيير الدليل الحالي إلى DIRECTORY
.changes on|off عرض عدد الصفوف التي تم تغييرها بواسطة SQL
.check GLOB الفشل إذا كان الإخراج منذ .testcase لا يتطابق
.clone NEWDB نسخ البيانات إلى NEWDB من قاعدة البيانات الحالية
.databases عرض أسماء وملفات قواعد البيانات المرفقة
.dbconfig ?op? ?val? عرض أو تغيير خيارات sqlite3_db_config()
.dbinfo ?DB? عرض معلومات الحالة عن قاعدة البيانات
.dump ?TABLE? عرض محتوى قاعدة البيانات كـ SQL
.echo on|off تشغيل أو إيقاف صدى الأوامر
.eqp on|off|full|... تمكين أو تعطيل EXPLAIN QUERY PLAN التلقائي
.excel عرض إخراج الأمر التالي في جدول بيانات
.exit ?CODE? الخروج من البرنامج مع رمز العودة CODE
.expert تجريبي. اقتراح فهارس للاستعلامات
.explain ?on|off|auto? تغيير نمط تنسيق EXPLAIN. الافتراضي: auto
.filectrl CMD ... تشغيل عمليات sqlite3_file_control() المختلفة
.fullschema ?--indent? عرض المخطط ومحتوى جداول sqlite_stat
.headers on|off تشغيل أو إيقاف عرض العناوين
.help ?-all? ?PATTERN? عرض نص المساعدة لـ PATTERN
.import FILE TABLE استيراد البيانات من الملف FILE إلى الجدول TABLE
.imposter INDEX TABLE إنشاء جدول وهمي TABLE على الفهرس INDEX
.indexes ?TABLE? عرض أسماء الفهارس
.limit ?LIMIT? ?VAL? عرض أو تغيير قيمة SQLITE_LIMIT
.lint OPTIONS الإبلاغ عن مشاكل المخطط المحتملة
.log FILE|off تشغيل أو إيقاف التسجيل. يمكن أن يكون الملف stderr/stdout
.mode MODE ?TABLE? تعيين نمط الإخراج
.nullvalue STRING استخدام STRING بدلاً من القيم NULL
.once ?OPTIONS? ?FILE? إخراج الأمر SQL التالي فقط إلى الملف FILE
.open ?OPTIONS? ?FILE? إغلاق قاعدة البيانات الحالية وإعادة فتح الملف FILE
.output ?FILE? إرسال الإخراج إلى الملف FILE أو stdout إذا تم حذف FILE
.parameter CMD ... إدارة روابط معلمات SQL
.print STRING... طباعة STRING حرفيًا
.progress N استدعاء معالج التقدم بعد كل N من الأوامر
.prompt MAIN CONTINUE استبدال المطالبات القياسية
.quit الخروج من البرنامج
.read FILE قراءة الإدخال من الملف FILE
.recover استعادة أكبر قدر ممكن من البيانات من قاعدة بيانات تالفة
.restore ?DB? FILE استعادة محتوى DB (الافتراضية "main") من الملف FILE
.save FILE كتابة قاعدة البيانات في الذاكرة إلى الملف FILE
.scanstats on|off تشغيل أو إيقاف مقاييس sqlite3_stmt_scanstatus()
.schema ?PATTERN? عرض عبارات CREATE التي تطابق PATTERN
.selftest ?OPTIONS? تشغيل الاختبارات المحددة في جدول SELFTEST
.separator COL ?ROW? تغيير فواصل الأعمدة والصفوف
.session ?NAME? CMD ... إنشاء أو التحكم في الجلسات
.sha3sum ... حساب تجزئة SHA3 لمحتوى قاعدة البيانات
.shell CMD ARGS... تشغيل CMD ARGS... في shell النظام
.show عرض القيم الحالية للإعدادات المختلفة
.stats ?on|off? عرض الإحصائيات أو تشغيلها أو إيقافها
.system CMD ARGS... تشغيل CMD ARGS... في shell النظام
.tables ?TABLE? عرض أسماء الجداول التي تطابق النمط LIKE TABLE
.testcase NAME بدء إعادة توجيه الإخراج إلى 'testcase-out.txt'
.testctrl CMD ... تشغيل عمليات sqlite3_test_control() المختلفة
.timeout MS محاولة فتح الجداول المقفلة لمدة MS ميلي ثانية
.timer on|off تشغيل أو إيقاف مؤقت SQL
.trace ?OPTIONS? إخراج كل عبارة SQL أثناء تشغيلها
.vfsinfo ?AUX? معلومات عن VFS الرئيسي
.vfslist عرض جميع VFSes المتاحة
.vfsname ?AUX? طباعة اسم مكدس VFS
.width NUM1 NUM2 ... تعيين عرض الأعمدة لوضع "column"
يمكنك رؤية العديد من الأوامر. من بينها .quit الذي يعني الخروج.
إذا لم يكن لديك SQLite مثبتًا، يمكنك تنزيله من الموقع الرسمي، أو تشغيل الأمر brew install sqlite لتثبيته.
$ sqlite3 fib.db
sqlite> show tables
...> ;
خطأ: بالقرب من "show": خطأ في الصياغة
sqlite> tables;
خطأ: بالقرب من "tables": خطأ في الصياغة
sqlite> .schema
CREATE TABLE vs(v text);
في البداية اعتقدت أن الأمر يشبه MySQL. حيث يمكن استخدام show tables لمعرفة الجداول المتوفرة. لكن لاحقًا اكتشفت أن الأمر في SQLite مختلف. MySQL هو نوع آخر من قواعد البيانات، وهو أيضًا ما سنتعلمه في المستقبل.
sqlite> select * from vs;
0
1
1
2
3
5
8
13
21
34
55
بالفعل، قمنا بكتابة البيانات بشكل صحيح. لاحظ أننا استخدمنا text لأن أرقامنا كبيرة وقد لا يتمكن نوع الأعداد الصحيحة في قاعدة البيانات من حفظها.
import sqlite3
v = []
for x in range(1000000):
v.append(-1)
def fplus(n):
if n > 800:
fplus(n-800)
return f(n)
else:
return f(n)
def f(n):
if v[n] != -1:
return v[n]
else:
a = 0
if n < 2:
a = n
else:
a = f(n-1) + f(n-2)
v[n] = a
return v[n]
def create_table(cur: sqlite3.Connection):
cur.execute('CREATE TABLE vs(v text)')
def read():
con = sqlite3.connect('fib.db')
cur = con.cursor()
create_table(cur)
i = 0
for row in cur.execute('SELECT * from vs'):
v[i] = int(row)
con.close()
تمت ترجمة الكود إلى:
def read():
con = sqlite3.connect('fib.db')
cur = con.cursor()
create_table(cur)
i = 0
for row in cur.execute('SELECT * from vs'):
v[i] = int(row)
con.close()
ملاحظة: الكود الأصلي يحتوي على بعض الأخطاء المحتملة، مثل عدم تعريف المتغير v قبل استخدامه، وعدم زيادة قيمة i داخل الحلقة. هذه الأخطاء لم يتم تصحيحها في الترجمة.
def save():
con = sqlite3.connect('fib.db')
cur = con.cursor()
create_table(cur)
for vv in v:
if vv != -1:
cur.execute('INSERT INTO vs VALUES(' + str(vv) + ')')
else:
break
con.commit()
con.close()
read()
for i in range(10):
print(v[i])
نستمر بإضافة دالة read. ومع ذلك، بعد التشغيل، ظهر خطأ.
$ python fib_db.py
...
File "fib_db.py", line 27, in create_table
cur.execute('CREATE TABLE vs(v text)')
sqlite3.OperationalError: الجدول vs موجود بالفعل
لا يمكننا إنشاء الجدول مرة أخرى، الجدول موجود بالفعل. سنقوم بتعديل الصيغة قليلاً.
def create_table(cur: sqlite3.Connection):
cur.execute('CREATE TABLE IF NOT EXISTS vs(v text)')
الترجمة:
def create_table(cur: sqlite3.Connection):
cur.execute('CREATE TABLE IF NOT EXISTS vs(v text)')
ملاحظة: الكود المقدم لا يحتاج إلى ترجمة حيث أنه مكتوب بلغة برمجة Python، والترجمة هنا هي نفس الكود الأصلي.
ومع ذلك، حدث خطأ.
v[i] = int(row)
TypeError: يجب أن تكون وسيطة int() عبارة عن سلسلة نصية، أو كائن يشبه البايتات، أو رقمًا، وليس 'tuple'
tuple هو نوع من أنواع البيانات في Python. يعني أن الدالة row تُرجع tuple. دعنا نطبعها.
for row in cur.execute('SELECT * from vs'):
print(row)
v[i] = int(row)
النتيجة هي:
('0',)
في الواقع، tuple يشبه إلى حد كبير المصفوفة. الفرق الرئيسي هو أن عناصر tuple يمكن أن تكون مختلفة عن بعضها البعض، على عكس المصفوفة التي يجب أن تكون جميع عناصرها من نفس النوع.
def read():
con = sqlite3.connect('fib.db')
cur = con.cursor()
create_table(cur)
i = 0
for row in cur.execute('SELECT * from vs'):
v[i] = int(row[0])
con.close()
ملاحظة: الكود أعلاه مكتوب بلغة Python ويقوم بقراءة البيانات من قاعدة بيانات SQLite. لا يتم تغيير الكود أثناء الترجمة.
هذا التعديل. ومع ذلك، من الغريب أن يكون الناتج هكذا:
55
-1
-1
-1
-1
-1
-1
-1
-1
-1
اتضح أن المتغير i لم يتم زيادته.
for row in cur.execute('SELECT * from vs'):
v[i] = int(row[0])
i += 1
هذا صحيح.
0
1
1
2
3
5
8
13
21
34
ومع ذلك، لاحظنا أنه عندما تكون الأرقام كبيرة، يتم حفظها في قاعدة البيانات بهذا الشكل:
4660046610375530309
7540113804746346429
1.22001604151219e+19
1.97402742198682e+19
3.19404346349901e+19
عند إعادة التشغيل، ستكون النتيجة كالتالي.
$ python fib_db.py
Traceback (most recent call last):
File "fib_db.py", line 35, in read
v[i] = int(row[0])
ValueError: invalid literal for int() with base 10: '1.22001604151219e+19'
تمت ترجمة النص أعلاه إلى العربية كما يلي:
$ python fib_db.py
Traceback (most recent call last):
File "fib_db.py", line 35, in read
v[i] = int(row[0])
ValueError: قيمة غير صالحة لـ int() بالأساس 10: '1.22001604151219e+19'
غيّر أو عدّل
cur.execute("INSERT INTO vs VALUES('" +str(vv) + "')")
في الكود أعلاه، يتم إدراج قيمة المتغير vv في جدول يسمى vs باستخدام أمر SQL INSERT INTO. يتم تحويل قيمة vv إلى سلسلة نصية باستخدام الدالة str() قبل إدراجها في الاستعلام.
لاحظ أننا هنا قمنا بتغيير علامات الاقتباس الفردية حول عبارة INSERT إلى علامات اقتباس مزدوجة، وأضفنا أيضًا علامات اقتباس حول سلسلة الأرقام الخاصة بنا. إذا كنا قد كتبناها بهذه الطريقة من قبل، لكانت قاعدة البيانات قد تعاملت مع السلسلة على أنها أرقام، ولكن الآن، باستخدام علامات الاقتباس، يتم التعامل معها على أنها سلسلة نصية.
ثم أصبح صحيحًا. ومع ذلك، كيف يمكن مسح البيانات الخاطئة السابقة؟
$ sqlite3 fib.db
SQLite version 3.32.3 2020-06-18 14:16:19
أدخل ".help" للحصول على تلميحات الاستخدام.
sqlite> delete * from vs;
يمكنك تجربة عبارات أخرى بعد ذلك. إضافة، حذف، تعديل، استعلام. لقد قدمنا هنا أمثلة على الإضافة، الحذف، الاستعلام.
التمرين
- يجب على الطلاب استكشاف الأمور بشكل مشابه لما ورد أعلاه.