वेब प्रोग्रामिंग का परिचय | मूल, AI द्वारा अनुवादित
पिछले भाग में हमने Fibonacci sequence (फिबोनाची अनुक्रम) के कार्य को object-oriented (ऑब्जेक्ट-ओरिएंटेड) संस्करण में बदल दिया था और एक टर्मिनल इंटरफेस को लागू किया था।
server.py:
class BaseHandler:
def handle(self, request:str):
pass
class Server:
def __init__(self, handlerClass):
self.handlerClass = handlerClass
यह एक Python क्लास Server है जिसमें एक कंस्ट्रक्टर __init__ है। यह कंस्ट्रक्टर handlerClass नामक एक पैरामीटर लेता है और इसे क्लास के इंस्टेंस वेरिएबल self.handlerClass में स्टोर करता है।
def run(self):
while True:
request = input()
self.handlerClass().handle(request)
यह कोड एक अनंत लूप में चलता है, जहां यह उपयोगकर्ता से इनपुट लेता है और फिर handlerClass के handle मेथड को कॉल करता है। यह प्रक्रिया तब तक दोहराई जाती है जब तक प्रोग्राम को बंद नहीं किया जाता।
fib_handle.py:
from fib import f
from server import BaseHandler, Server
class FibHandler(BaseHandler):
def handle(self, request:str):
n = int(request)
print('f(n)=', f(n))
pass
server = Server(FibHandler)
server.run()
सरल वेब सर्वर
Web इंटरफ़ेस में कैसे बदलें?
हम ऊपर दिए गए Server को HTTP प्रोटोकॉल के Server से बदल देंगे। आइए पहले देखें कि Python में HTTP सर्वर कैसा दिखता है।
Python के मानक पुस्तकालय में एक वेब सर्वर प्रदान किया गया है।
python -m http.server
इसे टर्मिनल में चलाएं।
$ python -m http.server
HTTP को :: पोर्ट 8000 पर सर्व कर रहा है (http://[::]:8000/) ...
ब्राउज़र में खोलें और आप प्रभाव देख सकते हैं।
यह वर्तमान निर्देशिका को सूचीबद्ध करता है। फिर जब आप इस वेबपेज को ब्राउज़ करते हैं, तो टर्मिनल पर वापस जाएं। यह काफी दिलचस्प है।
$ python -m http.server
HTTP को :: पोर्ट 8000 पर सर्व कर रहा है (http://[::]:8000/) ...
::1 - - [07/Mar/2021 15:30:35] "GET / HTTP/1.1" 200 -
::1 - - [07/Mar/2021 15:30:35] कोड 404, संदेश फ़ाइल नहीं मिली
::1 - - [07/Mar/2021 15:30:35] "GET /favicon.ico HTTP/1.1" 404 -
::1 - - [07/Mar/2021 15:30:35] कोड 404, संदेश फ़ाइल नहीं मिली
::1 - - [07/Mar/2021 15:30:35] "GET /apple-touch-icon-precomposed.png HTTP/1.1" 404 -
::1 - - [07/Mar/2021 15:30:35] कोड 404, संदेश फ़ाइल नहीं मिली
::1 - - [07/Mar/2021 15:30:35] "GET /apple-touch-icon.png HTTP/1.1" 404 -
::1 - - [07/Mar/2021 15:30:38] "GET / HTTP/1.1" 200 -
यह वेब पेज एक्सेस लॉग है। इसमें GET वेब सर्विस के लिए एक प्रकार का डेटा एक्सेस ऑपरेशन को दर्शाता है। HTTP/1.1 यह दर्शाता है कि HTTP के 1.1 संस्करण का प्रोटोकॉल उपयोग किया गया है।
इसका उपयोग करके हम अपनी फिबोनाची अनुक्रम सेवा कैसे बना सकते हैं। पहले ऑनलाइन उदाहरण कोड ढूंढें, थोड़ा संशोधित करें, और एक सरलतम वेब सर्वर लिखें:
from http.server import SimpleHTTPRequestHandler, HTTPServer
class Handler(SimpleHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text')
self.end_headers()
self.wfile.write(bytes("hi", "utf-8"))
server = HTTPServer(("127.0.0.1", 8000), Handler)
server.serve_forever()
(यह कोड ब्लॉक है, इसे अनुवादित नहीं किया जाना चाहिए।)
क्या ये आपको परिचित लग रहे हैं? ये लगभग वैसे ही हैं जैसे हमने ऊपर `Server` का उपयोग किया था। ध्यान दें कि `SimpleHTTPRequestHandler` एक बेस क्लास नहीं है, बल्कि एक और क्लास है जिसे `BaseHTTPRequestHandler` कहा जाता है। `SimpleHTTPRequestHandler` कुछ अतिरिक्त कार्यों को संभालता है। इन सबके साथ फिबोनाची सीरीज को प्रोसेस करने की क्षमता जोड़ना आसान है।
यहां `127.0.0.1` लोकल मशीन का एड्रेस दर्शाता है, और `8000` लोकल मशीन का पोर्ट दर्शाता है। पोर्ट को कैसे समझें? यह ठीक वैसे ही है जैसे घर की एक खिड़की, जो घर और बाहरी दुनिया के बीच संचार का एक पोर्ट है। `bytes` स्ट्रिंग को बाइट्स में बदलने का काम करता है। `utf-8` एक प्रकार का स्ट्रिंग एन्कोडिंग तरीका है। `send_response`, `send_header`, और `end_headers` सभी कुछ कंटेंट आउटपुट करने के लिए हैं, जो `HTTP` प्रोटोकॉल द्वारा निर्धारित कंटेंट को आउटपुट करते हैं, ताकि इसे ब्राउज़र समझ सके। इस तरह हम वेबपेज में `hi` देख पाते हैं।
<img src="/assets/images/web/hi.png" alt="नमस्ते" style="zoom:50%;" />
अब, अनुरोध से पैरामीटर प्राप्त करने का प्रयास करते हैं।
```python
from http.server import SimpleHTTPRequestHandler, HTTPServer
from fib import f
from urllib.parse import urlparse, parse_qs
class Handler(SimpleHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text')
self.end_headers()
parsed = urlparse(self.path)
qs = parse_qs(parsed.query)
result = ""
if len(qs) > 0:
ns = qs[0]
if len(ns) > 0:
n = int(ns)
result = str(f(n))
self.wfile.write(bytes(result, "utf-8"))
यह कोड एक Handler क्लास को परिभाषित करता है जो SimpleHTTPRequestHandler से विरासत में मिलता है। यह क्लास HTTP GET अनुरोधों को संभालता है। जब कोई GET अनुरोध प्राप्त होता है, तो यह 200 स्थिति कोड भेजता है और ‘Content-type’ हेडर को ‘text’ के रूप में सेट करता है। फिर यह URL के क्वेरी स्ट्रिंग को पार्स करता है और यदि क्वेरी स्ट्रिंग में कोई मान होता है, तो उसे पूर्णांक में परिवर्तित करता है और एक फ़ंक्शन f को कॉल करता है। अंत में, यह परिणाम को क्लाइंट को वापस भेजता है।
server = HTTPServer(("127.0.0.1", 8000), Handler)
server.serve_forever()
(यह कोड ब्लॉक है, इसे अनुवादित नहीं किया जाना चाहिए।)
<img src="/assets/images/web/n10.png" alt="n10" style="zoom:50%;" />
यह थोड़ा जटिल है। यहां कुछ पैरामीटर्स को पार्स किया जा रहा है।
```shell
self.path=/?n=3
parsed=ParseResult(scheme='', netloc='', path='/', params='', query='n=3', fragment='')
qs={'n': ['3']}
ns=['3']
n=3
इस कोड में, self.path एक URL पथ को दर्शाता है जो /?n=3 है। parsed वेरिएबल ParseResult ऑब्जेक्ट को दर्शाता है जो URL के विभिन्न भागों को पार्स करता है। qs एक डिक्शनरी है जो क्वेरी स्ट्रिंग को दर्शाता है, जहां n की वैल्यू ['3'] है। ns एक लिस्ट है जो n की वैल्यू को दर्शाती है, और n वेरिएबल 3 को दर्शाता है।
रिकर्सन का उन्नत स्तर
आइए कोड को थोड़ा सा रिफैक्टर करें।
from http.server import SimpleHTTPRequestHandler, HTTPServer
from fib import f
from urllib.parse import urlparse, parse_qs
यह कोड Python में एक सरल HTTP सर्वर बनाने के लिए है। इसमें SimpleHTTPRequestHandler और HTTPServer क्लासेस का उपयोग किया गया है, जो Python के http.server मॉड्यूल से आते हैं। साथ ही, fib मॉड्यूल से f फ़ंक्शन को इम्पोर्ट किया गया है, और urllib.parse मॉड्यूल से urlparse और parse_qs फ़ंक्शन्स को इम्पोर्ट किया गया है।
class Handler(SimpleHTTPRequestHandler):
यह एक Python कोड स्निपेट है जो SimpleHTTPRequestHandler क्लास को इनहेरिट करके एक नई Handler क्लास बनाता है। इसे ट्रांसलेट करने की आवश्यकता नहीं है क्योंकि यह कोड है और कोड को ट्रांसलेट नहीं किया जाता है।
def parse_n(self, s):
parsed = urlparse(s)
qs = parse_qs(parsed.query)
if len(qs) > 0:
ns = qs['n']
if len(ns) > 0:
n = int(ns[0])
return n
return None
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text')
self.end_headers()
व्याख्या:
-
parse_nफ़ंक्शन एक URL स्ट्रिंगsको पार्स करता है और उसके क्वेरी पैरामीटर सेnका मान निकालता है। यदिnमौजूद है और वैध है, तो इसे पूर्णांक में परिवर्तित करके वापस करता है। अन्यथा,Noneवापस करता है। -
do_GETफ़ंक्शन एक HTTP GET अनुरोध को संसाधित करता है। यह 200 OK स्थिति कोड भेजता है औरContent-typeहेडर कोtextके रूप में सेट करता है, फिर हेडर को समाप्त करता है।
result = ""
n = self.parse_n(self.path)
if n is not None:
result = str(f(n))
self.wfile.write(bytes(result, "utf-8"))
self.wfile.write(bytes(result, "utf-8"))
इस कोड में:
resultएक खाली स्ट्रिंग के रूप में शुरू होता है।nकोself.pathसे पार्स करके प्राप्त किया जाता है।- यदि
nNoneनहीं है, तोresultकोf(n)के मान को स्ट्रिंग में बदलकर सेट किया जाता है। - अंत में,
resultको UTF-8 एन्कोडिंग में बाइट्स में बदलकरself.wfileमें दो बार लिखा जाता है।
server = HTTPServer((“127.0.0.1”, 8000), Handler)
server.serve_forever()
(यह कोड ब्लॉक है, इसे अनुवादित नहीं किया जाना चाहिए।)
`parse_n` फ़ंक्शन को पेश करके, अनुरोध पथ से प्राप्त `n` को एक ब्लॉक में समाहित करने के लिए।
अभी प्रोग्राम में यह समस्या है। Xiao Wang ने Fibonacci sequence के 10000वें पद का अनुरोध किया, कुछ दिनों बाद, Xiao Ming ने भी Fibonacci sequence के 10000वें पद का अनुरोध किया। दोनों बार, Xiao Wang और Xiao Ming को परिणाम प्राप्त करने के लिए आधे दिन तक इंतजार करना पड़ा। हम इस `Web सेवा` की दक्षता को कैसे बढ़ा सकते हैं?
ध्यान दें कि यदि `n` समान है, तो `f(n)` का मान हमेशा समान होता है। हमने कुछ प्रयोग किए।
```shell
127.0.0.1 - - [10/Mar/2021 00:33:01] "GET /?n=1000 HTTP/1.1" 200 -
----------------------------------------
अनुरोध के प्रसंस्करण के दौरान अपवाद हुआ ('127.0.0.1', 50783)
Traceback (सबसे हाल का अंतिम):
...
if v[n] != -1:
IndexError: सूची सूचकांक सीमा से बाहर
अगर मूल सरणी (array) पर्याप्त बड़ी नहीं है, तो v सरणी को 10000 तक बदल दें।
v = []
for x in range(10000):
v.append(-1)
यह कोड एक खाली सूची v बनाता है और फिर 0 से 9999 तक के सभी पूर्णांकों के लिए v में -1 जोड़ता है। इसका परिणाम एक सूची होगी जिसमें 10000 बार -1 होगा।
हालांकि, जब n का मान 2000 होता है, तो रिकर्सन की गहराई (recursion depth) से संबंधित एक त्रुटि (error) उत्पन्न होती है:
127.0.0.1 - - [10/Mar/2021 00:34:00] "GET /?n=2000 HTTP/1.1" 200 -
----------------------------------------
अनुरोध के प्रसंस्करण के दौरान अपवाद हुआ ('127.0.0.1', 50821)
Traceback (सबसे हालिया कॉल अंतिम):
...
if v[n] != -1:
RecursionError: तुलना में अधिकतम पुनरावृत्ति गहराई पार हो गई
हालांकि, यह सब काफी तेज़ी से हुआ।
क्यों। क्योंकि f(1) से f(1000) तक, हर एक को केवल एक बार ही गणना करने की आवश्यकता है। इसका मतलब है कि जब f(1000) की गणना की जा रही होती है, तो + ऑपरेशन शायद केवल 1000 बार ही किया जाता है। हम जानते हैं कि Python में रिकर्सन की गहराई लगभग 1000 होती है। इसका मतलब है कि हम प्रोग्राम को इस तरह से ऑप्टिमाइज़ कर सकते हैं, अगर हमें 2000 की गणना करनी है, तो पहले 1000 की गणना करें। नहीं, ऐसा करने पर भी रिकर्सन डेप्थ ओवरफ्लो एरर हो सकता है। अगर 2000 की गणना करनी है, तो पहले 1200 की गणना करें। अगर 1200 की गणना करनी है, तो पहले 400 की गणना करें।
400 और 1200 को इस तरह से गणना करने के बाद, 2000 की गणना करें, और रिकर्सन की गहराई लगभग 800 के आसपास होगी, जिससे रिकर्सन गहराई ओवरफ्लो त्रुटि नहीं होगी।
v = []
for x in range(1000000):
v.append(-1)
यह कोड एक खाली सूची v बनाता है और फिर एक लूप का उपयोग करके 0 से 999,999 तक के सभी नंबरों के लिए सूची में -1 जोड़ता है। इसका परिणाम एक सूची होगी जिसमें 1,000,000 बार -1 होगा।
def fplus(n):
if n > 800:
fplus(n-800)
return f(n)
else:
return f(n)
def f(n):
if v[n] != -1:
return v[n]
else:
a = 0
if n < 2:
a = n
else:
a = f(n-1) + f(n-2)
v[n] = a
return v[n]
fplus फ़ंक्शन को जोड़ा गया है।
हालांकि, यह सोचने पर मजबूर करता है कि अगर fplus को 1000 बार पुनरावर्ती रूप से कॉल किया जाए तो क्या होगा। 1000 * 800 = 800000। जब मैंने n को 800,000 पर सेट किया, तो फिर से पुनरावर्ती गहराई त्रुटि आ गई। थोड़ा और परीक्षण करने के बाद, पता चला कि मामला और भी जटिल है। हालांकि, इस ऑप्टिमाइज़ेशन के बाद, 2000 की गणना करना बहुत आसान हो गया है।
फ़ाइल पढ़ना और लिखना
लगता है कि विषय से भटक गया हूँ। वापस Web Development के विषय पर आते हैं। पहली बार f(400) का अनुरोध किया गया, दूसरी बार f(600) का। तो दूसरी बार अनुरोध करते समय, पहले अनुरोध से उत्पन्न v array के मानों का उपयोग कर सकते हैं। हालांकि, जब हम प्रोग्राम को बंद कर देते हैं और फिर से शुरू करते हैं, तो उन मानों का उपयोग नहीं कर सकते। हमारी विधि के अनुसार, Fibonacci sequence की गणना बहुत तेज है। हालांकि, कल्पना कीजिए कि अगर यह बहुत धीमी हो तो क्या होगा। खासकर जब हमने v array को शामिल नहीं किया होता है, तो बहुत सारी दोहराई जाने वाली गणनाएँ होती हैं। ऐसे में हम चाहते हैं कि जो मुश्किल से प्राप्त हुए परिणाम हैं, उन्हें सहेज लिया जाए।
इस समय, कैश की अवधारणा को पेश किया जाता है। v सरणी यहाँ एक कैश है। हालांकि, यह केवल प्रोग्राम के जीवनकाल में मौजूद होता है। प्रोग्राम बंद होने के बाद, यह गायब हो जाता है। तो क्या करें? स्वाभाविक रूप से, हम इसे फ़ाइल में सहेजने के बारे में सोचेंगे।
v ऐरे को फ़ाइल में कैसे सहेजें।
0 0
1 1
2 1
3 2
4 3
...
हमारा v ऐरे इस तरह से सहेजा जा सकता है। प्रत्येक पंक्ति को n f(n) के रूप में सहेजा जाता है। चूंकि n प्राकृतिक रूप से बढ़ता है, शायद हम केवल f(n) मानों को सहेज सकते हैं।
0
1
1
2
3
...
इसे आज़माएं।
f = open("demofile2.txt", "a")
f.write("अब फ़ाइल में और सामग्री है!")
f.close()
फ़ाइल को खोलें और उसे पढ़ें, जोड़ने के बाद:
f = open(“demofile2.txt”, “r”) print(f.read())
`open` का दूसरा पैरामीटर `a` हो सकता है, जो फ़ाइल के अंत में जोड़ने का संकेत देता है; या `w` हो सकता है, जो फ़ाइल को ओवरराइट करने का संकेत देता है।
```python
file = open('fib_v', 'a')
file.write('hi')
file.close()
(यह कोड हिंदी में अनुवाद नहीं किया जा सकता क्योंकि यह एक प्रोग्रामिंग कोड है जो पायथन भाषा में लिखा गया है।)
इसे चलाएं, और निश्चित रूप से fib_v नामक फ़ाइल मिल जाएगी।
fib_v:
hi
जब हम इसे फिर से चलाते हैं, तो यह इस तरह बदल जाता है।
hihi
कैसे नई लाइन शुरू करें।
file = open('fib_v', 'a')
file.write('hi\n')
file.close()
(यह कोड हिंदी में अनुवाद नहीं किया जा सकता क्योंकि यह एक प्रोग्रामिंग कोड है और इसमें उपयोग किए गए फ़ंक्शन और सिंटैक्स को बदला नहीं जा सकता।)
यह एक बार प्रिंट होगा, hihihi दिखाई देगा, लेकिन नई लाइन नहीं दिखाई देगी। हालांकि, दूसरी बार प्रिंट करने पर, नई लाइन दिखाई देगी। इससे पता चलता है कि पहली बार प्रिंट करते समय नई लाइन का कैरेक्टर प्रिंट हो चुका था, लेकिन वह अंत में होने के कारण दिखाई नहीं दिया।
कैसे पढ़ें।
file = open('fib_v', 'r')
print(file.read())
(यह कोड हिंदी में अनुवाद नहीं किया जा सकता क्योंकि यह एक प्रोग्रामिंग कोड है और इसमें उपयोग की गई भाषा और सिंटैक्स को बदलना संभव नहीं है।)
$ python fib.py
hihihi
hi
अगला कदम, हमारे फिबोनाची प्रोग्राम को संशोधित करें।
v = []
for x in range(1000000):
v.append(-1)
यह कोड एक खाली सूची v बनाता है और फिर एक लूप के माध्यम से 1,000,000 बार -1 को इस सूची में जोड़ता है। अंत में, v सूची में 1,000,000 -1 मान होंगे।
def read():
file = open('fib_v', 'r')
s = file.read()
if len(s) > 0:
lines = s.split('\n')
if (len(lines) > 0):
for i in range(len(lines)):
v[i] = int(lines[i])
यह कोड एक फ़ाइल fib_v को पढ़ता है और उसकी सामग्री को एक सूची v में संग्रहीत करता है। यहाँ v एक सूची है जिसे पहले से परिभाषित किया गया होना चाहिए। फ़ाइल की प्रत्येक पंक्ति को पढ़कर उसे पूर्णांक में परिवर्तित किया जाता है और v सूची में संग्रहीत किया जाता है।
def save():
file = open('fib_v', 'w')
s = ''
start = True
for vv in v:
if vv == -1:
break
if start == False:
s += '\n'
start = False
s += str(vv)
file.write(s)
file.close()
हिंदी अनुवाद:
def save():
file = open('fib_v', 'w')
s = ''
start = True
for vv in v:
if vv == -1:
break
if start == False:
s += '\n'
start = False
s += str(vv)
file.write(s)
file.close()
व्याख्या:
file = open('fib_v', 'w'): ‘fib_v’ नाम की एक फ़ाइल को लिखने के लिए खोलता है।s = '': एक खाली स्ट्रिंगsको इनिशियलाइज़ करता है।start = True: एक फ्लैगstartकोTrueपर सेट करता है।for vv in v:: लिस्टvके प्रत्येक एलिमेंटvvके लिए लूप चलाता है।if vv == -1:: यदिvvका मान-1है, तो लूप से बाहर निकल जाता है।if start == False:: यदिstartFalseहै, तोsमें एक नई लाइन जोड़ता है।start = False:startकोFalseपर सेट करता है।s += str(vv):vvको स्ट्रिंग में बदलकरsमें जोड़ता है।
file.write(s): स्ट्रिंगsको फ़ाइल में लिखता है।file.close(): फ़ाइल को बंद करता है।
def fcache(n):
x = fplus(n)
save()
return x
def fplus(n):
if n > 800:
fplus(n-800)
return f(n)
else:
return f(n)
def f(n):
if v[n] != -1:
return v[n]
else:
a = 0
if n < 2:
a = n
else:
a = f(n-1) + f(n-2)
v[n] = a
return v[n]
read() fcache(10) save()
अंत में हमने प्रोग्राम लिख लिया है। प्रोग्राम चलाने के बाद, `fib_v` फ़ाइल इस तरह दिखती है।
`fib_v`:
```shell
0
1
1
2
3
5
8
13
21
34
55
ऊपर दिए गए विश्लेषण को देखकर थोड़ा परेशानी हो सकती है। \n एक नई लाइन (newline) का प्रतीक है। क्या इसका और सरल और एकीकृत तरीके से विश्लेषण करने का कोई तरीका है? लोगों ने JSON नामक एक डेटा प्रारूप का आविष्कार किया है।
JSON
JSON (JavaScript Object Notation) एक हल्का डेटा इंटरचेंज फॉर्मेट है जो मानव-पठनीय और मशीन-पार्स करने योग्य होता है। यह JavaScript में ऑब्जेक्ट्स के सिंटैक्स पर आधारित है, लेकिन यह भाषा-स्वतंत्र है और कई प्रोग्रामिंग भाषाओं में इसका समर्थन किया जाता है।
JSON सिंटैक्स
JSON डेटा को key-value पेयर्स के रूप में संग्रहीत करता है। यहाँ एक सरल JSON उदाहरण है:
{
"name": "John Doe",
"age": 30,
"isStudent": false,
"courses": ["Math", "Science", "History"],
"address": {
"street": "123 Main St",
"city": "Anytown",
"state": "CA"
}
}
JSON के मुख्य तत्व
- ऑब्जेक्ट्स:
{}के अंदर key-value पेयर्स के रूप में संग्रहीत। - एरेज़:
[]के अंदर मानों की सूची। - मान: स्ट्रिंग्स, नंबर्स, ऑब्जेक्ट्स, एरेज़,
true,false, याnullहो सकते हैं।
JSON का उपयोग
JSON का उपयोग आमतौर पर वेब एप्लिकेशन्स में सर्वर और क्लाइंट के बीच डेटा ट्रांसफर करने के लिए किया जाता है। यह API रिस्पॉन्सेस और कॉन्फ़िगरेशन फाइल्स के लिए भी लोकप्रिय है।
JSON और XML
JSON अक्सर XML की तुलना में हल्का और पढ़ने में आसान होता है, जिसके कारण यह आधुनिक वेब डेवलपमेंट में अधिक प्रचलित हो गया है।
JSON एक शक्तिशाली और लचीला डेटा फॉर्मेट है जो आधुनिक सॉफ्टवेयर डेवलपमेंट में व्यापक रूप से उपयोग किया जाता है।
JSON का पूरा नाम JavaScript Object Notation है। नीचे JSON का एक उदाहरण दिया गया है।
{"name":"John", "age":31, "city":"New York"}
उपरोक्त तरीके से एक मैपिंग को दर्शाया जाता है।
JSON में निम्नलिखित मूल तत्व होते हैं:
- संख्या या स्ट्रिंग
- सूची
- मैपिंग
और ये मूल तत्व किसी भी तरह से नेस्टेड किए जा सकते हैं। यानी कि एक सूची में दूसरी सूची हो सकती है। एक मैपिंग में भी सूची हो सकती है। और इसी तरह।
{
"name":"John",
"age":30,
"cars":[ "Ford", "BMW", "Fiat" ]
}
एक पंक्ति में लिखने और इस तरह से सुंदर ढंग से लिखने के बीच अर्थपूर्ण अंतर हो सकता है। शायद हम उनके कम्प्यूटेशनल ग्राफ की कल्पना कर सकते हैं। स्पेस उनके कम्प्यूटेशनल ग्राफ को प्रभावित नहीं करेगा।
अगले चरण में हमें v ऐरे को json फॉर्मेट की स्ट्रिंग में बदलना होगा।
import json
v = [] for x in range(1000000): v.append(-1)
def fplus(n):
if n > 800:
fplus(n-800)
return f(n)
else:
return f(n)
def f(n):
if v[n] != -1:
return v[n]
else:
a = 0
if n < 2:
a = n
else:
a = f(n-1) + f(n-2)
v[n] = a
return v[n]
यह कोड एक फ़ंक्शन f(n) को परिभाषित करता है जो फिबोनैचि अनुक्रम की nवीं संख्या की गणना करता है। यह मेमोइज़ेशन (memoization) तकनीक का उपयोग करता है ताकि पहले से गणना किए गए मानों को स्टोर किया जा सके और उन्हें दोबारा गणना करने से बचा जा सके। v एक सूची है जो पहले से गणना किए गए मानों को स्टोर करती है, और -1 इंगित करता है कि उस स्थान का मान अभी तक गणना नहीं किया गया है।
fplus(100)
s = json.dump(v)
file = open('fib_j', 'w')
file.write(s)
file.close()
जब हम इस तरह लिखते हैं, तो एक त्रुटि आती है: TypeError: dump() missing 1 required positional argument: 'fp'। vscode में हम फ़ंक्शन की परिभाषा को इस तरह देख सकते हैं।
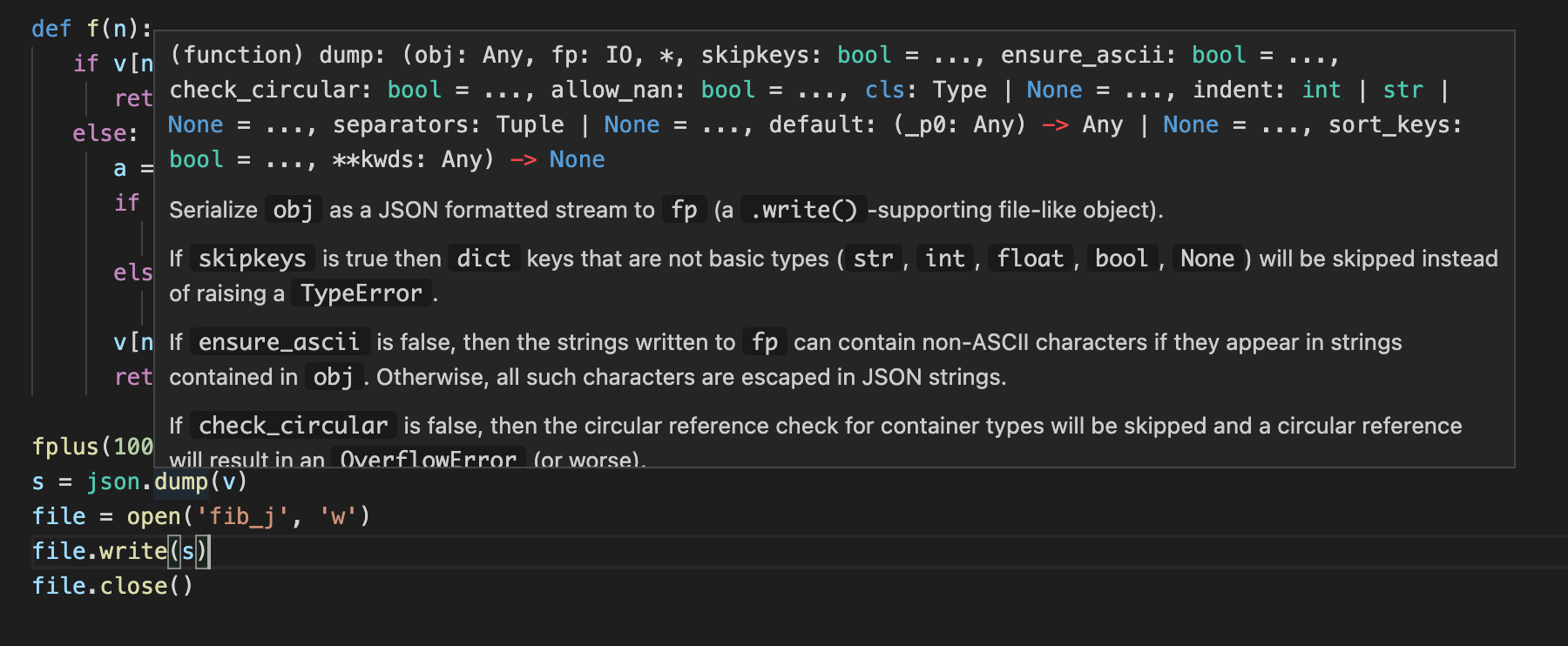
आप dump पर माउस ले जा सकते हैं। यह बहुत सुविधाजनक है, है ना?
fplus(10)
file = open('fib_j', 'w')
json.dump(v, file)
file.close()
(ध्यान दें: कोड ब्लॉक को अनुवादित नहीं किया जाता है क्योंकि यह प्रोग्रामिंग भाषा का हिस्सा है और इसे अपरिवर्तित रहना चाहिए।)
100 तक की गणना करने पर प्रदर्शित संख्याएँ थोड़ी अधिक हैं, इसलिए यहाँ इसे 10 कर दिया गया है। मूल रूप से, dump के दूसरे पैरामीटर में file ऑब्जेक्ट पास करना पर्याप्त है।
इससे आप फ़ाइल देख सकते हैं:
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, -1, -1, -1]
(नोट: कोड ब्लॉक्स को अनुवादित नहीं किया जाता है, इसलिए यह वही रहता है।)
ध्यान दें कि बाद में बहुत सारे -1 छोड़ दिए गए हैं।
def read():
file = open('fib_j', 'r')
s = file.read()
sv = json.loads(s)
for i in range(len(sv)):
if sv[i] != -1:
v[i] = sv[i]
def save():
file = open('fib_j', 'w')
json.dump(v, file)
file.close()
(नोट: कोड ब्लॉक को हिंदी में ट्रांसलेट नहीं किया गया है क्योंकि यह प्रोग्रामिंग कोड है और इसे अपरिवर्तित रखना उचित है।)
read()
for vv in v:
if vv != -1:
print(vv)
जब ऐसा होता है, तो प्रिंट आउट दिखाई देता है:
0
1
1
2
3
5
8
13
21
34
55
इन कुछ फ़ंक्शनों को एक साथ जाँचें:
def read():
file = open('fib_j', 'r')
s = file.read()
sv = json.loads(s)
for i in range(len(sv)):
v[i] = sv[i]
यह कोड एक फ़ाइल fib_j को पढ़ता है, उसकी सामग्री को JSON के रूप में पार्स करता है, और फिर उस डेटा को एक सूची v में स्टोर करता है।
def save():
sv = []
for i in range(len(v)):
if v[i] != -1:
sv.append(v[i])
else:
break
file = open('fib_j', 'w')
json.dump(sv, file)
file.close()
read() fplus(100) save()
फिर फ़ाइल को चेक करने पर, सही मान सहेजे गए थे और वे बहुत साफ-सुथरे थे।
```json
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817, 39088169, 63245986, 102334155, 165580141, 267914296, 433494437, 701408733, 1134903170, 1836311903, 2971215073, 4807526976, 7778742049, 12586269025, 20365011074, 32951280099, 53316291173, 86267571272, 139583862445, 225851433717, 365435296162, 591286729879, 956722026041, 1548008755920, 2504730781961, 4052739537881, 6557470319842, 10610209857723, 17167680177565, 27777890035288, 44945570212853, 72723460248141, 117669030460994, 190392490709135, 308061521170129, 498454011879264, 806515533049393, 1304969544928657, 2111485077978050, 3416454622906707, 5527939700884757, 8944394323791464, 14472334024676221, 23416728348467685, 37889062373143906, 61305790721611591, 99194853094755497, 160500643816367088, 259695496911122585, 420196140727489673, 679891637638612258, 1100087778366101931, 1779979416004714189, 2880067194370816120, 4660046610375530309, 7540113804746346429, 12200160415121876738, 19740274219868223167, 31940434634990099905, 51680708854858323072, 83621143489848422977, 135301852344706746049, 218922995834555169026, 354224848179261915075]
डेटाबेस
अगर डेटा बहुत बड़ा और संरचना बहुत जटिल है तो क्या करें? फ़ाइलों में सहेजने का तरीका धीमा और जटिल हो जाता है। यहीं पर डेटाबेस का परिचय होता है। यह एक प्रोग्रामेबल Excel शीट की तरह है। यह एक ऐसी Excel शीट है जिसमें कोड के माध्यम से आसानी से डेटा जोड़ा, हटाया, संशोधित और खोजा जा सकता है।
आधिकारिक वेबसाइट के दस्तावेज़ में उदाहरण मिला।
import sqlite3
con = sqlite3.connect('example.db')
(यह कोड ब्लॉक है, इसलिए इसे अनुवादित नहीं किया गया है।)
cur = con.cursor()
टेबल बनाएं
cur.execute(‘'’CREATE TABLE stocks (date text, trans text, symbol text, qty real, price real)’’’)
डेटा की एक पंक्ति डालें
cur.execute(“INSERT INTO stocks VALUES (‘2006-01-05’,’BUY’,’RHAT’,100,35.14)”)
परिवर्तनों को सहेजें (कमिट करें)
con.commit()
हम कनेक्शन को बंद भी कर सकते हैं अगर हम इसके साथ काम कर चुके हैं।
बस यह सुनिश्चित कर लें कि कोई भी परिवर्तन कमिट हो चुके हैं, नहीं तो वे खो जाएंगे।
con.close()
```python
for row in cur.execute('SELECT * FROM stocks ORDER BY price'):
print(row)
(यह कोड ब्लॉक को हिंदी में अनुवाद करने की आवश्यकता नहीं है क्योंकि यह प्रोग्रामिंग कोड है और इसे अपने मूल रूप में ही रहना चाहिए।)
cursor का मतलब होता है कर्सर, जो कि कर्सर की तरह ही होता है। ऊपर दिए गए कोड में डेटाबेस से कनेक्ट करना, टेबल बनाना, डेटा इन्सर्ट करना, परिवर्तनों को सबमिट करना, और कनेक्शन को बंद करने का मतलब है। अंत में दिया गया उदाहरण डेटा को क्वेरी करने का एक उदाहरण है।
import sqlite3
v = [] for x in range(1000000): v.append(-1)
def create_table(cur: sqlite3.Connection):
cur.execute('CREATE TABLE vs(v text)')
def read():
pass
def save():
con = sqlite3.connect('fib.db')
cur = con.cursor()
create_table(cur)
for vv in v:
if vv != -1:
cur.execute('INSERT INTO vs VALUES(' + str(vv) + ')')
else:
break
con.commit()
con.close()
हिंदी अनुवाद:
def save():
con = sqlite3.connect('fib.db')
cur = con.cursor()
create_table(cur)
for vv in v:
if vv != -1:
cur.execute('INSERT INTO vs VALUES(' + str(vv) + ')')
else:
break
con.commit()
con.close()
व्याख्या:
save()फ़ंक्शन एक SQLite डेटाबेसfib.dbसे कनेक्ट होता है।create_table(cur)फ़ंक्शन का उपयोग करके एक टेबल बनाई जाती है।vलिस्ट में मौजूद प्रत्येक मानvvके लिए, यदिvv-1 नहीं है, तो उसेvsटेबल में इन्सर्ट किया जाता है।- यदि
vv-1 है, तो लूप से बाहर निकल जाता है। - अंत में, डेटाबेस में परिवर्तनों को सुरक्षित करने के लिए
con.commit()किया जाता है और कनेक्शन को बंद कर दिया जाता है।
fplus(10) save()
लिख दिया है। आज़माओ देखो।
मेरे कंप्यूटर पर पहले से ही `sqlite3` इंस्टॉल है।
```shell
$ sqlite3
SQLite version 3.32.3 2020-06-18 14:16:19
".help" का उपयोग करने के लिए प्रवेश करें।
एक अस्थायी इन-मेमोरी डेटाबेस से जुड़ा हुआ है।
स्थायी डेटाबेस पर पुनः खोलने के लिए ".open FILENAME" का उपयोग करें।
sqlite> .help
.auth ON|OFF लेखक कॉलबैक दिखाएं
.backup ?DB? FILE DB (डिफ़ॉल्ट "main") का FILE में बैकअप लें
.bail on|off त्रुटि होने पर रुकें। डिफ़ॉल्ट OFF
.binary on|off बाइनरी आउटपुट चालू या बंद करें। डिफ़ॉल्ट OFF
.cd DIRECTORY कार्यशील निर्देशिका को DIRECTORY में बदलें
.changes on|off SQL द्वारा बदली गई पंक्तियों की संख्या दिखाएं
.check GLOB यदि .testcase के बाद का आउटपुट मेल नहीं खाता है तो विफल करें
.clone NEWDB मौजूदा डेटाबेस से NEWDB में डेटा क्लोन करें
.databases संलग्न डेटाबेस के नाम और फाइलें सूचीबद्ध करें
.dbconfig ?op? ?val? sqlite3_db_config() विकल्पों को सूचीबद्ध या बदलें
.dbinfo ?DB? डेटाबेस के बारे में स्थिति जानकारी दिखाएं
.dump ?TABLE? डेटाबेस सामग्री को SQL के रूप में प्रस्तुत करें
.echo on|off कमांड इको चालू या बंद करें
.eqp on|off|full|... स्वचालित EXPLAIN QUERY PLAN चालू या बंद करें
.excel अगले कमांड का आउटपुट स्प्रेडशीट में प्रदर्शित करें
.exit ?CODE? इस प्रोग्राम से रिटर्न-कोड CODE के साथ बाहर निकलें
.expert प्रायोगिक। क्वेरीज़ के लिए इंडेक्स सुझाएं
.explain ?on|off|auto? EXPLAIN फॉर्मेटिंग मोड बदलें। डिफ़ॉल्ट: auto
.filectrl CMD ... विभिन्न sqlite3_file_control() ऑपरेशन चलाएं
.fullschema ?--indent? स्कीमा और sqlite_stat टेबल्स की सामग्री दिखाएं
.headers on|off हेडर प्रदर्शन चालू या बंद करें
.help ?-all? ?PATTERN? PATTERN के लिए सहायता पाठ दिखाएं
.import FILE TABLE FILE से डेटा को TABLE में आयात करें
.imposter INDEX TABLE इंडेक्स INDEX पर इम्पोस्टर टेबल TABLE बनाएं
.indexes ?TABLE? इंडेक्स के नाम दिखाएं
.limit ?LIMIT? ?VAL? SQLITE_LIMIT का मान प्रदर्शित या बदलें
.lint OPTIONS संभावित स्कीमा समस्याओं की रिपोर्ट करें।
.log FILE|off लॉगिंग चालू या बंद करें। FILE stderr/stdout हो सकता है
.mode MODE ?TABLE? आउटपुट मोड सेट करें
.nullvalue STRING NULL मानों के स्थान पर STRING का उपयोग करें
.once ?OPTIONS? ?FILE? अगले SQL कमांड का आउटपुट केवल FILE में भेजें
.open ?OPTIONS? ?FILE? मौजूदा डेटाबेस बंद करें और FILE को फिर से खोलें
.output ?FILE? आउटपुट को FILE या stdout पर भेजें यदि FILE छोड़ दिया गया है
.parameter CMD ... SQL पैरामीटर बाइंडिंग प्रबंधित करें
.print STRING... शाब्दिक STRING प्रिंट करें
.progress N हर N ऑपकोड के बाद प्रगति हैंडलर को कॉल करें
.prompt MAIN CONTINUE मानक प्रॉम्प्ट को बदलें
.quit इस प्रोग्राम से बाहर निकलें
.read FILE FILE से इनपुट पढ़ें
.recover भ्रष्ट डेटाबेस से जितना संभव हो उतना डेटा पुनर्प्राप्त करें
.restore ?DB? FILE DB (डिफ़ॉल्ट "main") की सामग्री को FILE से पुनर्स्थापित करें
.save FILE मेमोरी में डेटाबेस को FILE में लिखें
.scanstats on|off sqlite3_stmt_scanstatus() मेट्रिक्स चालू या बंद करें
.schema ?PATTERN? PATTERN से मेल खाने वाले CREATE स्टेटमेंट दिखाएं
.selftest ?OPTIONS? SELFTEST टेबल में परिभाषित टेस्ट चलाएं
.separator COL ?ROW? कॉलम और पंक्ति विभाजक बदलें
.session ?NAME? CMD ... सत्र बनाएं या नियंत्रित करें
.sha3sum ... डेटाबेस सामग्री का SHA3 हैश गणना करें
.shell CMD ARGS... सिस्टम शेल में CMD ARGS... चलाएं
.show विभिन्न सेटिंग्स के लिए वर्तमान मान दिखाएं
.stats ?on|off? स्टैट्स दिखाएं या स्टैट्स चालू या बंद करें
.system CMD ARGS... सिस्टम शेल में CMD ARGS... चलाएं
.tables ?TABLE? LIKE पैटर्न TABLE से मेल खाने वाली टेबल्स के नाम सूचीबद्ध करें
.testcase NAME आउटपुट को 'testcase-out.txt' पर रीडायरेक्ट करना शुरू करें
.testctrl CMD ... विभिन्न sqlite3_test_control() ऑपरेशन चलाएं
.timeout MS लॉक की गई टेबल्स को MS मिलीसेकंड के लिए खोलने का प्रयास करें
.timer on|off SQL टाइमर चालू या बंद करें
.trace ?OPTIONS? प्रत्येक SQL स्टेटमेंट को चलाते समय आउटपुट करें
.vfsinfo ?AUX? शीर्ष-स्तरीय VFS के बारे में जानकारी
.vfslist सभी उपलब्ध VFSes की सूची दिखाएं
.vfsname ?AUX? VFS स्टैक का नाम प्रिंट करें
.width NUM1 NUM2 ... "कॉलम" मोड के लिए कॉलम की चौड़ाई सेट करें
आप देख सकते हैं कि यहाँ बहुत सारे कमांड हैं। इनमें से .quit का मतलब है बाहर निकलना।
यदि आपके पास SQLite नहीं है, तो आप इसे आधिकारिक वेबसाइट से डाउनलोड कर सकते हैं, या brew install sqlite चलाकर इंस्टॉल कर सकते हैं।
$ sqlite3 fib.db
sqlite> show tables
...> ;
त्रुटि: "show" के पास: सिंटैक्स त्रुटि
sqlite> tables;
त्रुटि: "tables" के पास: सिंटैक्स त्रुटि
sqlite> .schema
CREATE TABLE vs(v text);
शुरुआत में मैंने सोचा कि यह MySQL की तरह होगा। show tables का उपयोग करके देख सकते हैं कि कौन-कौन से टेबल हैं। बाद में पता चला कि SQLite में यह अलग तरह से काम करता है। MySQL एक अलग प्रकार का डेटाबेस है, जिसे हम भविष्य में सीखेंगे।
sqlite> select * from vs;
0
1
1
2
3
5
8
13
21
34
55
सही है, हमने डेटा को सही ढंग से लिखा है। ध्यान दें कि हमने text का उपयोग किया है, क्योंकि हमारे पास बड़ी संख्याएं हैं और डेटाबेस के पूर्णांक प्रकार इसे संभाल नहीं सकते।
import sqlite3
v = []
for x in range(1000000):
v.append(-1)
def fplus(n):
if n > 800:
fplus(n-800)
return f(n)
else:
return f(n)
यह कोड एक पुनरावर्ती (recursive) फ़ंक्शन fplus को परिभाषित करता है। यदि n का मान 800 से अधिक है, तो यह फ़ंक्शन fplus(n-800) को कॉल करता है और फिर f(n) को वापस लौटाता है। अन्यथा, यह सीधे f(n) को वापस लौटाता है।
def f(n):
if v[n] != -1:
return v[n]
else:
a = 0
if n < 2:
a = n
else:
a = f(n-1) + f(n-2)
v[n] = a
return v[n]
यह कोड एक फ़ंक्शन f(n) को परिभाषित करता है जो फाइबोनैचि अनुक्रम की nवीं संख्या की गणना करता है। यहां v एक सूची है जिसका उपयोग पहले से गणना की गई संख्याओं को संग्रहीत करने के लिए किया जाता है। यदि v[n] का मान -1 नहीं है, तो यह पहले से ही गणना की गई संख्या को वापस कर देता है। अन्यथा, यह फाइबोनैचि अनुक्रम की गणना करता है और उसे v[n] में संग्रहीत करता है।
def create_table(cur: sqlite3.Connection):
cur.execute('CREATE TABLE vs(v text)')
def read():
con = sqlite3.connect('fib.db')
cur = con.cursor()
create_table(cur)
i = 0
for row in cur.execute('SELECT * from vs'):
v[i] = int(row)
con.close()
def save():
con = sqlite3.connect('fib.db')
cur = con.cursor()
create_table(cur)
for vv in v:
if vv != -1:
cur.execute('INSERT INTO vs VALUES(' + str(vv) + ')')
else:
break
con.commit()
con.close()
read()
for i in range(10):
print(v[i])
हमने read फ़ंक्शन को जोड़ना जारी रखा। हालांकि, इसे चलाने के बाद, एक त्रुटि उत्पन्न हुई।
$ python fib_db.py
...
File "fib_db.py", line 27, in create_table
cur.execute('CREATE TABLE vs(v text)')
sqlite3.OperationalError: टेबल vs पहले से मौजूद है
हम अब टेबल नहीं बना सकते, टेबल पहले से मौजूद है। सिंटैक्स को थोड़ा बदल दें।
def create_table(cur: sqlite3.Connection):
cur.execute('CREATE TABLE IF NOT EXISTS vs(v text)')
(यह कोड ब्लॉक को हिंदी में अनुवाद करने की आवश्यकता नहीं है क्योंकि यह प्रोग्रामिंग कोड है और इसे अपने मूल रूप में ही रखना चाहिए।)
हालांकि, एक त्रुटि उत्पन्न हुई।
v[i] = int(row)
TypeError: int() का तर्क एक स्ट्रिंग, बाइट्स-जैसी वस्तु या संख्या होनी चाहिए, 'tuple' नहीं
tuple क्या है। इसका मतलब है कि row ने tuple वापस किया है। आइए इसे प्रिंट करके देखें।
for row in cur.execute('SELECT * from vs'):
print(row)
v[i] = int(row)
(यह कोड ब्लॉक को हिंदी में अनुवाद करने की आवश्यकता नहीं है क्योंकि यह प्रोग्रामिंग कोड है और इसे अपरिवर्तित छोड़ दिया जाना चाहिए।)
परिणाम:
('0',)
वास्तव में, tuple और array लगभग समान होते हैं। हालांकि, इसके elements एक दूसरे से अलग हो सकते हैं, जबकि array के सभी elements एक ही प्रकार के होने चाहिए।
def read():
con = sqlite3.connect('fib.db')
cur = con.cursor()
create_table(cur)
i = 0
for row in cur.execute('SELECT * from vs'):
v[i] = int(row[0])
con.close()
(यह कोड पायथन में लिखा गया है और इसे हिंदी में अनुवाद करने की आवश्यकता नहीं है, क्योंकि यह एक प्रोग्रामिंग कोड है और इसे उसी रूप में रखना चाहिए।)
इसे इस तरह बदलें। हालांकि, यह बहुत अजीब है। आउटपुट इस प्रकार है:
55
-1
-1
-1
-1
-1
-1
-1
-1
-1
हमारा i अपने आप नहीं बढ़ रहा था।
for row in cur.execute('SELECT * from vs'):
v[i] = int(row[0])
i += 1
(यह कोड ब्लॉक को हिंदी में अनुवाद करने की आवश्यकता नहीं है क्योंकि यह प्रोग्रामिंग कोड है और इसे अपरिवर्तित छोड़ दिया जाना चाहिए।)
यह सही है।
0
1
1
2
3
5
8
13
21
34
हालांकि, हमने देखा कि जब संख्याएँ बहुत बड़ी होती हैं, तो डेटाबेस में उन्हें इस तरह से सहेजा जाता है:
4660046610375530309
7540113804746346429
1.22001604151219e+19
1.97402742198682e+19
3.19404346349901e+19
फिर से चलाने पर यह ऐसा दिखता है।
$ python fib_db.py
Traceback (most recent call last):
File "fib_db.py", line 35, in read
v[i] = int(row[0])
ValueError: base 10 के लिए अमान्य लिटरल: '1.22001604151219e+19'
बदल दो:
cur.execute("INSERT INTO vs VALUES('" +str(vv) + "')")
(यह कोड ब्लॉक को हिंदी में अनुवाद करने की आवश्यकता नहीं है क्योंकि यह एक प्रोग्रामिंग कोड है और इसे अपरिवर्तित रखा जाना चाहिए।)
यहाँ हमने देखा कि हमने INSERT स्टेटमेंट के दोनों तरफ के सिंगल कोट्स को डबल कोट्स में बदल दिया है, और साथ ही हमारे नंबर स्ट्रिंग को कोट्स में लपेट दिया है। अगर पहले ऐसा लिखा जाता, तो डेटाबेस हमारे स्ट्रिंग को नंबर के रूप में समझता, लेकिन अब, इसे कोट्स में लपेटने से यह स्ट्रिंग के रूप में माना जाएगा।
फिर सब कुछ सही हो जाएगा। हालांकि, पहले की गलत डेटा को कैसे साफ़ किया जाए।
$ sqlite3 fib.db
SQLite version 3.32.3 2020-06-18 14:16:19
प्रयोग के लिए ".help" दर्ज करें।
sqlite> delete * from vs;
अगले चरण में अन्य कथनों को आज़मा सकते हैं। जोड़ना, हटाना, संशोधित करना, खोजना। हमने यहां जोड़ना, हटाना, खोजना के उदाहरण दिए हैं।
अभ्यास
- छात्रों को ऊपर दिए गए तरीके से इसी तरह की खोज करनी चाहिए।