الزن وفن تعلم الآلة | أصلي، ترجم بواسطة AI
زِن
أب شاب مشغول بتعلم الشبكات العصبية في عطلة نهاية الأسبوع. ومع ذلك، في هذا الأسبوع، كان عليه مرافقة طفلته الصغيرة للسباحة في بركة المجمع السكني. استلقى في المياه الضحلة وراقب المباني الشاهقة ترتفع نحو السماء. وفجأة خطرت له فكرة: “واو، إنها تشبه إلى حد كبير الشبكات العصبية. كل شرفة تشبه خلية عصبية. والمبنى يشبه طبقة من الخلايا العصبية. ومجموعة من المباني مجتمعة تشكل شبكة عصبية.”
ثم فكر في الانتشار العكسي (backpropagation). ما يفعله الانتشار العكسي هو نشر الأخطاء إلى الخلايا العصبية. في نهاية عملية التدريب لمرة واحدة، تحسب الخوارزمية الخطأ بين مخرجات الطبقة الأخيرة والنتيجة المستهدفة. في الواقع، لا علاقة للشبكات العصبية بالخلايا العصبية. الأمر يتعلق بالحوسبة القابلة للتفاضل.
بعد كتابة المقال “أخيرًا فهمت كيف تعمل الشبكة العصبية”، وجد أنه ما زال لا يفهم. الفهم شيء نسبي. كما يشير ريتشارد فاينمان إلى شيء مثل أنه لا يمكن لأحد أن يكون متأكدًا بنسبة 100% من أي شيء، يمكننا فقط أن نكون متأكدين نسبيًا من شيء ما. لذا فمن المقبول أن يقول تشيوي ذلك.
لذلك وجد طريقة لفهم الشبكات العصبية بعمق من خلال نسخ عدة أسطر من التعليمات البرمجية النموذجية في كل مرة، ثم تشغيلها وطباعة المتغيرات. يتعلق الأمر بشبكة عصبية بسيطة للتعرف على الأرقام المكتوبة بخط اليد. الكتاب الذي يقرأه مؤخرًا بعنوان الشبكات العصبية والتعلم العميق. لذلك أطلق على مستودعه على GitHub اسم الشبكات العصبية وتعلم Zhiwei.
قبل أن نستخدم الشبكة العصبية لتدريب بياناتنا، نحتاج أولاً إلى تحميل البيانات. لقد استغرق هذا الجزء منه أسبوعًا من وقت الفراغ لإنجازه. دائمًا ما تتطلب الأشياء وقتًا أكثر لإنجازها. ولكن طالما أننا لا نستسلم، فإننا قادرون على إنجاز الكثير من الأشياء.
في مجال تعلم الآلة، يشير مصطلح mnist إلى قاعدة البيانات المعدلة من المعهد الوطني للمعايير والتقنية (Modified National Institute of Standards and Technology database). لذلك، فإن ملف تحميل البيانات لدينا يُسمى mnist_loader. نستخدم دالة الطباعة print في لغة Python لطباعة العديد من القوائم والمصفوفات من نوع ndarray. الحروف nd في ndarray تعني n-dimensional، أي متعدد الأبعاد.
بالإضافة إلى الطباعة، يجب علينا استخدام مكتبة matplotlib لإظهار أرقامنا. كما هو موضح أدناه.
الفن
لنرى المزيد من الأرقام.

من الممتع أكثر عندما تتمكن أحيانًا من رؤية الصور بدلًا من مواجهة الأكواد الصاخبة طوال اليوم.
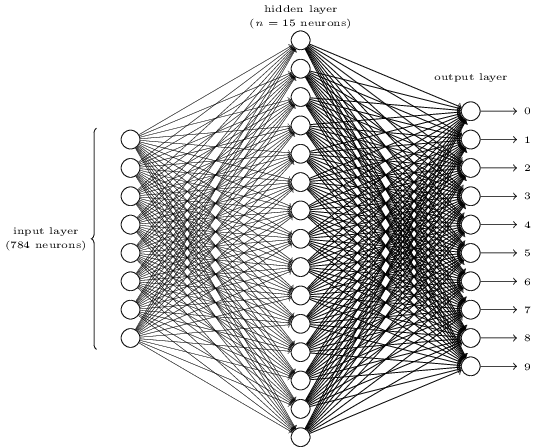
هل يبدو الأمر معقدًا؟ هنا، قد يكون لدينا الكثير من الخلايا العصبية في كل طبقة. وهذا يجعل الأمور غير واضحة. في الواقع، الأمر بسيط جدًا بمجرد فهمه. أول شيء حول الصورة أعلاه هو أنها تحتوي على ثلاث طبقات: طبقة الإدخال، الطبقة المخفية، وطبقة الإخراج. وكل طبقة تتصل بالطبقة التالية. ولكن كيف يمكن لـ 784 خلية عصبية في طبقة الإدخال أن تتحول إلى 15 خلية عصبية في الطبقة الثانية؟ وكيف يمكن لـ 15 خلية عصبية في الطبقة المخفية أن تتحول إلى 10 خلايا عصبية في طبقة الإخراج؟
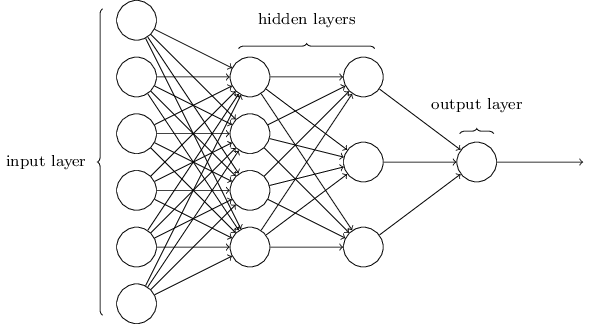
</div>
هذه الشبكة أبسط بكثير. على الرغم من أن Zhiwei لا يرغب في تضمين أي صيغة رياضية في هذه المقالة، إلا أن الرياضيات هنا بسيطة وجميلة جدًا بحيث لا يمكن إخفاؤها.
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\]لنفترض أننا نشير إلى الشبكة كما يلي.
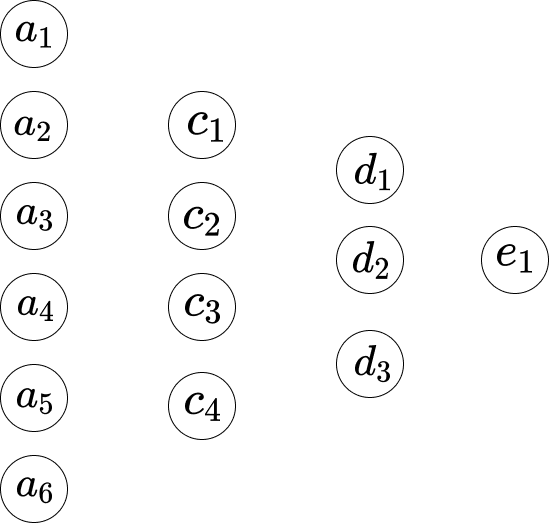
إذن بين الطبقة الأولى والطبقة الثانية، لدينا المعادلات التالية.
\[\begin{eqnarray} w_1*a_1 +...+ w_6*a_6+b_1 = c_1 \\ w_1*a_1 +...+ w_6*a_6+b_2 = c_2 \\ w_1*a_1 +...+ w_6*a_6+b_3 = c_3 \\ w_1*a_1 +...+ w_6*a_6+b_4 = c_4 \end{eqnarray}\]هنا، المعادلة 1 تحتوي على مجموعة من الأوزان، والمعادلة 2 تحتوي على مجموعة أخرى من الأوزان. لذا فإن $w_1$ في المعادلة 1 تختلف عن $w_1$ في المعادلة 2. وبالتالي، بين الطبقة الثانية والطبقة الثالثة، لدينا المعادلات التالية.
\[\begin{eqnarray} w_1*c_1 + ... + w_4*c_4+b_1 = d_1 \\ w_1*c_1 + ... + w_4*c_4+b_2 = d_2 \\ w_1*c_1 + ... + w_4*c_4+b_3 = d_3 \end{eqnarray}\]وفي الطبقة الثالثة إلى الطبقة الأخيرة، لدينا المعادلات التالية.
\[w_1 \cdot d_1 + w_2 \cdot d_2 + w_3 \cdot d_3 + b_1 = e_1\]المشكلة الوحيدة في المعادلات أعلاه هي أن القيمة ليست بسيطة أو رسمية بما يكفي. نطاق قيمة الضرب والجمع كبير جدًا. نريد أن يكون محصورًا في نطاق صغير، مثلًا من 0 إلى 1. لذا هنا لدينا دالة Sigmoid.
\[\sigma(z) \equiv \frac{1}{1+e^{-z}}\]لا نحتاج إلى أن نشعر بالرهبة من رمز السيجما $\sigma$. إنه مجرد رمز مثل الرمز a. إذا قدمنا له القيمة المدخلة 0.5، فإن قيمته تكون…
\[\frac{1}{1+e^{-0.5}} \approx 0.622459\]و،
\[\begin{eqnarray} \frac{1}{1+e^{-(-100)}} \approx 3.72*e^{-44} \\ \frac{1}{1+e^{-(-10)}} \approx 0.000045 \\ \frac{1}{1+e^{-(-1)}} \approx 0.26894 \\ \frac{1}{1+e^{-{0}}} = 0.5 \\ \frac{1}{1+e^{-10}} \approx 0.99995 \\ \frac{1}{1+e^{-100}} = 1 \end{eqnarray}\]من المثير للاهتمام هنا أنني لم أكن أعرف ما سبق قبل كتابة هذا المقال. الآن، لدي شعور حول كيفية تقدير القيمة الناتجة للدخل الطبيعي. ونلاحظ أنه بالنسبة للدخل الذي يتراوح من 0 إلى $\infty$، فإن قيمته تتراوح من 0.5 إلى 1، وبالنسبة للدخل الذي يتراوح من $-\infty$ إلى 0، فإن قيمته تتراوح من 0 إلى 0.5.
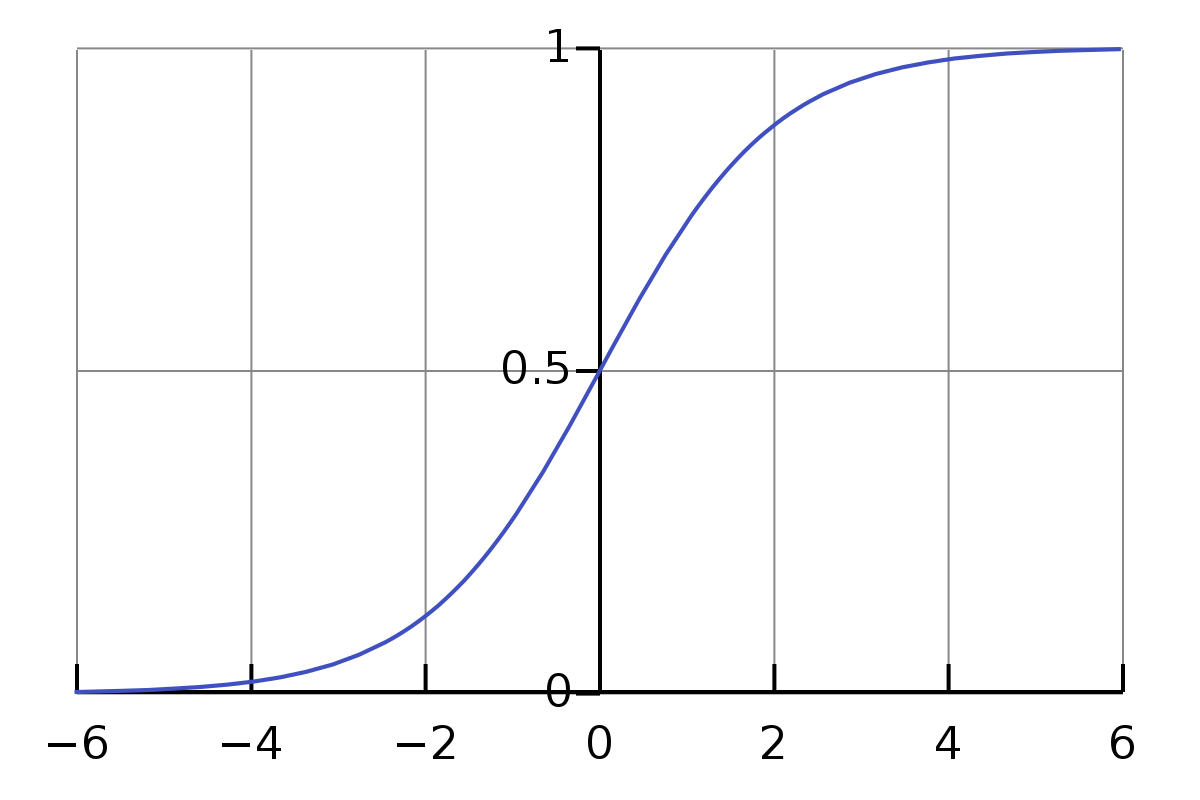
لذلك فيما يتعلق بالمعادلات المذكورة أعلاه، فهي ليست دقيقة. المعادلات الأكثر دقة يجب أن تكون كما يلي:
\[\begin{eqnarray} \sigma(w_1*a_1 + ... + w_6*a_6+b_1) = c_1 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_2) = c_2 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_3) = c_3 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_4) = c_4 \end{eqnarray}\]إذن بالنسبة للمعادلة الأولى، فإنها تكون كالتالي،
\[\frac{1}{1+e^{-(w_1*a_1 +...+ w_6*a_6+b_1)}}\]تمثل المعادلة أعلاه دالة السيني (Sigmoid function)، والتي تُستخدم عادةً في الشبكات العصبية كدالة تنشيط. تُحسب القيمة الناتجة من خلال تطبيق الدالة على المجموع المرجح للمدخلات (a_1) إلى (a_6) مع الأوزان (w_1) إلى (w_6)، مضافًا إليها الانحياز (b_1). النتيجة تكون دائمًا بين 0 و1، مما يجعلها مفيدة في تصنيف الاحتمالات.
كيف يمكننا تحديث الوزن الجديد لـ $w_1$؟ أي،
\[w_1 \rightarrow w_1' = w_1- \Delta w\]يتم ترجمة المعادلة أعلاه إلى:
\[w_1 \rightarrow w_1' = w_1- \Delta w\]حيث:
- ( w_1 ) هي القيمة الأصلية.
- ( w_1’ ) هي القيمة الجديدة بعد التحديث.
- ( \Delta w ) هو التغيير المطبق على ( w_1 ).
إلى المعادلة،
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\]مشتقتها بالنسبة إلى $w_1$ هي $a_1$. لنعطي المجموع رمزًا $S_1$.
إذًا،
\[\frac{\partial S_1}{\partial w_1} = a_1 , \frac{\partial S_1}{\partial w_2} = a_2, ...\]المشتقة تعني معدل التغير. هذا يعني أنه بالنسبة للتغير $\Delta w$ في $w_1$، فإن التغير في النتيجة $S_1$ هو $a_1 * \Delta w$. وكيف يمكننا عكس مثل هذا الحساب؟ لنحسبه.
\[\begin{eqnarray} S_1' - S_1 = \Delta S_1 \\ \frac{\Delta S_1}{a_1} = \Delta w \\ w_1- \Delta w = w_1' \end{eqnarray}\]تم ترجمة المعادلات أعلاه إلى العربية كما يلي:
\[\begin{eqnarray} S_1' - S_1 = \Delta S_1 \\ \frac{\Delta S_1}{a_1} = \Delta w \\ w_1- \Delta w = w_1' \end{eqnarray}\]وتشرح قاعدة السلسلة أن مشتقة الدالة $f(g(x))$ هي $f’(g(x))⋅g’(x)$.
إذن هنا،
\[\begin{eqnarray} f(z) = \sigma(z) = \frac{1}{1+e^{-z}} \\ g(x) = w_1*a_1 +...+ w_6*a_6+b_1 \end{eqnarray}\]ومشتق دالة السيجمويد هو،
\[\sigma'(z) = \frac{\sigma(z)}{1-\sigma(z)}\]إذًا، مشتقة الدالة $f(g(w_1))$ هي $\frac{\sigma(z)}{1-\sigma(z)} * a_1$.
إذن،
\[\begin{eqnarray} \frac{\sigma(z)}{1-\sigma(z)} * a_1 * \Delta w = \Delta C \\ \Delta w = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)} * a_1} \end{eqnarray}\]وللتحيز ( b_1 )،
\[\begin{eqnarray} g'(b_1) = 1 \\ \frac{\sigma(z)}{1-\sigma(z)} * \Delta b = \Delta C \\ \Delta b = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)}} \end{eqnarray}\]الكود
طريقة طباعة المتغيرات مفيدة جدًا وبسيطة، على الرغم من أن الناس في الوقت الحاضر اخترعوا Jupyter Notebook للقيام بمثل هذه الأشياء. كما ذكر Zhiwei سابقًا، أحد مفاتيح فهم الشبكات العصبية هو أننا يجب أن ننتبه إلى الأبعاد.
def print_shape(array):
arr = np.array(array)
print(arr.shape)
print(len(test_data[0][0])) # 10
print_shape(training_results[0]) # (784, 1)
print(list(training_data)[0:1]) # <class 'list'>
تمت ترجمة الكود أعلاه إلى العربية مع الحفاظ على الأسماء الإنجليزية كما هي.
بما أن Zhiwei قد أنهى للتو جزء تحميل البيانات، سيستمر في استخدام نفس الطريقة المتمثلة في نسخ عدة أسطر وطباعة المتغيرات لتعلم الجزء الفعلي من الشبكة العصبية. يمكنك متابعة التقدم هنا: https://github.com/lzwjava/neural-networks-and-zhiwei-learning.
لقد علقت عدة مرات أثناء التقدم. على الرغم من أن الكود يبدو بسيطًا جدًا، إلا أنني بعد محاولة فهمه مرارًا وتكرارًا، فشلت. ثم قررت أن أخرج نفسي من السطر الحالي للكود وأنظر إليه من منظور أوسع، لأفكر في سبب كتابة المؤلف لهذا الجزء من الكود، وفجأة فهمته. الكود هو كما يلي:
def load_data_wrapper():
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
تم تحويل الكود أعلاه إلى:
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
ملاحظة: الكود لم يتم ترجمته لأنه يحتوي على أسماء متغيرات ودوال إنجليزية، وهي أجزاء لا يتم ترجمتها عادةً في البرمجة.
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
تم تحويل المدخلات إلى شكل مناسب للتحقق من صحتها عن طريق تغيير شكل كل عنصر في va_d[0] إلى مصفوفة ذات بعد واحد بحجم 784. ثم تم دمج هذه المدخلات مع التسميات المقابلة لها من va_d[1] باستخدام الدالة zip لإنشاء بيانات التحقق النهائية.
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
الترجمة:
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
في الكود أعلاه:
- يتم إعادة تشكيل كل عنصر في
te_d[0]إلى مصفوفة ذات شكل(784, 1). - يتم دمج هذه المدخلات مع التسميات المقابلة لها في
te_d[1]باستخدام الدالةzip. - يتم إرجاع ثلاث مجموعات من البيانات:
training_data،validation_data، وtest_data.
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e
هنا، أبعاد المتغيرات معقدة. ومع ذلك، عندما نفكر في مبادرة المؤلف، فإننا نحصل على بعض الأدلة. انظر إليها، الكود مركب من ثلاثة أجزاء متشابهة. وكل جزء تقريبًا هو نفسه على الرغم من أن أسماء المتغيرات مختلفة. الآن، يبدو الأمر مريحًا جدًا بالنسبة لي. الدالة zip، العملية for على القائمة، ودالة reshape. الفهم يتراكم ببساطة بين مئات المرات من طباعة المتغيرات ومحاولة فهم سبب أن تكون قيم المتغيرات هكذا.
ودائمًا ما يجد Zhiwei الأخطاء ذات قيمة كبيرة. مثل الكود أدناه، يواجه الكثير من الأخطاء، على سبيل المثال،
- TypeError: شكل غير صالح (784,) لبيانات الصورة
- ValueError: تعيين عنصر مصفوفة بتسلسل. المصفوفة المطلوبة لها شكل غير متجانس بعد بعدين. الشكل المكتشف كان (1, 2) + جزء غير متجانس.
تتبع خطأ المكدس يشبه قصيدة جميلة.
أيضًا، عندما نقوم بتنسيق قيمة الإخراج في Visual Studio Code، تصبح أكثر قابلية للقراءة.
[array([[0.92733598],
[0.01054299],
[1.0195613],
...
[0.67045368],
[-0.29942482],
[-0.35010666]]),
array([[-1.87093344],
[-0.18758503],
[1.35792778],
...
[0.36830578],
[0.61671649],
[0.67084213]])]
شكرًا لك على القراءة. Thank you for your reading.
ملاحظة: بعض الصور مأخوذة من كتاب “الشبكات العصبية والتعلم العميق”.