禅与机器学习的艺术
Home
ChatGPT 帮助翻译。
禅
一个年轻的爸爸在周末忙于学习神经网络。然而,这个周末,他需要陪伴他的宝贝女儿在公寓楼的游泳池里游泳。他躺在浅水中,看着顶楼的公寓大楼冲向天空。突然间,他想到,哇,它们很像神经网络。每个阳台就像一个神经元,而一栋大楼就像一层神经元,而一组大楼则组合成一个神经网络。
然后他想到了反向传播。反向传播的作用是将错误反向传播到神经元。在一次训练的末尾,算法计算了最后一层输出与目标结果之间的误差。实际上,神经网络与神经元无关,而是关于可微分计算。
在写下了文章《我终于理解了神经网络是如何工作的》之后,他发现自己还是没有理解透彻。理解是一种相对的事情。正如理查德·费曼指出的,没有人能够对任何事情百分之百确定,我们只能对某些事情相对确定。所以,智维说出这样的话是可以接受的。
于是他想出了一种深入理解神经网络的方法,即每次复制几行示例代码,然后运行并打印变量。这是关于简单神经网络识别手写数字的方法。他最近正在阅读的书名为《神经网络与深度学习》。所以他将他的GitHub存储库命名为《神经网络和智维学习》。
在使用神经网络训练数据之前,我们首先需要加载数据。这部分花了他一周的休闲时间来完成。事情总是需要更多的时间来完成。但只要我们不放弃,我们就能做很多事情。
机器学习领域中的mnist代表修改版的国家标准与技术研究院数据库。因此,我们的数据加载器文件被称为minst_loader。我们使用Python的打印函数打印了许多列表和ndarray数组。nd表示n维。
除了打印,我们还必须使用matplotlib库来显示我们的数字。如下所示。
艺术
让我们看更多的数字。

有时候能够看到图片而不是整天面对杂乱的代码,这更加愉快。
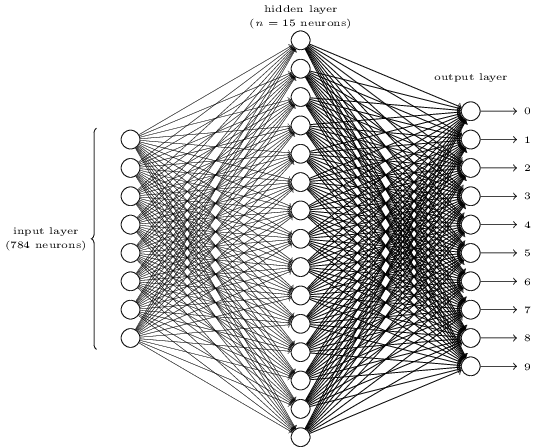
看起来复杂吗?在这里,每层神经元可能太多了,这让事情变得模糊。一旦你理解了它,它实际上是非常简单的。关于上面的图片,有三层,输入层、隐藏层和输出层。每一层连接到下一层。但是,784个输入层的神经元如何变成第二层的15个神经元呢?15个隐藏层的神经元如何变成输出层的10个神经元呢?
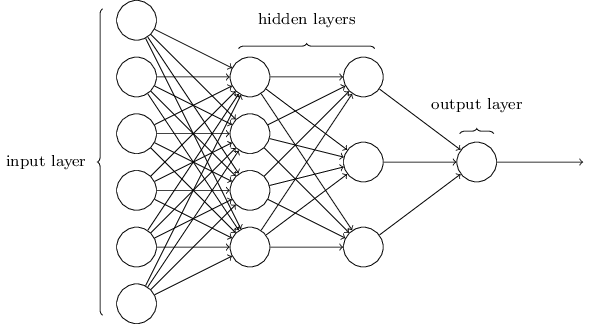
这个网络要简单得多。尽管智维不想在这篇文章中包含任何数学公式,但这里的数学太简单而又美丽,不容隐藏。
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\]假设我们将网络表示如下。
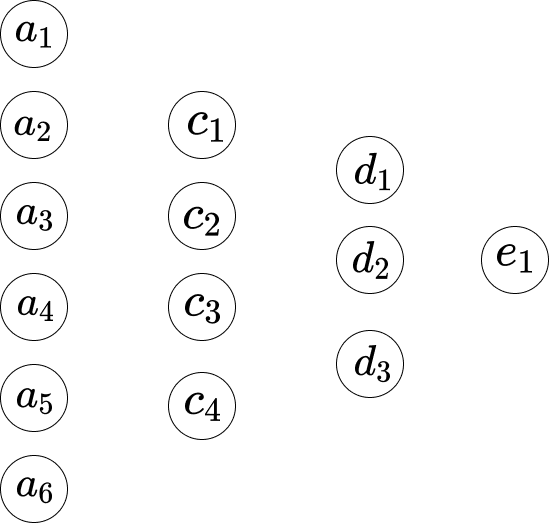
因此,在第一层和第二层之间,我们有以下方程组。
\[\begin{eqnarray} w_1*a_1 +...+ w_6*a_6+b_1 = c_1 \\ w_1*a_1 +...+ w_6*a_6+b_2 = c_2 \\ w_1*a_1 +...+ w_6*a_6+b_3 = c_3 \\ w_1*a_1 +...+ w_6*a_6+b_4 = c_4 \end{eqnarray}\]这里,方程1有一组权重,方程2有另一组权重。因此,方程1中的$w_1$与方程2中的$w_1$不同。因此,在第二层和第三层之间,我们有以下方程组。
\[\begin{eqnarray} w_1*c_1 + ... + w_4*c_4+b_1 = d_1 \\ w_1*c_1 + ... + w_4*c_4+b_2 = d_2 \\ w_1*c_1 + ... + w_4*c_4+b_3 = d_3 \end{eqnarray}\]在第三层到最后一层,我们有以下方程。
\[w_1*d_1 + w_2*d_2+ w_3*d_3+ b_1 = e_1 \\\]上述方程的一个问题是值不够简单或正式。乘法和加法的值范围相当大。我们希望将其限制在一个小范围内,例如0到1。因此,在这里,我们引入了Sigmoid函数。
\[\sigma(z) \equiv \frac{1}{1+e^{-z}}\]我们不需要对sigma符号$\sigma$感到害怕。它只是一个符号,就像符号a一样。如果我们将输入设为0.5,则其值为
\[\frac{1}{1+e^{-0.5}} \approx 0.622459\]而且,
\[\frac{1}{1+e^{-(-100)}} \approx 3.72*e^{-44} \\ \frac{1}{1+e^{-(-10)}} \approx 0.000045 \\ \frac{1}{1+e^{-(-1)}} \approx 0.26894 \\ \frac{1}{1+e^{-{0}}} = 0.5 \\ \frac{1}{1+e^{-10}} \approx 0.99995 \\ \frac{1}{1+e^{-100}} = 1\]这是有趣的。在写这篇文章之前,我不知道上述内容。现在,我对其对于正常输入的近似结果有了一种感觉。我们观察到,对于范围从0到$\infty$的输入,其值从0.5到1;对于范围从$-\infty$到0的输入,其值从0到0.5。
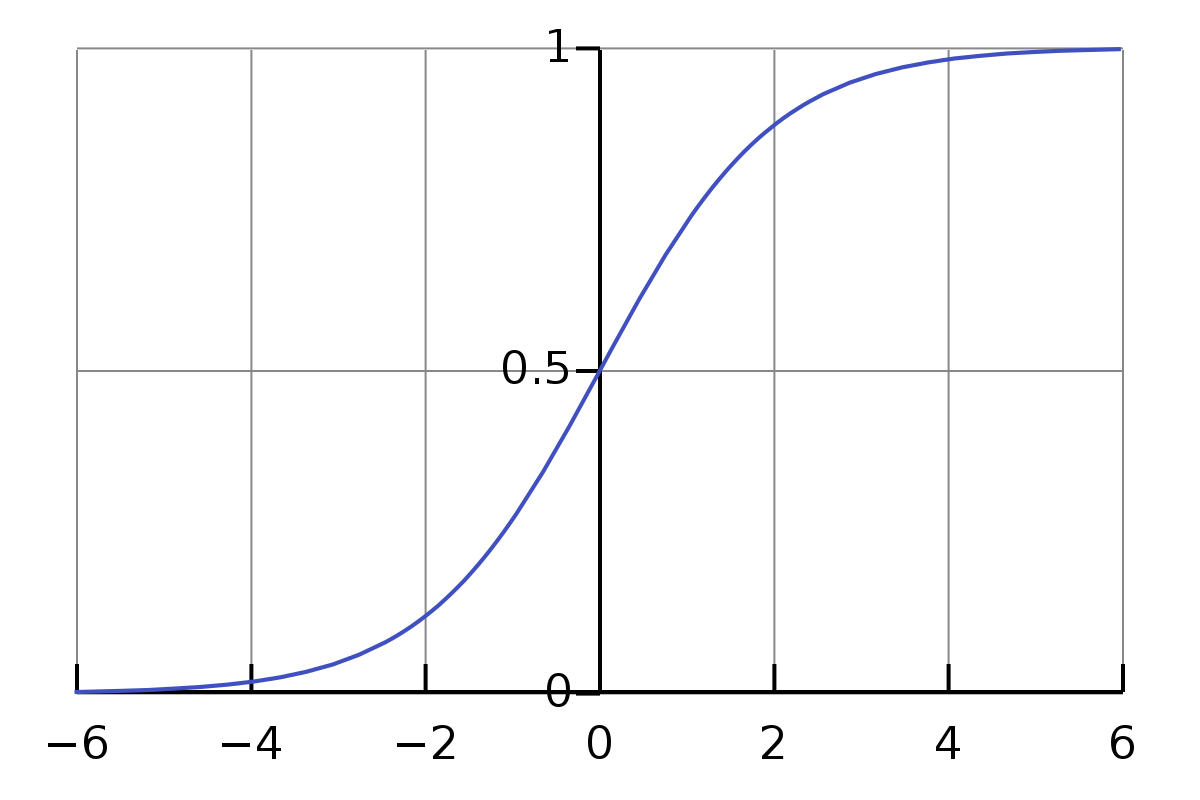
因此,对于上述方程,它们并不准确。最适当的方程应该如下。
\[\begin{eqnarray} \sigma(w_1*a_1 + ... + w_6*a_6+b_1) = c_1 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_2) = c_2 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_3) = c_3 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_4) = c_4 \end{eqnarray}\]因此,对于第一个方程,即
\[\frac{1}{1+e^{-(w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1)}}\]我们如何更新$w_1$的新权重?也就是说,
\[w_1 \rightarrow w_1' = w_1- \Delta w\]对于方程,
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\]它对$w_1$的导数是$a_1$。让我们给总和一个符号$S_1$。
因此,
\[\frac{\partial S_1}{\partial w_1} = a_1 , \frac{\partial S_1}{\partial w_2} = a_2, ...\]导数表示变化率。这意味着对于$w_1$中的变化$\Delta w$,它在结果$S_1$中的变化是$a_1 * \Delta w$。那么我们如何反转这样的计算?让我们来计算一下。
\[S_1' - S_1 = \Delta S_1 \\ \frac{\Delta S_1}{a_1} = \Delta w \\ w_1- \Delta w = w_1'\]链式法则解释了$f(g(x))$的导数是$f’(g(x))⋅g’(x)$。
因此,在这里,
\[f(z) = \sigma(z) = \frac{1}{1+e^{-z}} \\ g(x) = w_1*a_1 +...+ w_6*a_6+b_1\]而Sigmoid函数的导数是,
\[\sigma'(z) = \frac{\sigma(z)}{1-\sigma(z)}\]因此,$f(g(w_1))$的导数是$\frac{\sigma(z)}{1-\sigma(z)} * a_1$。
因此,
\[\frac{\sigma(z)}{1-\sigma(z)} * a_1 * \Delta w = \Delta C \\ \Delta w = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)} * a_1}\]对于偏置$b_1$,
\[g'(b_1) = 1 \\ \frac{\sigma(z)}{1-\sigma(z)} * \Delta b = \Delta C \\ \Delta b = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)}}\]代码
尽管如今人们发明了Jupyter Notebook来执行这些操作,但打印变量的方式非常有用和简单。正如智维之前提到的,理解神经网络的关键之一是要注意维度。
def print_shape(array):
arr = np.array(array)
print(arr.shape)
print(len(test_data[0][0])) # 10
print_shape(training_results[0]) # (784, 1)
print(list(training_data)[0:1]) # <class 'list'>
现在,智维刚刚完成了加载数据部分,他将继续使用复制几行代码并打印变量的方式来学习神经网络的实际部分。您可以在这里跟踪进展,https://github.com/lzwjava/neural-networks-and-zhiwei-learning。
在进展过程中,我遇到了几次困难。尽管代码看起来非常简单,但在一次次尝试理解之后,我失败了。然后,我将自己从当前代码行中抽离出来,从高层次上观察它,思考为什么作者会写那部分代码,突然间我明白了。下面是代码。
def load_data_wrapper():
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e
在这里,变量的维度很复杂。然而,当我们思考作者的初衷时,我们就有了一些线索。看看代码,它由三个类似部分组合在一起。每个部分几乎相同,尽管变量的名称不同。现在,对我来说,这似乎非常容易了。zip函数,对列表的“for”操作和reshape函数。理解仅仅是在数百次打印变量和试图弄清楚变量的值为何如此之间的累积。
而智维总是将错误视为宝贵的财富。就像下面的代码一样,他面对着许多错误,例如:
- TypeError: 图像数据的形状无效(784,)
- ValueError: 使用序列设置数组元素时出现值错误。请求的数组在2个维度之后具有不均匀的形状。检测到的形状是(1, 2)+ 不均匀部分。
错误堆栈跟踪日志,就像优美的诗一样。
此外,当我们在Visual Studio Code中对值进行格式化输出时,它会更易读。
[array([[0.92733598],
[0.01054299],
[1.0195613],
...
[0.67045368],
[-0.29942482],
[-0.35010666]]),
array([[-1.87093344],
[-0.18758503],
[1.35792778],
...
[0.36830578],
[0.61671649],
[0.67084213]])]
読んでくれてありがとう (Yonde kurete arigatō)。感谢您的阅读。
注:部分图片来自《神经网络与机器学习》一书。