Zen und die Kunst des maschinellen Lernens | Original, von KI übersetzt
Zen
Ein junger Vater ist am Wochenende damit beschäftigt, Neuronale Netzwerke zu lernen. Doch an diesem Wochenende musste er seine kleine Tochter zum Schwimmen im Pool des Wohnkomplexes begleiten. Er legte sich ins flache Wasser und beobachtete die hohen Wohngebäude, die in den Himmel ragten. Plötzlich dachte er: Wow, sie sind wirklich wie neuronale Netzwerke. Jeder Balkon ist wie ein Neuron. Und ein Gebäude ist wie eine Schicht von Neuronen. Eine Gruppe von Gebäuden bildet zusammen ein neuronales Netzwerk.
Dann dachte er über Backpropagation nach. Was Backpropagation tut, ist, die Fehler zu den Neuronen zurückzupropagieren. Am Ende eines einmaligen Trainings berechnet der Algorithmus den Fehler zwischen der Ausgabe der letzten Schicht und dem Zielergebnis. Tatsächlich haben neuronale Netze nichts mit Neuronen zu tun. Es geht um differenzierbare Berechnungen.
Nachdem er den Artikel “Ich verstehe endlich, wie neuronale Netzwerke funktionieren” geschrieben hatte, stellte er fest, dass er es immer noch nicht verstand. Verständnis ist eine relative Sache. Wie Richard Feynman betont, kann niemand zu 100 % sicher über irgendetwas sein, wir können nur relativ sicher sein. Daher ist es für Zhiwei akzeptabel, dies zu sagen.
Also fand er einen Weg, Neuronale Netzwerke tiefgehend zu verstehen, indem er jedes Mal mehrere Zeilen Beispielcode kopierte, sie ausführte und Variablen ausgab. Es geht um ein einfaches neuronales Netzwerk zur Erkennung handgeschriebener Ziffern. Das Buch, das er kürzlich liest, trägt den Titel Neural Networks and Deep Learning. Daher gab er seinem GitHub-Repository den Namen Neural Networks and Zhiwei Learning.
Bevor wir ein neuronales Netzwerk verwenden, um unsere Daten zu trainieren, müssen wir zuerst die Daten laden. Dieser Teil hat ihn eine Woche Freizeit gekostet, um ihn zu erledigen. Dinge brauchen oft mehr Zeit, als man denkt, um sie zu erledigen. Aber solange wir nicht aufgeben, sind wir in der Lage, ziemlich viele Dinge zu schaffen.
Die MNIST im Bereich des maschinellen Lernens steht für die Modified National Institute of Standards and Technology-Datenbank. Daher heißt unsere Datenlade-Datei mnist_loader. Wir verwenden die print-Funktion in Python, um viele Listen und Arrays von ndarray auszugeben. Das nd in ndarray steht für n-dimensional.
Neben print müssen wir die matplotlib-Bibliothek verwenden, um unsere Ziffern anzuzeigen. Wie unten gezeigt.
Kunst
Lassen Sie uns mehr Ziffern sehen.

Es ist erfreulicher, wenn man manchmal Bilder sehen kann, anstatt den ganzen Tag mit lauten Codes konfrontiert zu sein.
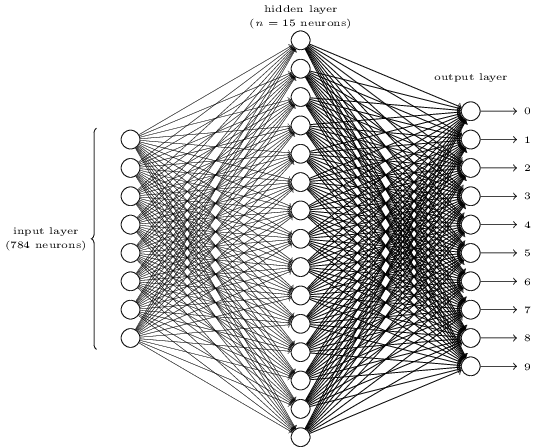
Erscheint es kompliziert? Hier haben wir möglicherweise zu viele Neuronen in jeder Schicht. Und das macht die Dinge unklar. Es ist eigentlich sehr einfach, sobald man es verstanden hat. Das erste, was an dem obigen Bild auffällt, ist, dass es drei Schichten hat: die Eingabeschicht, die versteckte Schicht und die Ausgabeschicht. Und eine Schicht verbindet sich mit der nächsten Schicht. Aber wie können 784 Neuronen in der Eingabeschicht zu den 15 Neuronen in der zweiten Schicht werden? Und wie können 15 Neuronen in der versteckten Schicht zu den 10 Neuronen in der Ausgabeschicht werden?
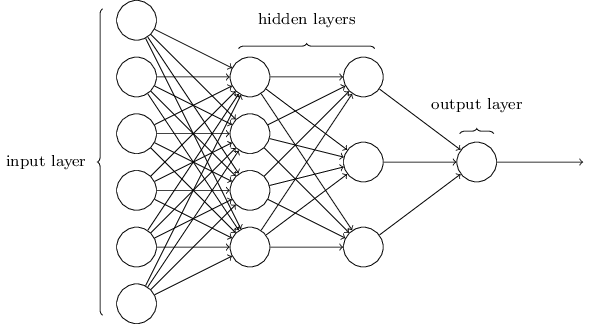
</div>
Dieses Netzwerk ist viel einfacher. Obwohl Zhiwei keine mathematischen Formeln in diesen Artikel aufnehmen möchte, ist die Mathematik hier zu einfach und schön, um sie zu verbergen.
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\](Dies ist eine mathematische Formel und wird nicht übersetzt.)
Angenommen, wir stellen das Netzwerk wie folgt dar.
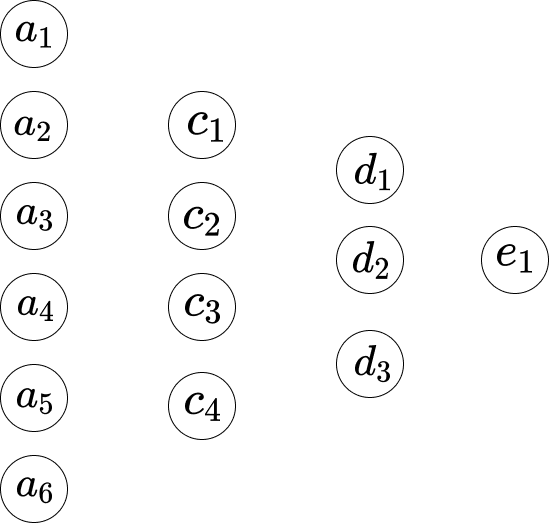
Zwischen der ersten Schicht und der zweiten Schicht haben wir die folgenden Gleichungen.
\[\begin{eqnarray} w_1*a_1 +...+ w_6*a_6+b_1 = c_1 \\ w_1*a_1 +...+ w_6*a_6+b_2 = c_2 \\ w_1*a_1 +...+ w_6*a_6+b_3 = c_3 \\ w_1*a_1 +...+ w_6*a_6+b_4 = c_4 \end{eqnarray}\]Hier hat Gleichung 1 eine Gruppe von Gewichten, und Gleichung 2 hat eine andere Gruppe von Gewichten. Daher ist das $w_1$ in Gleichung 1 anders als das $w_1$ in Gleichung 2. Und zwischen der zweiten Schicht und der dritten Schicht haben wir die folgenden Gleichungen.
\[\begin{eqnarray} w_1*c_1 + ... + w_4*c_4+b_1 = d_1 \\ w_1*c_1 + ... + w_4*c_4+b_2 = d_2 \\ w_1*c_1 + ... + w_4*c_4+b_3 = d_3 \end{eqnarray}\]Und in der dritten Schicht bis zur letzten Schicht haben wir die folgenden Gleichungen.
\[w_1 \cdot d_1 + w_2 \cdot d_2 + w_3 \cdot d_3 + b_1 = e_1\]Das Problem mit den obigen Gleichungen ist, dass der Wert nicht einfach oder formal genug ist. Der Wertebereich der Multiplikation und Addition ist ziemlich groß. Wir möchten, dass er auf einen kleinen Bereich beschränkt ist, zum Beispiel von 0 bis 1. Hier kommt die Sigmoid-Funktion ins Spiel.
\[\sigma(z) \equiv \frac{1}{1+e^{-z}}\]Wir müssen uns nicht vom Sigma-Symbol $\sigma$ einschüchtern lassen. Es ist nur ein Symbol, genau wie das Symbol a. Wenn wir ihm den Eingabewert 0,5 geben, ist sein Wert
\[\frac{1}{1+e^{-0.5}} \approx 0.622459\]Und,
\[\begin{eqnarray} \frac{1}{1+e^{-(-100)}} \approx 3.72*e^{-44} \\ \frac{1}{1+e^{-(-10)}} \approx 0.000045 \\ \frac{1}{1+e^{-(-1)}} \approx 0.26894 \\ \frac{1}{1+e^{-{0}}} = 0.5 \\ \frac{1}{1+e^{-10}} \approx 0.99995 \\ \frac{1}{1+e^{-100}} = 1 \end{eqnarray}\]Es ist hier faszinierend. Ich kannte das oben genannte nicht, bevor ich diesen Artikel geschrieben habe. Jetzt habe ich ein Gefühl dafür, wie sein ungefährer Ergebniswert für die normale Eingabe ist. Und wir beobachten, dass für die Eingabe, die von 0 bis $\infty$ reicht, sein Wert von 0,5 bis 1 liegt, und für die Eingabe, die von $-\infty$ bis 0 reicht, sein Wert von 0 bis 0,5 liegt.
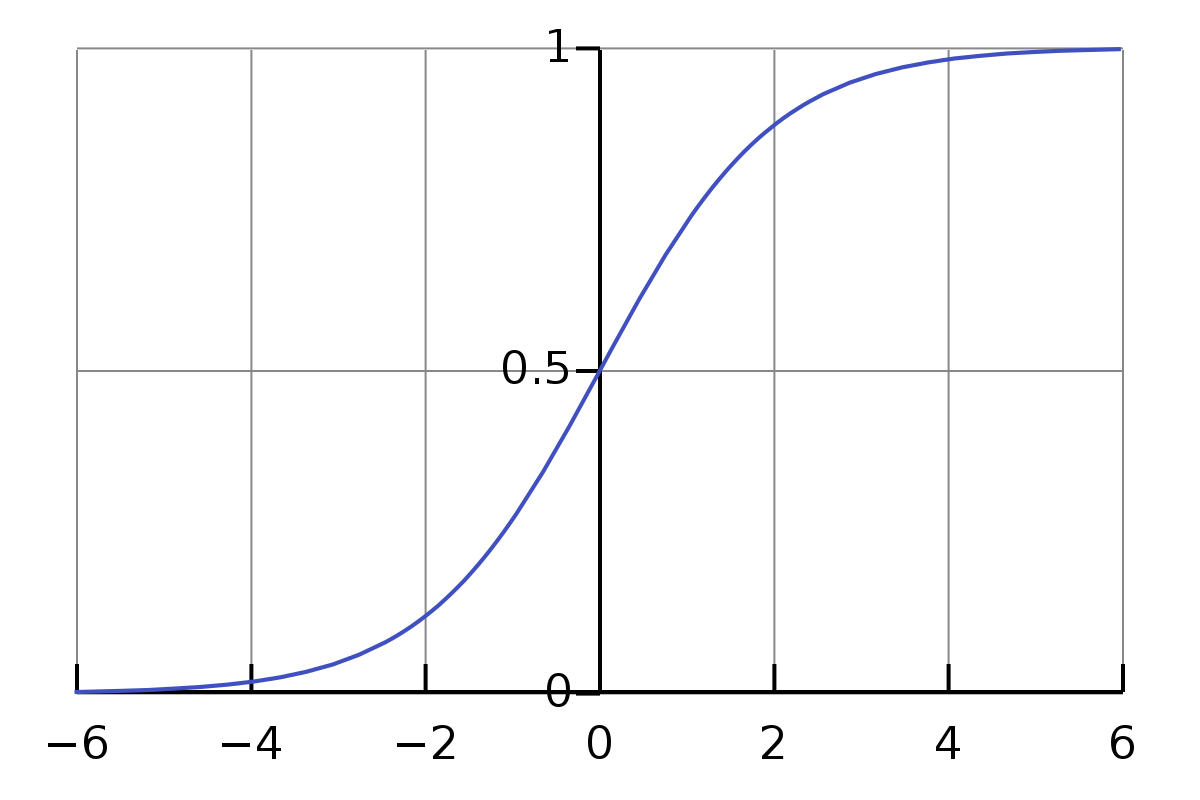
Bezüglich der obigen Gleichungen sind sie nicht korrekt. Die korrektesten sollten wie folgt aussehen:
\[\begin{eqnarray} \sigma(w_1*a_1 + ... + w_6*a_6+b_1) = c_1 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_2) = c_2 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_3) = c_3 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_4) = c_4 \end{eqnarray}\]Für die erste Gleichung gilt also:
\[\frac{1}{1+e^{-(w_1*a_1 +...+ w_6*a_6+b_1)}}\]Wie können wir das neue Gewicht für $w_1$ aktualisieren? Das heißt,
\[w_1 \rightarrow w_1' = w_1 - \Delta w\]Zur Gleichung,
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\]Seine Ableitung nach $w_1$ ist $a_1$. Geben wir der Summe ein Symbol $S_1$.
Also,
\[\frac{\partial S_1}{\partial w_1} = a_1 , \frac{\partial S_1}{\partial w_2} = a_2, ...\]Die Ableitung bedeutet die Änderungsrate. Das bedeutet, dass für die Änderung $\Delta w$ in $w_1$ die Änderung im Ergebnis $S_1$ gleich $a_1 * \Delta w$ ist. Und wie können wir eine solche Berechnung umkehren? Lasst es uns berechnen.
\[\begin{eqnarray} S_1' - S_1 = \Delta S_1 \\ \frac{\Delta S_1}{a_1} = \Delta w \\ w_1- \Delta w = w_1' \end{eqnarray}\]Und die Kettenregel erklärt, dass die Ableitung von $f(g(x))$ gleich $f’(g(x))⋅g’(x)$ ist.
Hier also,
\[\begin{eqnarray} f(z) = \sigma(z) = \frac{1}{1+e^{-z}} \\ g(x) = w_1*a_1 +...+ w_6*a_6+b_1 \end{eqnarray}\]Und die Ableitung der Sigmoid-Funktion ist,
\[\sigma'(z) = \frac{\sigma(z)}{1-\sigma(z)}\]Die Ableitung von $f(g(w_1))$ ist also $\frac{\sigma(z)}{1-\sigma(z)} * a_1$.
Also,
\[\begin{eqnarray} \frac{\sigma(z)}{1-\sigma(z)} * a_1 * \Delta w = \Delta C \\ \Delta w = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)} * a_1} \end{eqnarray}\]Und für den Bias $b_1$,
\[\begin{eqnarray} g'(b_1) = 1 \\ \frac{\sigma(z)}{1-\sigma(z)} * \Delta b = \Delta C \\ \Delta b = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)}} \end{eqnarray}\]Code
Die Art und Weise, wie Variablen ausgegeben werden, ist sehr nützlich und einfach, obwohl heutzutage Leute Jupyter Notebook erfinden, um solche Dinge zu erledigen. Wie Zhiwei bereits erwähnt hat, ist einer der Schlüssel zum Verständnis von neuronalen Netzwerken, dass wir auf die Dimensionen achten sollten.
def print_shape(array):
arr = np.array(array)
print(arr.shape)
print(len(test_data[0][0])) # 10
print_shape(training_results[0]) # (784, 1)
print(list(training_data)[0:1]) # <class 'list'>
Deutsche Übersetzung:
def print_shape(array):
arr = np.array(array)
print(arr.shape)
print(len(test_data[0][0])) # 10
print_shape(training_results[0]) # (784, 1)
print(list(training_data)[0:1]) # <class 'list'>
Hinweis: Der Code selbst bleibt unverändert, da es sich um Programmiersprache handelt. Die Kommentare im Code wurden ebenfalls nicht übersetzt, da sie spezifische Informationen über die Ausgabe des Codes enthalten.
Da Zhiwei gerade den Teil des Datenladens abgeschlossen hat, wird er weiterhin die gleiche Methode des Kopierens mehrerer Zeilen und des Ausgebens von Variablen verwenden, um den eigentlichen Teil des neuronalen Netzwerks zu erlernen. Sie können den Fortschritt hier verfolgen: https://github.com/lzwjava/neural-networks-and-zhiwei-learning.
Ich bin mehrmals im Fortschritt stecken geblieben. Obwohl der Code sehr einfach erscheint, habe ich es nach mehreren Versuchen, ihn zu verstehen, nicht geschafft. Dann habe ich mich aus der aktuellen Codezeile herausbewegt, um ihn aus einer höheren Perspektive zu betrachten und darüber nachzudenken, warum der Autor diesen Teil des Codes geschrieben hat. Plötzlich habe ich es verstanden. Der Code ist unten zu sehen.
def load_data_wrapper():
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e
Hier sind die Dimensionen der Variablen komplex. Wenn wir jedoch über die Initiative des Autors nachdenken, haben wir einige Hinweise. Schauen Sie, der Code besteht aus drei ähnlichen Teilen. Und jeder Teil ist fast gleich, obwohl die Namen der Variablen unterschiedlich sind. Jetzt scheint es mir sehr vertraut. Das zip, die for-Schleife über die Liste und die reshape-Funktion. Das Verständnis wächst einfach durch das Hunderte Male Ausgeben von Variablen und das Versuchen, herauszufinden, warum die Werte der Variablen so sind.
Und Zhiwei findet Fehler immer sehr wertvoll. Wie im folgenden Code sieht er sich vielen Fehlern gegenüber, zum Beispiel:
- TypeError: Ungültige Form (784,) für Bilddaten
- ValueError: Zuweisung eines Array-Elements mit einer Sequenz. Das angeforderte Array hat nach 2 Dimensionen eine inhomogene Form. Die erkannte Form war (1, 2) + inhomogener Teil.
Der Fehler-Stack-Trace ist wie ein schönes Gedicht.
Außerdem ist die formatierte Ausgabe des Werts in Visual Studio Code viel besser lesbar.
[array([[0.92733598],
[0.01054299],
[1.0195613],
...
[0.67045368],
[-0.29942482],
[-0.35010666]]),
array([[-1.87093344],
[-0.18758503],
[1.35792778],
...
[0.36830578],
[0.61671649],
[0.67084213]])]
(Der Code wurde nicht übersetzt, da es sich um eine numerische Darstellung handelt, die in der Regel sprachunabhängig ist.)
Vielen Dank fürs Lesen. Thank you for your reading.
Hinweis: Einige Bilder sind aus dem Buch “Neural Networks and Deep Learning” übernommen.