Zen y el Arte del Aprendizaje Automático | Original, traducido por IA
Zen
Un joven padre está ocupado aprendiendo sobre redes neuronales durante el fin de semana. Sin embargo, este fin de semana, necesitaba acompañar a su pequeña hija a nadar en la piscina del complejo de apartamentos. Se recostó en el agua poco profunda y observó los edificios de apartamentos que se elevaban hacia el cielo. De repente, pensó: “Vaya, se parecen mucho a las redes neuronales. Cada balcón es como una neurona. Y un edificio es como una capa de neuronas. Y un grupo de edificios se combina para formar una red neuronal”.
Luego pensó en la retropropagación. Lo que hace la retropropagación es propagar los errores hacia las neuronas. Al final de un entrenamiento, el algoritmo calcula el error entre la salida de la última capa y el resultado objetivo. En realidad, las redes neuronales no tienen nada que ver con las neuronas. Se trata de computación diferenciable.
Después de escribir el artículo “Finalmente entiendo cómo funciona una red neuronal”, se dio cuenta de que todavía no lo entendía. Entender es algo relativo. Como Richard Feynman señala algo parecido a que nadie puede estar 100% seguro de nada, solo podemos estar relativamente seguros de algo. Por lo tanto, es aceptable que Zhiwei diga eso.
Así que encontró una manera de entender profundamente las Redes Neuronales copiando varias líneas de código de ejemplo cada vez, ejecutándolo y luego imprimiendo las variables. Se trata de una red neuronal simple para reconocer dígitos escritos a mano. El libro que está leyendo recientemente se titula Neural Networks and Deep Learning. Por eso, decidió nombrar su repositorio en GitHub como Neural Networks and Zhiwei Learning.
Antes de usar una Red Neuronal para entrenar nuestros datos, necesitamos cargar los datos primero. Esta parte le costó una semana de tiempo libre para hacerlo. Las cosas siempre requieren más tiempo del que pensamos para completarlas. Pero mientras no nos rindamos, somos capaces de hacer muchas cosas.
En el área de Machine Learning, MNIST significa “Modified National Institute of Standards and Technology database” (Base de Datos Modificada del Instituto Nacional de Estándares y Tecnología). Por lo tanto, nuestro archivo de carga de datos se llama mnist_loader. Utilizamos la función print en Python para imprimir muchas listas y arreglos de tipo ndarray. El “nd” en ndarray significa “n-dimensional”.
Además de print, debemos usar la biblioteca matplotlib para mostrar nuestros dígitos. Como se muestra a continuación.
Arte
Veamos más dígitos.

Es más alegre cuando, de vez en cuando, puedes ver imágenes en lugar de enfrentarte a códigos ruidosos todo el día.
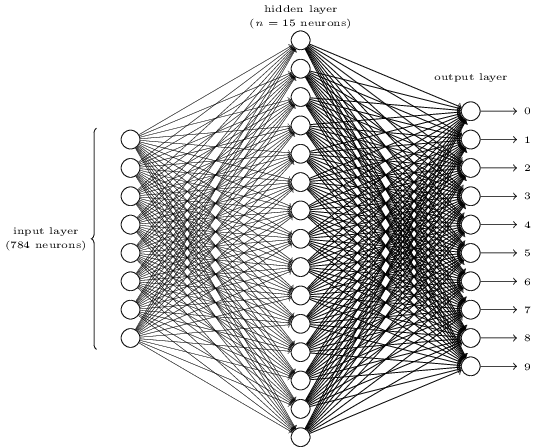
¿Parece complicado? Aquí, podríamos tener demasiadas neuronas en cada capa. Y eso hace que las cosas sean confusas. En realidad, es muy simple una vez que lo entiendes. Lo primero sobre la imagen anterior es que tiene tres capas: la capa de entrada, la capa oculta y la capa de salida. Y una capa se conecta con la siguiente. Pero, ¿cómo pueden 784 neuronas en la capa de entrada convertirse en 15 neuronas en la segunda capa? ¿Y cómo pueden 15 neuronas en la capa oculta convertirse en 10 neuronas en la capa de salida?
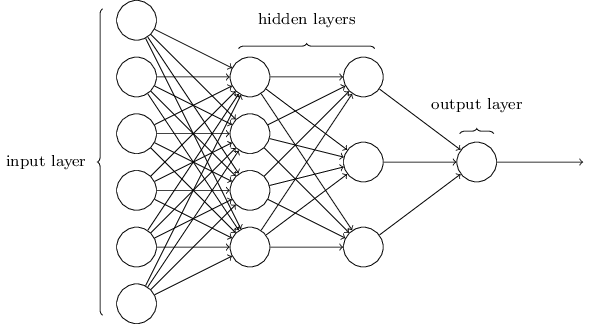
</div>
Esta red es mucho más simple. Aunque Zhiwei no quiere incluir ninguna fórmula matemática en este artículo, aquí las matemáticas son demasiado simples y hermosas para ocultarlas.
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\]Supongamos que indicamos la red de la siguiente manera.
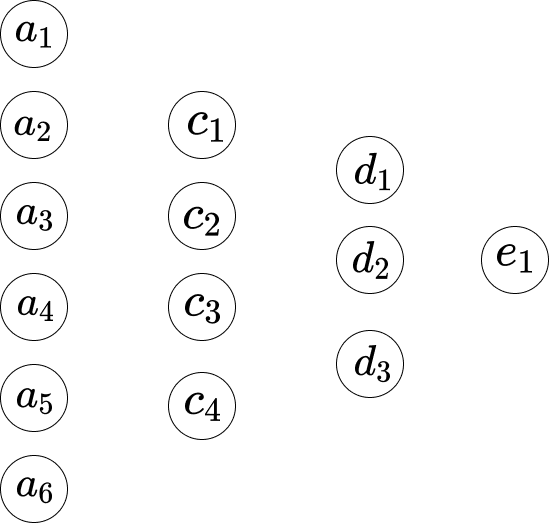
Así que entre la primera capa y la segunda capa, tenemos las siguientes ecuaciones:
\[\begin{eqnarray} w_1*a_1 +...+ w_6*a_6+b_1 = c_1 \\ w_1*a_1 +...+ w_6*a_6+b_2 = c_2 \\ w_1*a_1 +...+ w_6*a_6+b_3 = c_3 \\ w_1*a_1 +...+ w_6*a_6+b_4 = c_4 \end{eqnarray}\]Aquí, la Ecuación 1 tiene un conjunto de pesos, y la Ecuación 2 tiene otro conjunto de pesos. Por lo tanto, el $w_1$ en la Ecuación 1 es diferente del $w_1$ en la Ecuación 2. Y así, entre la segunda capa y la tercera capa, tenemos las siguientes ecuaciones.
\[\begin{eqnarray} w_1*c_1 + ... + w_4*c_4+b_1 = d_1 \\ w_1*c_1 + ... + w_4*c_4+b_2 = d_2 \\ w_1*c_1 + ... + w_4*c_4+b_3 = d_3 \end{eqnarray}\]Y en la tercera capa hasta la última capa, tenemos las siguientes ecuaciones.
\[w_1*d_1 + w_2*d_2 + w_3*d_3 + b_1 = e_1\]El único problema con las ecuaciones anteriores es que el valor no es lo suficientemente simple o formal. El rango del valor de la multiplicación y la suma es bastante amplio. Queremos que esté restringido a un rango pequeño, digamos, de 0 a 1. Así que aquí tenemos la función Sigmoid.
\[\sigma(z) \equiv \frac{1}{1+e^{-z}}\]No tenemos que intimidarnos por el símbolo sigma $\sigma$. Es simplemente un símbolo, al igual que el símbolo “a”. Si le damos como entrada 0.5, su valor será…
\[\frac{1}{1+e^{-0.5}} \approx 0.622459\]Y,
\[\begin{eqnarray} \frac{1}{1+e^{-(-100)}} \approx 3.72*e^{-44} \\ \frac{1}{1+e^{-(-10)}} \approx 0.000045 \\ \frac{1}{1+e^{-(-1)}} \approx 0.26894 \\ \frac{1}{1+e^{-{0}}} = 0.5 \\ \frac{1}{1+e^{-10}} \approx 0.99995 \\ \frac{1}{1+e^{-100}} = 1 \end{eqnarray}\]Es intrigante aquí. No sabía lo anterior antes de escribir este artículo. Ahora, tengo una idea de cómo es su valor aproximado para una entrada normal. Y observamos que para la entrada que va de 0 a $\infty$, su valor está entre 0.5 y 1, y para la entrada que va de $-\infty$ a 0, su valor está entre 0 y 0.5.
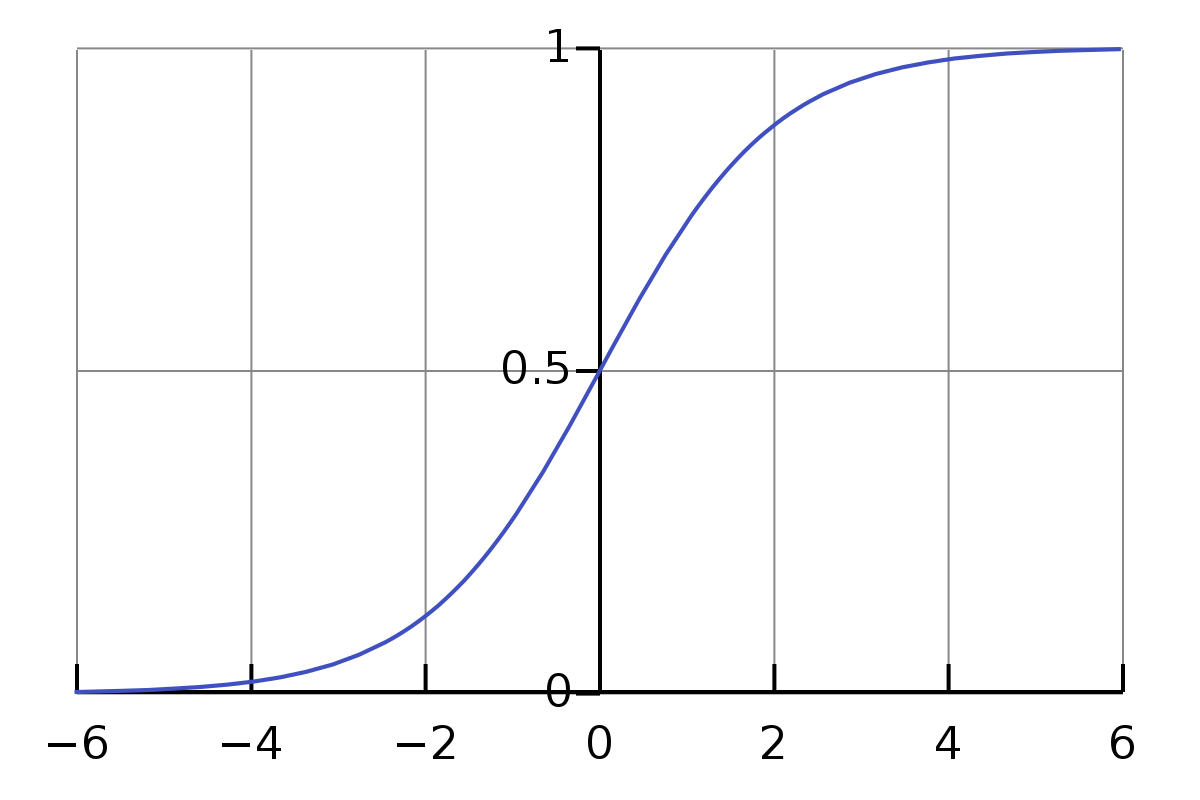
Entonces, con respecto a las ecuaciones anteriores, no son precisas. Las más adecuadas deberían ser las siguientes:
\[\begin{eqnarray} \sigma(w_1*a_1 + ... + w_6*a_6+b_1) = c_1 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_2) = c_2 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_3) = c_3 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_4) = c_4 \end{eqnarray}\]Entonces, para la primera ecuación, es que,
\[\frac{1}{1+e^{-(w_1*a_1 +...+ w_6*a_6+b_1)}}\]¿Cómo podemos actualizar el nuevo peso para $w_1$? Es decir,
\[w_1 \rightarrow w_1' = w_1- \Delta w\]A la ecuación,
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\]Su derivada con respecto a $w_1$ es $a_1$. Vamos a darle a la suma un símbolo $S_1$.
Así que,
\[\frac{\partial S_1}{\partial w_1} = a_1 , \frac{\partial S_1}{\partial w_2} = a_2, ...\]La derivada significa la tasa de cambio. Esto significa que para el cambio $\Delta w$ en $w_1$, su cambio en el resultado $S_1$ es $a_1 * \Delta w$. ¿Y cómo podemos revertir tal cálculo? Vamos a calcularlo.
\[\begin{eqnarray} S_1' - S_1 = \Delta S_1 \\ \frac{\Delta S_1}{a_1} = \Delta w \\ w_1- \Delta w = w_1' \end{eqnarray}\]Y la regla de la cadena explica que la derivada de $f(g(x))$ es $f’(g(x))⋅g’(x)$.
Así que aquí,
\[\begin{eqnarray} f(z) = \sigma(z) = \frac{1}{1+e^{-z}} \\ g(x) = w_1*a_1 +...+ w_6*a_6+b_1 \end{eqnarray}\]Y la derivada de la función sigmoide es,
\[\sigma'(z) = \frac{\sigma(z)}{1-\sigma(z)}\]Entonces, la derivada de $f(g(w_1))$ es $\frac{\sigma(z)}{1-\sigma(z)} * a_1$.
Así que,
\[\begin{eqnarray} \frac{\sigma(z)}{1-\sigma(z)} * a_1 * \Delta w = \Delta C \\ \Delta w = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)} * a_1} \end{eqnarray}\]Y para el sesgo $b_1$,
\[\begin{eqnarray} g'(b_1) = 1 \\ \frac{\sigma(z)}{1-\sigma(z)} * \Delta b = \Delta C \\ \Delta b = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)}} \end{eqnarray}\]Código
La forma de imprimir variables es muy útil y sencilla, aunque hoy en día la gente ha inventado Jupyter Notebook para hacer este tipo de cosas. Como mencionó Zhiwei anteriormente, una de las claves para entender las redes neuronales es que debemos prestar atención a las dimensiones.
def print_shape(array):
arr = np.array(array)
print(arr.shape)
print(len(test_data[0][0])) # 10
print_shape(training_results[0]) # (784, 1)
print(list(training_data)[0:1]) # <class 'list'>
Traducción al español:
def print_shape(array):
arr = np.array(array)
print(arr.shape)
print(len(test_data[0][0])) # 10
print_shape(training_results[0]) # (784, 1)
print(list(training_data)[0:1]) # <class 'list'>
Nota: El código no necesita ser traducido, ya que es un bloque de código y los nombres de las variables y funciones deben permanecer en inglés.
Como ahora Zhiwei acaba de terminar la parte de carga de datos, continuará utilizando la misma forma de copiar varias líneas e imprimir variables para aprender la parte real de la red neuronal. Puedes seguir el progreso aquí: https://github.com/lzwjava/neural-networks-and-zhiwei-learning.
Me quedé atascado varias veces durante el proceso. Aunque parece un código muy simple, después de intentar entenderlo una y otra vez, no lo logré. Luego, me alejé de la línea de código en la que estaba trabajando para observarlo desde una perspectiva más amplia, para pensar por qué el autor escribió esa parte del código, y de repente lo entendí. El código es el siguiente:
def load_data_wrapper():
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e
Aquí, las dimensiones de las variables son complejas. Sin embargo, cuando pensamos en la iniciativa del autor, obtenemos algunas pistas. Observa, el código está compuesto por tres partes similares. Y cada parte es casi la misma, aunque los nombres de las variables son diferentes. Ahora, me parece muy cómodo. El uso de zip, la operación for sobre la lista y la función reshape. La comprensión simplemente se acumula entre las cientos de veces que imprimo variables y trato de entender por qué los valores de las variables son así.
Y Zhiwei siempre encuentra los errores muy valiosos. Como en el siguiente código, se enfrenta a muchos errores, por ejemplo:
- TypeError: Forma no válida (784,) para datos de imagen
- ValueError: al establecer un elemento de un array con una secuencia. El array solicitado tiene una forma no homogénea después de 2 dimensiones. La forma detectada fue (1, 2) + parte no homogénea.
El rastreo de la pila de errores es como un hermoso poema.
Además, cuando formateamos la salida del valor en Visual Studio Code, es mucho más legible.
[array([[0.92733598],
[0.01054299],
[1.0195613],
...
[0.67045368],
[-0.29942482],
[-0.35010666]]),
array([[-1.87093344],
[-0.18758503],
[1.35792778],
...
[0.36830578],
[0.61671649],
[0.67084213]])]
Gracias por leer. Thank you for your reading.
Nota: Algunas imágenes están copiadas del libro “Redes Neuronales y Aprendizaje Profundo”.