Le Zen et l'Art de l'Apprentissage Automatique | Original, traduit par l'IA
Zen
Un jeune papa est occupé à apprendre les réseaux neuronaux le week-end. Cependant, ce week-end, il devait accompagner sa petite fille à la piscine de la résidence. Il s’est allongé dans l’eau peu profonde et a regardé les immeubles s’élever vers le ciel. Et soudain, il a pensé : “Wow, ils ressemblent beaucoup à des réseaux neuronaux. Chaque balcon est comme un neurone. Et un immeuble est comme une couche de neurones. Et un groupe d’immeubles forme un réseau neuronal.”
Il a ensuite réfléchi à la rétropropagation. Ce que fait la rétropropagation, c’est de propager les erreurs vers les neurones. À la fin d’un entraînement unique, l’algorithme calcule l’erreur entre la sortie de la dernière couche et le résultat cible. En réalité, les réseaux de neurones n’ont rien à voir avec les neurones. Il s’agit de calcul différentiable.
Après avoir rédigé l’article “Je comprends enfin comment fonctionne un réseau de neurones”, il s’est rendu compte qu’il ne comprenait toujours pas. La compréhension est une chose relative. Comme Richard Feynman le souligne, personne ne peut être sûr à 100 % de quoi que ce soit, nous ne pouvons qu’être relativement sûrs de quelque chose. Il est donc acceptable que Zhiwei dise cela.
Il a donc trouvé un moyen de comprendre profondément les réseaux de neurones en utilisant une méthode qui consiste à copier plusieurs lignes de code d’exemple à chaque fois, puis à les exécuter et à afficher les variables. Il s’agit d’un simple réseau de neurones pour reconnaître les chiffres manuscrits. Le livre qu’il lit récemment s’intitule Neural Networks and Deep Learning. C’est pourquoi il a donné à son dépôt GitHub le nom Neural Networks and Zhiwei Learning.
Avant d’utiliser un réseau de neurones pour entraîner nos données, nous devons d’abord charger les données. Cette partie lui a coûté une semaine de temps libre pour y parvenir. Les choses prennent toujours plus de temps qu’on ne le pense pour être accomplies. Mais tant que nous n’abandonnons pas, nous sommes capables de réaliser un grand nombre de choses.
Le terme mnist dans le domaine de l’apprentissage automatique fait référence à la base de données Modified National Institute of Standards and Technology. Ainsi, notre fichier de chargement de données est appelé mnist_loader. Nous utilisons la fonction print en Python pour afficher de nombreuses listes et tableaux de type ndarray. Le nd dans ndarray signifie n-dimensionnel.
En plus de print, nous devons utiliser la bibliothèque matplotlib pour afficher nos chiffres. Comme ci-dessous.
Art
Voyons plus de chiffres.

C’est plus joyeux quand on peut parfois voir des images au lieu de faire face à des codes bruyants toute la journée.
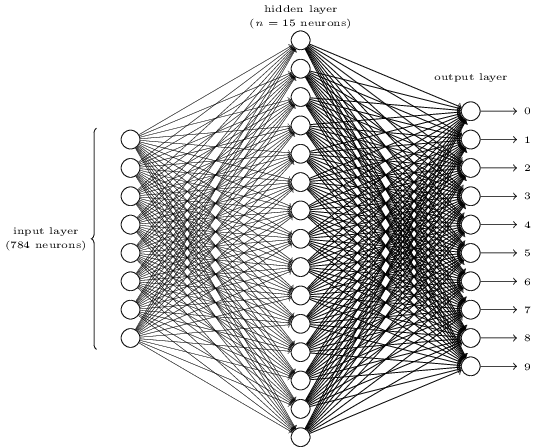
Cela semble compliqué ? Ici, nous avons peut-être trop de neurones dans chaque couche. Et cela rend les choses obscures. C’est en fait très simple une fois que vous l’avez compris. La première chose à propos de l’image ci-dessus est qu’elle comporte trois couches : la couche d’entrée, la couche cachée et la couche de sortie. Et une couche se connecte à la suivante. Mais comment 784 neurones dans la couche d’entrée peuvent-ils se transformer en 15 neurones dans la deuxième couche ? Et comment 15 neurones dans la couche cachée peuvent-ils se transformer en 10 neurones dans la couche de sortie ?
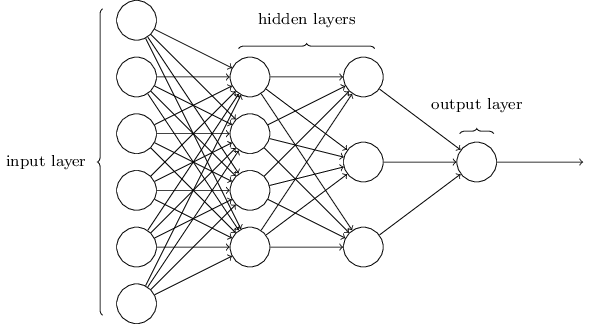
</div>
Ce réseau est beaucoup plus simple. Bien que Zhiwei ne souhaite pas inclure de formules mathématiques dans cet article, ici les mathématiques sont trop simples et belles pour être cachées.
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\]Supposons que nous indiquions le réseau comme ci-dessous.
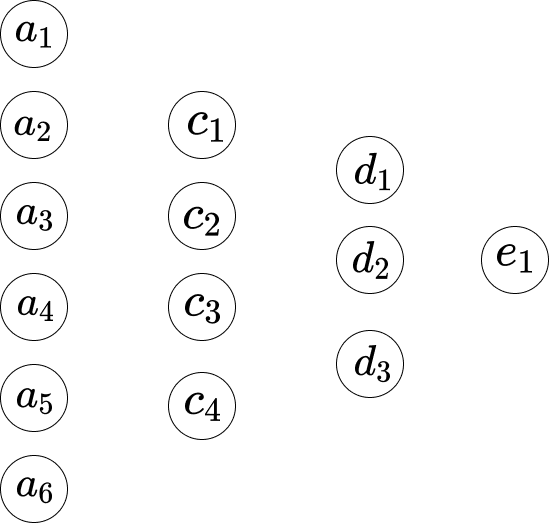
Donc, entre la première couche et la deuxième couche, nous avons les équations suivantes.
\[\begin{eqnarray} w_1*a_1 +...+ w_6*a_6+b_1 = c_1 \\ w_1*a_1 +...+ w_6*a_6+b_2 = c_2 \\ w_1*a_1 +...+ w_6*a_6+b_3 = c_3 \\ w_1*a_1 +...+ w_6*a_6+b_4 = c_4 \end{eqnarray}\]Ici, l’équation 1 possède un ensemble de poids, et l’équation 2 en possède un autre. Ainsi, le $w_1$ dans l’équation 1 est différent du $w_1$ dans l’équation 2. Par conséquent, entre la deuxième couche et la troisième couche, nous avons les équations suivantes.
\[\begin{eqnarray} w_1*c_1 + ... + w_4*c_4+b_1 = d_1 \\ w_1*c_1 + ... + w_4*c_4+b_2 = d_2 \\ w_1*c_1 + ... + w_4*c_4+b_3 = d_3 \end{eqnarray}\]Et dans la troisième couche jusqu’à la dernière couche, nous avons les équations suivantes.
\[w_1*d_1 + w_2*d_2 + w_3*d_3 + b_1 = e_1\]Le problème avec les équations ci-dessus est que la valeur n’est pas assez simple ou formelle. La plage des valeurs de la multiplication et de l’addition est assez large. Nous souhaitons qu’elle soit contrainte dans une petite plage, par exemple, de 0 à 1. C’est ici qu’intervient la fonction Sigmoïde.
\[\sigma(z) \equiv \frac{1}{1+e^{-z}}\]Nous n’avons pas besoin d’être intimidés par le symbole sigma $\sigma$. Ce n’est qu’un symbole, tout comme le symbole a. Si nous lui donnons l’entrée 0.5, sa valeur est
\[\frac{1}{1+e^{-0.5}} \approx 0.622459\]Et,
\[\begin{eqnarray} \frac{1}{1+e^{-(-100)}} \approx 3.72*e^{-44} \\ \frac{1}{1+e^{-(-10)}} \approx 0.000045 \\ \frac{1}{1+e^{-(-1)}} \approx 0.26894 \\ \frac{1}{1+e^{-{0}}} = 0.5 \\ \frac{1}{1+e^{-10}} \approx 0.99995 \\ \frac{1}{1+e^{-100}} = 1 \end{eqnarray}\]C’est intriguant ici. Je ne connaissais pas ce qui précède avant d’écrire cet article. Maintenant, j’ai une idée de la valeur approximative du résultat pour une entrée normale. Et nous observons que pour une entrée allant de 0 à $\infty$, sa valeur est comprise entre 0,5 et 1, et pour une entrée allant de $-\infty$ à 0, sa valeur est comprise entre 0 et 0,5.
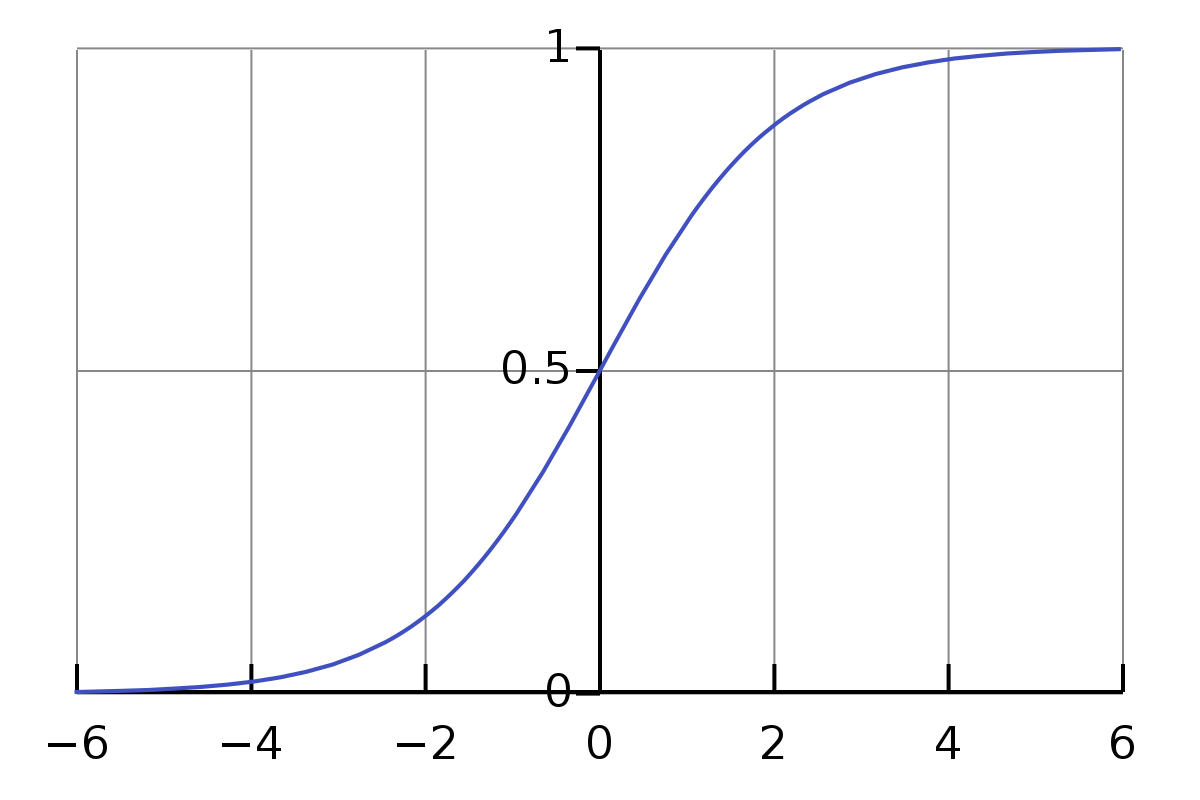
Concernant les équations ci-dessus, elles ne sont pas exactes. Les plus appropriées devraient être les suivantes :
\[\begin{eqnarray} \sigma(w_1*a_1 + ... + w_6*a_6+b_1) = c_1 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_2) = c_2 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_3) = c_3 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_4) = c_4 \end{eqnarray}\]Donc, pour la première équation, c’est que,
\[\frac{1}{1+e^{-(w_1*a_1 +...+ w_6*a_6+b_1)}}\]Comment pouvons-nous mettre à jour le nouveau poids pour $w_1$ ? C’est-à-dire,
\[w_1 \rightarrow w_1' = w_1 - \Delta w\]À l’équation,
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\]Sa dérivée par rapport à $w_1$ est $a_1$. Donnons un symbole $S_1$ à cette somme.
Alors,
\[\frac{\partial S_1}{\partial w_1} = a_1 , \frac{\partial S_1}{\partial w_2} = a_2, ...\]La dérivée représente le taux de changement. Cela signifie que pour un changement $\Delta w$ dans $w_1$, le changement correspondant dans le résultat $S_1$ est $a_1 * \Delta w$. Mais comment pouvons-nous inverser un tel calcul ? Calculons-le.
\[\begin{eqnarray} S_1' - S_1 = \Delta S_1 \\ \frac{\Delta S_1}{a_1} = \Delta w \\ w_1- \Delta w = w_1' \end{eqnarray}\]Et la règle de la chaîne explique que la dérivée de $f(g(x))$ est $f’(g(x))⋅g’(x)$.
Alors ici,
\[\begin{eqnarray} f(z) = \sigma(z) = \frac{1}{1+e^{-z}} \\ g(x) = w_1*a_1 +...+ w_6*a_6+b_1 \end{eqnarray}\]Et la dérivée de la fonction sigmoïde est,
\[\sigma'(z) = \frac{\sigma(z)}{1-\sigma(z)}\]Ainsi, la dérivée de $f(g(w_1))$ est $\frac{\sigma(z)}{1-\sigma(z)} * a_1$.
Alors,
\[\begin{eqnarray} \frac{\sigma(z)}{1-\sigma(z)} * a_1 * \Delta w = \Delta C \\ \Delta w = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)} * a_1} \end{eqnarray}\]Et pour le biais $b_1$,
\[\begin{eqnarray} g'(b_1) = 1 \\ \frac{\sigma(z)}{1-\sigma(z)} * \Delta b = \Delta C \\ \Delta b = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)}} \end{eqnarray}\]Code
La manière d’afficher les variables est très utile et simple, bien qu’aujourd’hui les gens aient inventé Jupyter Notebook pour faire ce genre de choses. Comme Zhiwei l’a mentionné précédemment, l’une des clés pour comprendre les réseaux de neurones est de prêter attention aux dimensions.
def print_shape(array):
arr = np.array(array)
print(arr.shape)
print(len(test_data[0][0])) # 10
print_shape(training_results[0]) # (784, 1)
print(list(training_data)[0:1]) # <class 'list'>
Maintenant que Zhiwei vient de terminer la partie chargement des données, il va continuer à utiliser la même méthode consistant à copier plusieurs lignes et à imprimer des variables pour apprendre la partie réelle du réseau de neurones. Vous pouvez suivre les progrès ici : https://github.com/lzwjava/neural-networks-and-zhiwei-learning.
Je me suis retrouvé bloqué à plusieurs reprises au cours de ce processus. Même si le code semble très simple, après avoir essayé de le comprendre à plusieurs reprises, j’ai échoué. Ensuite, je me suis éloigné de la ligne de code actuelle pour l’examiner d’un point de vue plus global, en réfléchissant à la raison pour laquelle l’auteur a écrit cette partie du code. Et soudain, j’ai compris. Le code est ci-dessous.
def load_data_wrapper():
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e
Ici, les dimensions des variables sont complexes. Cependant, lorsque nous réfléchissons à l’initiative de l’auteur, nous obtenons quelques indices. Regardez, le code est composé de trois parties similaires. Et chaque partie est presque la même, bien que les noms des variables soient différents. Maintenant, cela me semble très confortable. Le zip, l’opération for sur la liste, et la fonction reshape. La compréhension s’accumule simplement après des centaines de fois où j’ai imprimé les variables et essayé de comprendre pourquoi les valeurs des variables étaient ainsi.
Et Zhiwei trouve toujours les erreurs très précieuses. Comme dans le code ci-dessous, il rencontre de nombreuses erreurs, par exemple,
- TypeError: Forme invalide (784,) pour les données d’image
- ValueError: définition d’un élément de tableau avec une séquence. Le tableau demandé a une forme inhomogène après 2 dimensions. La forme détectée était (1, 2) + partie inhomogène.
La trace de la pile d’erreurs est comme un magnifique poème.
De plus, lorsque nous formatons la sortie des valeurs dans Visual Studio Code, elle devient beaucoup plus lisible.
[array([[0.92733598],
[0.01054299],
[1.0195613],
...
[0.67045368],
[-0.29942482],
[-0.35010666]]),
array([[-1.87093344],
[-0.18758503],
[1.35792778],
...
[0.36830578],
[0.61671649],
[0.67084213]])]
Merci d’avoir lu. Thank you for your reading.
Remarque : Certaines images sont extraites du livre “Neural Networks and Deep Learning”.