禪與機器學習的藝術 | 原創,AI翻譯
禪
一個年輕的爸爸週末忙著學習神經網絡。然而,這個週末,他需要陪他的小女兒在公寓的游泳池裡游泳。他躺在淺水中,看著高聳入雲的公寓大樓。突然間,他想到,哇,它們真的很像神經網絡。每個陽台就像一個神經元。一棟大樓就像一層神經元。而一群大樓組合起來就形成了一個神經網絡。
接著,他想到了反向傳播。反向傳播的作用是將誤差傳播回神經元。在一次訓練結束時,算法會計算最後一層輸出與目標結果之間的誤差。實際上,神經網絡與神經元無關。它關乎的是可微分的計算。
在寫完《我終於理解神經網絡如何運作》這篇文章後,他發現自己仍然沒有完全理解。理解是相對的。正如理查德·費曼所指出的那樣,沒有人能對任何事情百分之百確定,我們只能相對確定某些事情。所以志偉這樣說是可以接受的。
於是,他找到了一種深入理解神經網絡的方法,即每次複製幾行示例代碼,然後運行並打印變量。這是一個用於識別手寫數字的簡單神經網絡。他最近讀的書名為《神經網絡與深度學習》。因此,他將自己的GitHub倉庫命名為《神經網絡與志偉學習》。
在我們使用神經網絡訓練數據之前,首先需要加載數據。這部分花了他一週的閒暇時間來完成。事情總是需要更多的時間來完成。但只要我們不放棄,我們就能做很多事情。
機器學習領域中的mnist代表的是修改後的國家標準與技術研究院數據庫。所以我們的數據加載文件叫做minst_loader。我們使用Python中的print函數來打印大量的列表和ndarray數組。ndarray中的nd代表n維。
除了打印,我們還必須使用matplotlib庫來顯示我們的數字。如下所示。
藝術
讓我們看更多的數字。

有時候看到圖片比整天面對嘈雜的代碼更讓人愉悅。
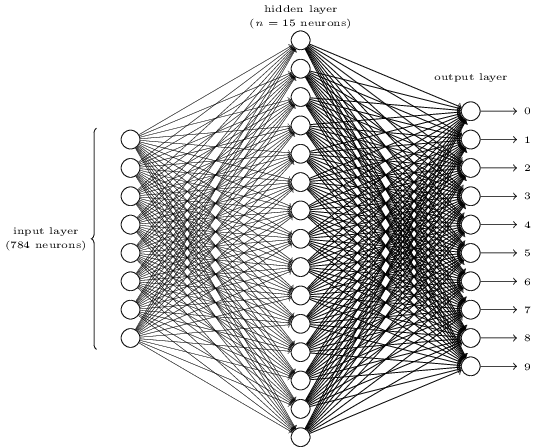
看起來很複雜嗎?這裡,我們可能每層有太多的神經元。這使得事情變得模糊。一旦你理解了,它其實非常簡單。關於上圖的第一件事是它有三層,輸入層、隱藏層和輸出層。一層連接到下一層。但是輸入層的784個神經元如何變成第二層的15個神經元?隱藏層的15個神經元如何變成輸出層的10個神經元?
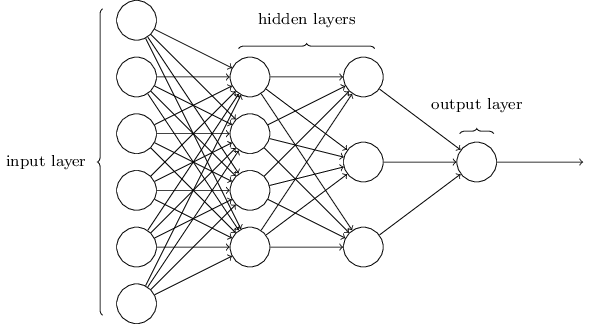
這個網絡要簡單得多。雖然志偉不想在這篇文章中包含任何數學公式,但這裡的數學太簡單和美麗,無法隱藏。
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\]假設我們如下表示網絡。
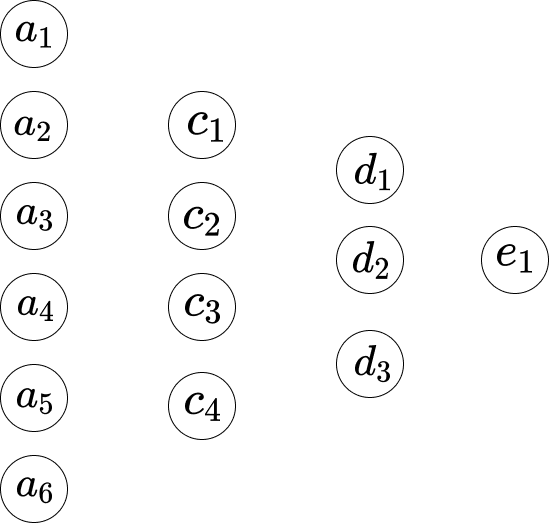
所以,在第一層和第二層之間,我們有以下方程。
\[\begin{eqnarray} w_1*a_1 +...+ w_6*a_6+b_1 = c_1 \\ w_1*a_1 +...+ w_6*a_6+b_2 = c_2 \\ w_1*a_1 +...+ w_6*a_6+b_3 = c_3 \\ w_1*a_1 +...+ w_6*a_6+b_4 = c_4 \end{eqnarray}\]這裡,方程1有一組權重,方程2有另一組權重。所以方程1中的$w_1$與方程2中的$w_1$不同。在第二層和第三層之間,我們有以下方程。
\[\begin{eqnarray} w_1*c_1 + ... + w_4*c_4+b_1 = d_1 \\ w_1*c_1 + ... + w_4*c_4+b_2 = d_2 \\ w_1*c_1 + ... + w_4*c_4+b_3 = d_3 \end{eqnarray}\]在第三層到最後一層,我們有以下方程。
\[w_1*d_1 + w_2*d_2+ w_3*d_3+ b_1 = e_1\]上述方程的一個問題是,值的範圍不夠簡單或正式。乘法和加法的值範圍相當大。我們希望它約束在一個小範圍內,比如0到1。所以這裡,我們有Sigmoid函數。
\[\sigma(z) \equiv \frac{1}{1+e^{-z}}\]我們不需要被符號$\sigma$嚇到。它只是一個符號,就像符號a一樣。如果我們給它輸入0.5,它的值是
\[\frac{1}{1+e^{-0.5}} \approx 0.622459\]並且,
\[\begin{eqnarray} \frac{1}{1+e^{-(-100)}} \approx 3.72*e^{-44} \\ \frac{1}{1+e^{-(-10)}} \approx 0.000045 \\ \frac{1}{1+e^{-(-1)}} \approx 0.26894 \\ \frac{1}{1+e^{-{0}}} = 0.5 \\ \frac{1}{1+e^{-10}} \approx 0.99995 \\ \frac{1}{1+e^{-100}} = 1 \end{eqnarray}\]這裡很有趣。在寫這篇文章之前,我不知道上面的內容。現在,我對它的正常輸入的近似結果值有了一些感覺。我們觀察到,對於從0到$\infty$的輸入,它的值是從0.5到1,而對於從$-\infty$到0的輸入,它的值是從0到0.5。
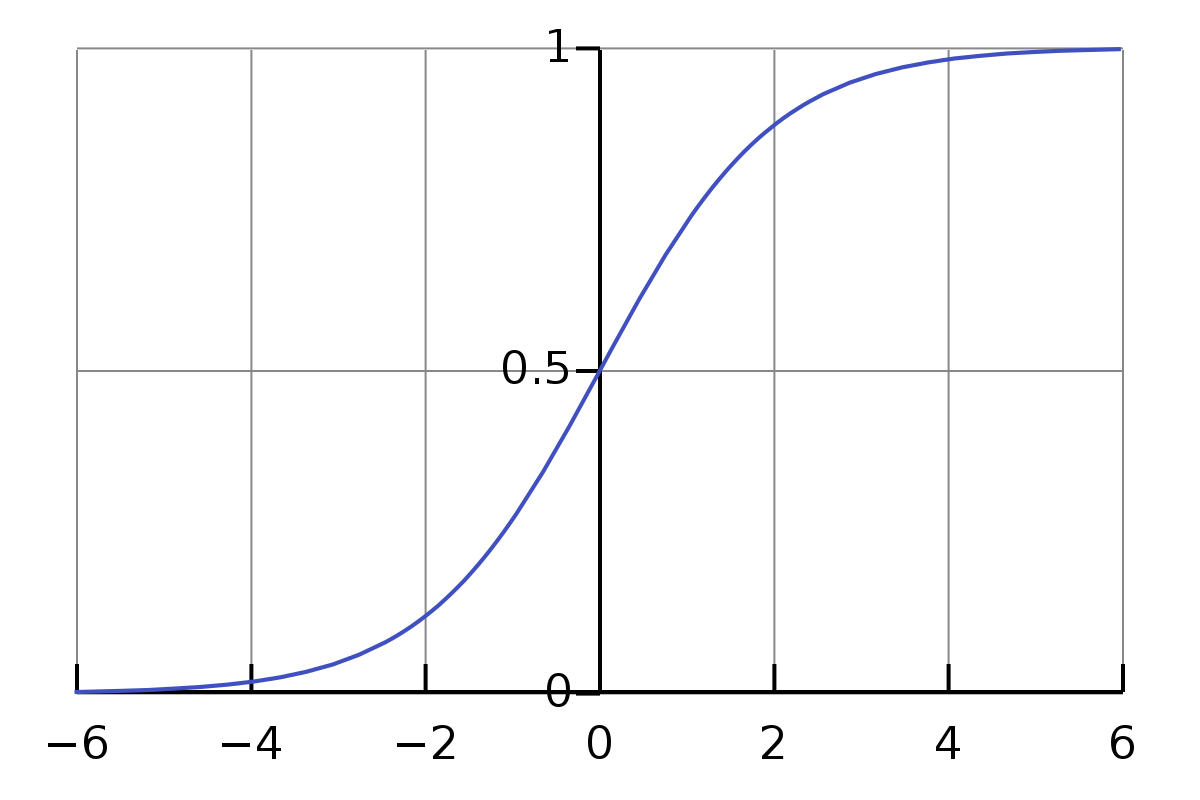
所以關於上述方程,它們並不準確。最合適的應該是如下。
\[\begin{eqnarray} \sigma(w_1*a_1 + ... + w_6*a_6+b_1) = c_1 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_2) = c_2 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_3) = c_3 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_4) = c_4 \end{eqnarray}\]所以對於第一個方程,它是,
\[\frac{1}{1+e^{-(w_1*a_1 +...+ w_6*a_6+b_1)}}\]我們如何更新$w_1$的新權重?即,
\[w_1 \rightarrow w_1' = w_1- \Delta w\]對於方程,
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\]它對$w_1$的導數是$a_1$。讓我們給這個和一個符號$S_1$。
所以,
\[\frac{\partial S_1}{\partial w_1} = a_1 , \frac{\partial S_1}{\partial w_2} = a_2, ...\]導數意味著變化率。這意味著對於$w_1$的變化$\Delta w$,結果$S_1$的變化是$a_1 * \Delta w$。我們如何反轉這樣的計算?讓我們計算一下。
\[\begin{eqnarray} S_1' - S_1 = \Delta S_1 \\ \frac{\Delta S_1}{a_1} = \Delta w \\ w_1- \Delta w = w_1' \end{eqnarray}\]鏈式法則解釋了$f(g(x))$的導數是$f’(g(x))⋅g’(x)$。
所以在這裡,
\[\begin{eqnarray} f(z) = \sigma(z) = \frac{1}{1+e^{-z}} \\ g(x) = w_1*a_1 +...+ w_6*a_6+b_1 \end{eqnarray}\]Sigmoid函數的導數是,
\[\sigma'(z) = \frac{\sigma(z)}{1-\sigma(z)}\]所以$f(g(w_1))$的導數是$\frac{\sigma(z)}{1-\sigma(z)} * a_1$。
所以,
\[\begin{eqnarray} \frac{\sigma(z)}{1-\sigma(z)} * a_1 * \Delta w = \Delta C \\ \Delta w = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)} * a_1} \end{eqnarray}\]對於偏置$b_1$,
\[\begin{eqnarray} g'(b_1) = 1 \\ \frac{\sigma(z)}{1-\sigma(z)} * \Delta b = \Delta C \\ \Delta b = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)}} \end{eqnarray}\]代碼
打印變量的方法非常有用且簡單,儘管現在人們發明了Jupyter Notebook來做這樣的事情。正如志偉之前提到的,理解神經網絡的關鍵之一是我們應該注意維度。
def print_shape(array):
arr = np.array(array)
print(arr.shape)
print(len(test_data[0][0])) # 10
print_shape(training_results[0]) # (784, 1)
print(list(training_data)[0:1]) # <class 'list'>
由於志偉剛剛完成了加載數據的部分,他將繼續使用複製幾行並打印變量的方式來學習神經網絡的實際部分。你可以在此處跟進進度,https://github.com/lzwjava/neural-networks-and-zhiwei-learning。
我在進度中卡住了幾次。即使代碼看起來非常簡單,經過一次又一次地嘗試理解它,我還是失敗了。然後我把自己從當前的代碼行中抽離出來,從更高的層次來看它,思考作者為什麼寫那部分代碼,突然間我明白了。代碼如下。
def load_data_wrapper():
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e
這裡,變量的維度很複雜。然而,當我們思考作者的初衷時,我們就有了一些線索。看,代碼由三個相似的部分組成。每個部分幾乎相同,儘管變量的名稱不同。現在,對我來說,它看起來非常舒服。zip,對列表的“for”操作,以及reshape函數。理解就在數百次打印變量和嘗試弄清楚變量的值為什麼是這樣的過程中積累起來。
志偉總是發現錯誤非常有價值。如下面的代碼,他遇到了很多錯誤,例如,
- TypeError: Invalid shape (784,) for image data
- ValueError: setting an array element with a sequence. The requested array has an inhomogeneous shape after 2 dimensions. The detected shape was (1, 2) + inhomogeneous part.
錯誤堆棧跟踪就像一首美麗的詩。
此外,當我們在Visual Studio Code中格式化值輸出時,它更具可讀性。
[array([[0.92733598],
[0.01054299],
[1.0195613],
...
[0.67045368],
[-0.29942482],
[-0.35010666]]),
array([[-1.87093344],
[-0.18758503],
[1.35792778],
...
[0.36830578],
[0.61671649],
[0.67084213]])]
読んでくれてありがとう. 謝謝你的閱讀。
註:部分圖片來自《神經網絡與深度學習》一書。