ज़ेन और मशीन लर्निंग की कला | मूल, AI द्वारा अनुवादित
ज़ेन
एक युवा पिता सप्ताहांत में न्यूरल नेटवर्क सीखने में व्यस्त है। हालांकि, इस सप्ताहांत, उसे अपनी छोटी बेटी को अपार्टमेंट कॉम्प्लेक्स के पूल में तैरने के लिए साथ ले जाना था। वह उथले पानी में लेट गया और ऊपर की ओर उठती हुई ऊंची इमारतों को देखने लगा। और अचानक उसने सोचा, वाह, वे न्यूरल नेटवर्क की तरह ही हैं। हर बालकनी एक न्यूरॉन की तरह है। और एक इमारत न्यूरॉन्स की एक परत की तरह है। और इमारतों का एक समूह मिलकर एक न्यूरल नेटवर्क बनाता है।
फिर उसने बैकप्रोपेगेशन के बारे में सोचा। बैकप्रोपेगेशन क्या करता है कि यह त्रुटियों को न्यूरॉन्स तक वापस भेजता है। एक बार के प्रशिक्षण के अंत में, एल्गोरिदम अंतिम परत के आउटपुट और लक्ष्य परिणाम के बीच की त्रुटि की गणना करता है। वास्तव में, न्यूरल नेटवर्क का न्यूरॉन्स से कोई लेना-देना नहीं है। यह अवकलनीय कंप्यूटिंग के बारे में है।
लेख “मैं आखिरकार समझ गया कि न्यूरल नेटवर्क कैसे काम करता है” लिखने के बाद, उन्होंने पाया कि वे अभी भी समझ नहीं पाए। समझ एक सापेक्ष चीज़ है। जैसा कि रिचर्ड फेनमैन ने कहा है, कोई भी किसी चीज़ के बारे में 100% निश्चित नहीं हो सकता, हम केवल किसी चीज़ के बारे में सापेक्ष रूप से निश्चित हो सकते हैं। इसलिए, झिवेई का ऐसा कहना स्वीकार्य है।
इसलिए उसने न्यूरल नेटवर्क्स को गहराई से समझने का एक तरीका निकाला, जिसमें वह हर बार कुछ उदाहरण कोड की लाइनों को कॉपी करता, फिर उसे चलाता और वेरिएबल्स को प्रिंट करता। यह हस्तलिखित अंकों को पहचानने वाले सरल न्यूरल नेटवर्क के बारे में है। जो किताब वह हाल ही में पढ़ रहा है, उसका शीर्षक है Neural Networks and Deep Learning। इसलिए उसने अपने GitHub रिपॉजिटरी का नाम Neural Networks and Zhiwei Learning रखा।
Neural Network का उपयोग करने से पहले, हमें अपने डेटा को प्रशिक्षित करने के लिए डेटा को लोड करने की आवश्यकता होती है। इस भाग को पूरा करने में उन्हें एक सप्ताह का अवकाश समय लगा। चीजों को पूरा करने में हमेशा अधिक समय लगता है। लेकिन जब तक हम हार नहीं मानते, हम बहुत सी चीजें करने में सक्षम होते हैं।
मशीन लर्निंग क्षेत्र में mnist का मतलब Modified National Institute of Standards and Technology डेटाबेस है। इसलिए हमारा डेटा लोडर फ़ाइल को mnist_loader कहा जाता है। हम Python में print फ़ंक्शन का उपयोग करके बहुत सारे सूचियों और ndarray के arrays को प्रिंट करते हैं। ndarray में nd का मतलब n-dimensional (एन-डायमेंशनल) होता है।
print के अलावा, हमें अपने अंकों को दिखाने के लिए matplotlib लाइब्रेरी का उपयोग करना चाहिए। जैसा कि नीचे दिखाया गया है।
कला
आइए और अंक देखें।

यह और भी ज्यादा खुशी की बात होती है जब आप कभी-कभी शोरगुल भरे कोड के बजाय तस्वीरें देख सकते हैं।
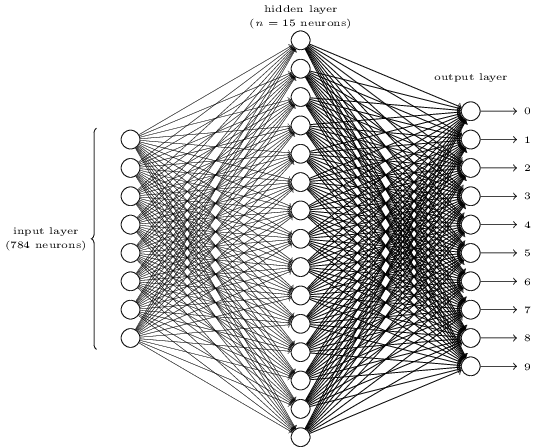
क्या यह जटिल लगता है? यहाँ, हमारे पास प्रत्येक परत में बहुत सारे न्यूरॉन्स हो सकते हैं। और यह चीजों को अस्पष्ट बना देता है। इसे समझने के बाद यह वास्तव में बहुत सरल है। उपरोक्त चित्र के बारे में पहली बात यह है कि इसमें तीन परतें हैं, इनपुट परत, छिपी हुई परत और आउटपुट परत। और एक परत अगली परत से जुड़ती है। लेकिन इनपुट परत में 784 न्यूरॉन्स दूसरी परत में 15 न्यूरॉन्स में कैसे बदल सकते हैं? और छिपी हुई परत में 15 न्यूरॉन्स आउटपुट परत में 10 न्यूरॉन्स में कैसे बदल सकते हैं?
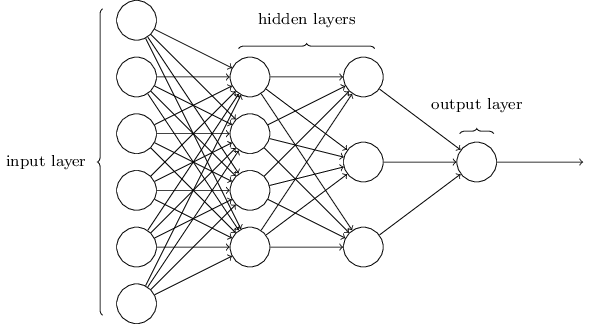
</div>
यह नेटवर्क बहुत सरल है। हालांकि झिवेई इस लेख में कोई गणितीय सूत्र शामिल नहीं करना चाहते हैं, यहाँ गणित इतना सरल और सुंदर है कि इसे छुपाना संभव नहीं है।
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\](यह एक गणितीय समीकरण है, इसलिए इसे अनुवादित करने की आवश्यकता नहीं है।)
मान लीजिए कि हम नेटवर्क को नीचे दिखाए गए तरीके से इंगित करते हैं।
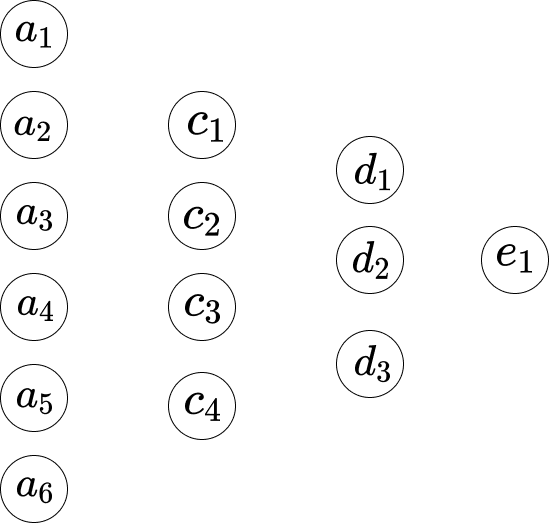
पहली परत और दूसरी परत के बीच, हमारे पास निम्नलिखित समीकरण हैं।
\[\begin{eqnarray} w_1*a_1 +...+ w_6*a_6+b_1 = c_1 \\ w_1*a_1 +...+ w_6*a_6+b_2 = c_2 \\ w_1*a_1 +...+ w_6*a_6+b_3 = c_3 \\ w_1*a_1 +...+ w_6*a_6+b_4 = c_4 \end{eqnarray}\]यहां, समीकरण 1 में वज़नों का एक समूह सेट है, और समीकरण 2 में वज़नों का एक और समूह सेट है। इसलिए समीकरण 1 में $w_1$ समीकरण 2 में $w_1$ से अलग है। और इसलिए दूसरी परत और तीसरी परत के बीच, हमारे पास निम्नलिखित समीकरण हैं।
\[\begin{eqnarray} w_1*c_1 + ... + w_4*c_4+b_1 = d_1 \\ w_1*c_1 + ... + w_4*c_4+b_2 = d_2 \\ w_1*c_1 + ... + w_4*c_4+b_3 = d_3 \end{eqnarray}\]और तीसरी परत से अंतिम परत तक, हमारे पास निम्नलिखित समीकरण हैं।
\[w_1*d_1 + w_2*d_2+ w_3*d_3+ b_1 = e_1\](यह एक गणितीय समीकरण है, जिसे हिंदी में अनुवाद करने की आवश्यकता नहीं है।)
उपरोक्त समीकरणों में एक समस्या यह है कि मान पर्याप्त सरल या औपचारिक नहीं है। गुणा और जोड़ के मान की सीमा काफी बड़ी है। हम चाहते हैं कि यह एक छोटी सीमा में सीमित हो, जैसे, 0 से 1 तक। इसलिए यहां, हमारे पास सिग्मॉइड फ़ंक्शन है।
\[\sigma(z) \equiv \frac{1}{1+e^{-z}}\]इस समीकरण को सिग्मॉइड फ़ंक्शन (sigmoid function) कहा जाता है। यह एक गैर-रेखीय फ़ंक्शन है जो किसी भी वास्तविक संख्या ( z ) को 0 और 1 के बीच की एक मान में परिवर्तित करता है। यह फ़ंक्शन मशीन लर्निंग और न्यूरल नेटवर्क्स में व्यापक रूप से उपयोग किया जाता है, विशेष रूप से लॉजिस्टिक रिग्रेशन और एक्टिवेशन फ़ंक्शन के रूप में।
हमें सिग्मा प्रतीक $\sigma$ से डरने की जरूरत नहीं है। यह सिर्फ एक प्रतीक है, ठीक वैसे ही जैसे प्रतीक a। अगर हम इसे इनपुट के रूप में 0.5 दें, तो इसका मान होगा।
\[\frac{1}{1+e^{-0.5}} \approx 0.622459\]और,
\[\begin{eqnarray} \frac{1}{1+e^{-(-100)}} \approx 3.72*e^{-44} \\ \frac{1}{1+e^{-(-10)}} \approx 0.000045 \\ \frac{1}{1+e^{-(-1)}} \approx 0.26894 \\ \frac{1}{1+e^{-{0}}} = 0.5 \\ \frac{1}{1+e^{-10}} \approx 0.99995 \\ \frac{1}{1+e^{-100}} = 1 \end{eqnarray}\]यहाँ यह दिलचस्प है। मुझे इस लेख को लिखने से पहले उपरोक्त बातें नहीं पता थीं। अब, मुझे इसके सामान्य इनपुट के लिए अनुमानित परिणाम मूल्य के बारे में एक अहसास हो गया है। और हम देखते हैं कि 0 से $\infty$ तक के इनपुट के लिए, इसका मान 0.5 से 1 तक होता है, और $-\infty$ से 0 तक के इनपुट के लिए, इसका मान 0 से 0.5 तक होता है।
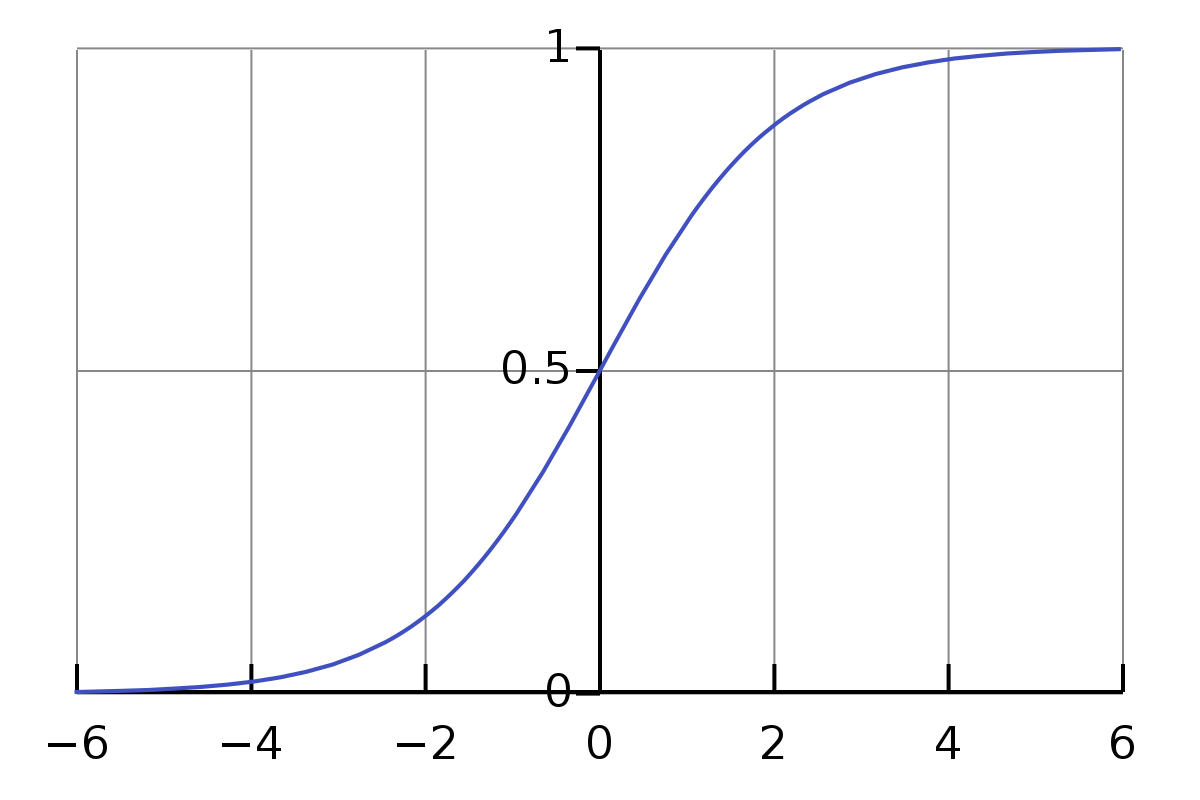
तो उपरोक्त समीकरणों के संबंध में, वे सटीक नहीं हैं। सबसे उचित समीकरण नीचे दिए गए होने चाहिए।
\[\begin{eqnarray} \sigma(w_1*a_1 + ... + w_6*a_6+b_1) = c_1 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_2) = c_2 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_3) = c_3 \\ \sigma(w_1*a_1 + ... + w_6*a_6+b_4) = c_4 \end{eqnarray}\](यह गणितीय समीकरण है, इसलिए इसे अनुवादित नहीं किया गया है।)
तो पहले समीकरण के लिए, यह है कि,
\[\frac{1}{1+e^{-(w_1*a_1 +...+ w_6*a_6+b_1)}}\]इस सूत्र को हिंदी में समझाया जाए तो यह एक सिग्मॉइड फ़ंक्शन (Sigmoid Function) का उदाहरण है, जो कृत्रिम तंत्रिका नेटवर्क (Artificial Neural Networks) में उपयोग किया जाता है। यह फ़ंक्शन इनपुट मानों को 0 और 1 के बीच की संख्या में परिवर्तित करता है।
- ( w_1, w_2, …, w_6 ) वज़न (weights) हैं, जो इनपुट मानों ( a_1, a_2, …, a_6 ) के साथ गुणा होते हैं।
- ( b_1 ) एक बायस (bias) है, जो फ़ंक्शन को स्थानांतरित करने में मदद करता है।
- ( e ) प्राकृतिक लघुगणक का आधार है, जो लगभग 2.71828 के बराबर होता है।
यह सूत्र मशीन लर्निंग में बाइनरी क्लासिफिकेशन (Binary Classification) के लिए उपयोगी है, जहां हमें यह निर्धारित करना होता है कि कोई इनपुट किसी विशेष श्रेणी में आता है या नहीं।
हम $w_1$ के लिए नया वजन कैसे अपडेट कर सकते हैं? यानी,
\[w_1 \rightarrow w_1' = w_1- \Delta w\]इस समीकरण में, ( w_1 ) को अपडेट करके ( w_1’ ) प्राप्त किया जाता है, जहां ( \Delta w ) ( w_1 ) में किया गया परिवर्तन है।
समीकरण में,
\[w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1\]इसका $w_1$ के सापेक्ष अवकलज $a_1$ है। आइए इस योग को एक प्रतीक $S_1$ दें।
तो,
\[\frac{\partial S_1}{\partial w_1} = a_1 , \frac{\partial S_1}{\partial w_2} = a_2, ...\]डेरिवेटिव का अर्थ है परिवर्तन की दर। इसका मतलब है कि $w_1$ में $\Delta w$ के परिवर्तन के लिए, परिणाम $S_1$ में इसका परिवर्तन $a_1 * \Delta w$ होगा। और हम ऐसी गणना को कैसे उलट सकते हैं? आइए इसकी गणना करें।
\[\begin{eqnarray} S_1' - S_1 = \Delta S_1 \\ \frac{\Delta S_1}{a_1} = \Delta w \\ w_1- \Delta w = w_1' \end{eqnarray}\]और चेन रूल यह समझाता है कि $f(g(x))$ का व्युत्पन्न $f’(g(x))⋅g’(x)$ होता है।
तो यहाँ,
\[\begin{eqnarray} f(z) = \sigma(z) = \frac{1}{1+e^{-z}} \\ g(x) = w_1*a_1 +...+ w_6*a_6+b_1 \end{eqnarray}\]और सिग्मॉइड फ़ंक्शन का व्युत्पन्न है,
\[\sigma'(z) = \frac{\sigma(z)}{1-\sigma(z)}\]इसलिए $f(g(w_1))$ का व्युत्पन्न $\frac{\sigma(z)}{1-\sigma(z)} * a_1$ है।
तो,
\[\begin{eqnarray} \frac{\sigma(z)}{1-\sigma(z)} * a_1 * \Delta w = \Delta C \\ \Delta w = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)} * a_1} \end{eqnarray}\]और पूर्वाग्रह $b_1$ के लिए,
\[\begin{eqnarray} g'(b_1) = 1 \\ \frac{\sigma(z)}{1-\sigma(z)} * \Delta b = \Delta C \\ \Delta b = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)}} \end{eqnarray}\]कोड
चर (variables) को प्रिंट करने का तरीका बहुत उपयोगी और सरल है, हालांकि आजकल लोग ऐसे कामों के लिए Jupyter Notebook का आविष्कार कर चुके हैं। जैसा कि Zhiwei ने पहले बताया है, न्यूरल नेटवर्क को समझने के लिए एक महत्वपूर्ण बिंदु यह है कि हमें आयामों (dimensions) पर ध्यान देना चाहिए।
def print_shape(array):
arr = np.array(array)
print(arr.shape)
print(len(test_data[0][0])) # 10
print_shape(training_results[0]) # (784, 1)
print(list(training_data)[0:1]) # <class 'list'>
(नोट: कोड ब्लॉक को अनुवादित नहीं किया जाता है क्योंकि यह प्रोग्रामिंग भाषा में लिखा गया है और इसे बदलने की आवश्यकता नहीं है।)
अब जबकि Zhiwei ने डेटा लोड करने का हिस्सा पूरा कर लिया है, वह न्यूरल नेटवर्क के वास्तविक हिस्से को सीखने के लिए कई लाइनें कॉपी करने और वेरिएबल्स प्रिंट करने के उसी तरीके का उपयोग करना जारी रखेगा। आप यहां प्रगति का अनुसरण कर सकते हैं, https://github.com/lzwjava/neural-networks-and-zhiwei-learning।
मैं प्रगति में कई बार फंस गया। हालांकि यह कोड बहुत सरल लगता है, लेकिन इसे समझने के लिए बार-बार प्रयास करने के बाद भी मैं असफल रहा। फिर मैंने खुद को कोड की वर्तमान लाइन से बाहर निकालकर इसे एक उच्च स्तर से देखने की कोशिश की, यह सोचने के लिए कि लेखक ने कोड का वह हिस्सा क्यों लिखा है, और तभी अचानक मुझे समझ आ गया। कोड नीचे दिया गया है।
def load_data_wrapper():
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
यह कोड निम्नलिखित कार्य करता है:
training_inputsमें,tr_d[0]के प्रत्येक तत्वxको 784 आयामी वेक्टर में बदल दिया जाता है।training_resultsमें,tr_d[1]के प्रत्येक तत्वyकोvectorized_resultफ़ंक्शन के माध्यम से वेक्टराइज़्ड रूप में बदल दिया जाता है।training_dataमें,training_inputsऔरtraining_resultsको जोड़कर एक ज़िप ऑब्जेक्ट बनाया जाता है।
इस प्रकार, training_data में प्रशिक्षण डेटा के इनपुट और उनके संबंधित लेबल शामिल होते हैं।
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
इस कोड में, validation_inputs एक लिस्ट है जिसमें va_d[0] के प्रत्येक एलिमेंट को 784 आयामों वाले वेक्टर में रीशेप किया गया है। फिर validation_data validation_inputs और va_d[1] को जोड़कर बनाया गया है।
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e
यहां, चरों के आयाम जटिल हैं। हालांकि, जब हम लेखक के पहल के बारे में सोचते हैं, तो हमें कुछ संकेत मिलते हैं। इसे देखें, कोड तीन समान भागों से मिलकर बना है। और हर भाग लगभग एक जैसा है, हालांकि चरों के नाम अलग-अलग हैं। अब, यह मुझे बहुत आरामदायक लगता है। zip, सूची के लिए “for” ऑपरेशन, और reshape फ़ंक्शन। समझ सैकड़ों बार चरों को प्रिंट करने और यह पता लगाने की कोशिश करने के बीच बस जमा हो जाती है कि चरों के मान ऐसे क्यों हैं।
और झिवेई हमेशा त्रुटियों को बहुत मूल्यवान मानते हैं। जैसे नीचे दिए गए कोड में, उन्हें कई त्रुटियों का सामना करना पड़ता है, उदाहरण के लिए,
- TypeError: अमान्य आकार (784,) छवि डेटा के लिए
- ValueError: एक सरणी तत्व को एक अनुक्रम के साथ सेट करने में त्रुटि। अनुरोधित सरणी का आकार 2 आयामों के बाद असमान है। पता चला आकार (1, 2) + असमान भाग था।
त्रुटि स्टैक ट्रेस एक सुंदर कविता की तरह होती है।
इसके अलावा, जब हम Visual Studio Code में मान आउटपुट को फॉर्मेट करते हैं, तो यह बहुत अधिक पठनीय हो जाता है।
[array([[0.92733598],
[0.01054299],
[1.0195613],
...
[0.67045368],
[-0.29942482],
[-0.35010666]]),
array([[-1.87093344],
[-0.18758503],
[1.35792778],
...
[0.36830578],
[0.61671649],
[0.67084213]])]
पढ़ने के लिए धन्यवाद। Thank you for your reading.
नोट: कुछ चित्र “Neural Networks and Deep Learning” पुस्तक से लिए गए हैं।