Zenと機械学習の技術 | オリジナル、AI翻訳
Zen
週末、若い父親はニューラルネットワークの勉強に忙しい日々を送っていました。しかし、この週末は、アパートのプールで幼い娘と一緒に泳ぐ必要がありました。彼は浅瀬に横たわり、空に向かってそびえ立つ高層アパートを見上げていました。そして突然、彼は思いました。「わあ、これってニューラルネットワークに似てるな」と。すべてのバルコニーはニューロンのようで、一棟の建物はニューロンの層のようです。そして、建物のグループが組み合わさってニューラルネットワークを形成しているように見えたのです。
その後、彼はバックプロパゲーションについて考えました。バックプロパゲーションが行うのは、エラーをニューロンに逆伝播させることです。1回のトレーニングの終わりに、アルゴリズムは最後の層の出力と目標結果との間の誤差を計算します。実際、ニューラルネットワークはニューロンとは何の関係もありません。それは微分可能な計算に関するものです。
「ニューラルネットワークの仕組みをようやく理解した」という記事を書いた後、彼はまだ理解していないことに気づきました。理解とは相対的なものです。リチャード・ファインマンが指摘したように、誰も何かを100%確信することはできず、相対的に確信を持つことしかできません。ですから、Zhiweiがそう言うのは許容範囲内です。
そこで彼は、手書き数字を認識する単純なニューラルネットワークについて、毎回いくつかのサンプルコードをコピーして実行し、変数を出力することで、ニューラルネットワークを深く理解する方法を考え出しました。彼が最近読んでいる本は『Neural Networks and Deep Learning』というタイトルです。そのため、彼は自分のGitHubリポジトリに「Neural Networks and Zhiwei Learning」という名前を付けました。
ニューラルネットワークを使ってデータを訓練する前に、まずデータを読み込む必要があります。この部分に彼は1週間の余暇を費やしました。物事は常に予想以上に時間がかかるものです。しかし、諦めさえしなければ、私たちは非常に多くのことを成し遂げることができるのです。
機械学習の分野における「mnist」は、Modified National Institute of Standards and Technology database(修正版米国国立標準技術研究所データベース)を指します。そのため、私たちのデータローダーファイルは「mnist_loader」と呼ばれています。Pythonのprint関数を使用して、多くのリストやndarrayの配列を出力します。ndarrayの「nd」は、n次元(n-dimensional)を意味します。
printの他に、数字を表示するためにmatplotlibライブラリを使用する必要があります。以下のようにします。
アート
もっと桁数を見てみましょう。

一日中騒がしいコードに囲まれているよりも、時々画像を見ることができる方が、より楽しいものです。
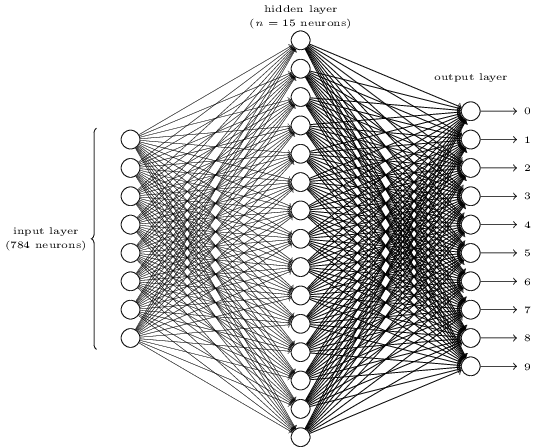
複雑に見えますか?ここでは、各層に多すぎるニューロンがあるかもしれません。そして、それが物事を不明瞭にしています。一度理解してしまえば、実は非常にシンプルです。上の図についての最初のポイントは、入力層、隠れ層、出力層の3つの層があることです。そして、一つの層が次の層に接続しています。しかし、入力層の784個のニューロンがどのようにして第2層の15個のニューロンに変わるのでしょうか?また、隠れ層の15個のニューロンがどのようにして出力層の10個のニューロンに変わるのでしょうか?
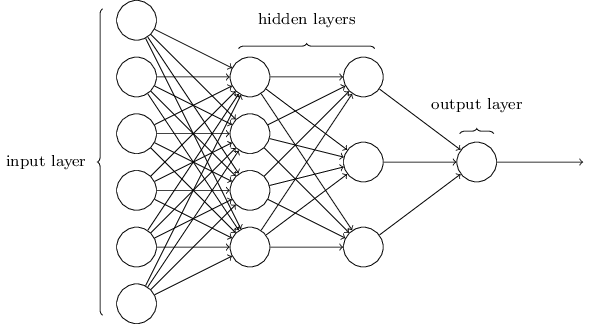
このネットワークは非常にシンプルです。Zhiweiはこの記事に数式を含めたくないと考えていますが、ここでの数学はあまりにも単純で美しいため、隠すには惜しいです。
$$w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1$$
以下のようにネットワークを示すとします。
<div align="center"><img src="/assets/images/zen-neural/network-1.png" width="30%" /><img/></div>
したがって、第1層と第2層の間には以下の方程式が成り立ちます。
$$
\begin{eqnarray}
w_1*a_1 +...+ w_6*a_6+b_1 = c_1 \\
w_1*a_1 +...+ w_6*a_6+b_2 = c_2 \\
w_1*a_1 +...+ w_6*a_6+b_3 = c_3 \\
w_1*a_1 +...+ w_6*a_6+b_4 = c_4
\end{eqnarray}
$$
ここで、式1には一組の重みがあり、式2には別の組の重みがあります。したがって、式1の$w_1$と式2の$w_1$は異なります。そして、第2層と第3層の間には、以下の式が成り立ちます。
$$
\begin{eqnarray}
w_1*c_1 + ... + w_4*c_4+b_1 = d_1 \\
w_1*c_1 + ... + w_4*c_4+b_2 = d_2 \\
w_1*c_1 + ... + w_4*c_4+b_3 = d_3
\end{eqnarray}
$$
この数式は、重み \( w_1 \) から \( w_4 \) と入力 \( c_1 \) から \( c_4 \) の線形結合にバイアス \( b_1 \)、\( b_2 \)、\( b_3 \) を加えた結果が、それぞれ \( d_1 \)、\( d_2 \)、\( d_3 \) となることを表しています。
そして、3層目から最後の層まで、以下の式が成り立ちます。
$$
w_1 \cdot d_1 + w_2 \cdot d_2 + w_3 \cdot d_3 + b_1 = e_1
$$
上記の方程式における一つの問題は、その値が十分に単純または形式的でないことです。乗算と加算の値の範囲が非常に広いため、それを0から1のような小さな範囲に制約したいと考えます。そこで、シグモイド関数が登場します。
$$
\sigma(z) \equiv \frac{1}{1+e^{-z}}
$$
これはシグモイド関数の定義式です。シグモイド関数は、入力 \( z \) を 0 から 1 の間の値に変換する非線形関数です。この関数は、特にニューラルネットワークやロジスティック回帰などの機械学習モデルでよく使用されます。
シグマ記号 $\sigma$ に怯える必要はありません。それは単なる記号で、a という記号と同じです。入力として 0.5 を与えると、その値は次のようになります。
$$
\frac{1}{1+e^{-0.5}} \approx 0.622459
$$
そして、
$$
\begin{eqnarray}
\frac{1}{1+e^{-(-100)}} \approx 3.72*e^{-44} \\
\frac{1}{1+e^{-(-10)}} \approx 0.000045 \\
\frac{1}{1+e^{-(-1)}} \approx 0.26894 \\
\frac{1}{1+e^{-{0}}} = 0.5 \\
\frac{1}{1+e^{-10}} \approx 0.99995 \\
\frac{1}{1+e^{-100}} = 1
\end{eqnarray}
$$
上記の数式は、シグモイド関数の値をいくつかの異なる入力値に対して計算した結果を示しています。シグモイド関数は、機械学習やニューラルネットワークにおいてよく使用される活性化関数の一つです。この関数は、入力値が非常に小さい場合には0に近い値を、非常に大きい場合には1に近い値を出力します。具体的には、以下のように計算されます。
1. 入力値が-100の場合、シグモイド関数の値は約3.72×10⁻⁴⁴となります。
2. 入力値が-10の場合、シグモイド関数の値は約0.000045となります。
3. 入力値が-1の場合、シグモイド関数の値は約0.26894となります。
4. 入力値が0の場合、シグモイド関数の値は0.5となります。
5. 入力値が10の場合、シグモイド関数の値は約0.99995となります。
6. 入力値が100の場合、シグモイド関数の値は1となります。
このように、シグモイド関数は入力値の変化に応じて滑らかに0から1の間の値を取ることが特徴です。
ここが興味深いところです。この記事を書く前までは、上記のことを知りませんでした。今では、通常の入力に対するその近似結果の値について感覚がつかめました。そして、0から$\infty$までの入力に対してはその値が0.5から1の範囲にあり、$-\infty$から0までの入力に対しては0から0.5の範囲にあることを観察しました。
<div align="center"><img src="/assets/images/zen-neural/curve.png" width="100%" /><img/></div>
上記の方程式に関して、それらは正確ではありません。最も適切なものは以下の通りです。
$$
\begin{eqnarray}
\sigma(w_1*a_1 + ... + w_6*a_6+b_1) = c_1 \\
\sigma(w_1*a_1 + ... + w_6*a_6+b_2) = c_2 \\
\sigma(w_1*a_1 + ... + w_6*a_6+b_3) = c_3 \\
\sigma(w_1*a_1 + ... + w_6*a_6+b_4) = c_4
\end{eqnarray}
$$
上記の数式は、ニューラルネットワークの一層における活性化関数の適用を示しています。ここで、$\sigma$は活性化関数(例えばシグモイド関数やReLUなど)、$w_i$は各入力$a_i$に対する重み、$b_j$はバイアス項、$c_j$は出力を表しています。この式は、入力$a_1$から$a_6$までの線形結合にバイアスを加え、その結果を活性化関数$\sigma$に通すことで、出力$c_1$から$c_4$を得る過程を表しています。
したがって、最初の方程式は次のようになります。
$$
\frac{1}{1+e^{-(w_1*a_1 +...+ w_6*a_6+b_1)}}
$$
この数式は、シグモイド関数を表しています。シグモイド関数は、ニューラルネットワークやロジスティック回帰などの機械学習モデルでよく使用される活性化関数の一つです。この関数は、入力値(ここでは \( w_1*a_1 +...+ w_6*a_6+b_1 \))を0から1の範囲に変換します。具体的には、入力値が大きくなると出力は1に近づき、小さくなると0に近づきます。この性質は、確率を表現するのに適しています。
新しい重み $w_1$ をどのように更新すればよいでしょうか?つまり、
$$
w_1 \rightarrow w_1' = w_1 - \Delta w
$$
方程式に対して、
$$w_1*a_1 + w_2*a_2+...+ w_6*a_6+b_1$$
$w_1$ に関するその導関数は $a_1$ です。この和に $S_1$ という記号を与えましょう。
それでは、
$$
\frac{\partial S_1}{\partial w_1} = a_1 , \frac{\partial S_1}{\partial w_2} = a_2, ...
$$
微分とは変化率を意味します。つまり、$w_1$ の変化 $\Delta w$ に対して、結果 $S_1$ の変化は $a_1 * \Delta w$ となります。では、この計算をどのように逆にできるでしょうか?計算してみましょう。
$$
\begin{eqnarray}
S_1' - S_1 = \Delta S_1 \\
\frac{\Delta S_1}{a_1} = \Delta w \\
w_1- \Delta w = w_1'
\end{eqnarray}
$$
そして、連鎖律は、$f(g(x))$の導関数が$f'(g(x))⋅g'(x)$であることを説明しています。
そこで、
$$
\begin{eqnarray}
f(z) = \sigma(z) = \frac{1}{1+e^{-z}} \\
g(x) = w_1*a_1 +...+ w_6*a_6+b_1
\end{eqnarray}
$$
上記の数式は、以下のように表されます。
1. シグモイド関数 \( f(z) \) は、入力 \( z \) に対して \( \sigma(z) = \frac{1}{1+e^{-z}} \) として定義されます。
2. 関数 \( g(x) \) は、重み \( w_1 \) から \( w_6 \) と入力 \( a_1 \) から \( a_6 \) の線形結合にバイアス \( b_1 \) を加えたものとして定義されます。
そして、シグモイド関数の導関数は、
$$
\sigma'(z) = \frac{\sigma(z)}{1-\sigma(z)}
$$
したがって、$f(g(w_1))$ の導関数は $\frac{\sigma(z)}{1-\sigma(z)} * a_1$ となります。
それでは、
$$
\begin{eqnarray}
\frac{\sigma(z)}{1-\sigma(z)} * a_1 * \Delta w = \Delta C \\
\Delta w = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)} * a_1}
\end{eqnarray}
$$
そしてバイアス $b_1$ については、
$$
\begin{eqnarray}
g'(b_1) = 1 \\
\frac{\sigma(z)}{1-\sigma(z)} * \Delta b = \Delta C \\
\Delta b = \frac{\Delta C}{\frac{\sigma(z)}{1-\sigma(z)}}
\end{eqnarray}
$$
## コード
変数を表示する方法は非常に便利でシンプルですが、最近ではJupyter Notebookのようなツールがその役割を果たしています。Zhiweiが以前に述べたように、ニューラルネットワークを理解するための鍵の一つは、次元に注意を払うことです。
```python
def print_shape(array):
arr = np.array(array)
print(arr.shape)
print(len(test_data[0][0])) # 10
print_shape(training_results[0]) # (784, 1)
print(list(training_data)[0:1]) # <class 'list'>
このコードスニペットは、Pythonで配列の形状を表示するための関数 print_shape を定義しています。具体的には、以下の処理を行います:
print(len(test_data[0][0]))は、test_dataの最初の要素の最初の要素の長さを表示します。この場合、結果は10です。print_shape(training_results[0])は、training_resultsの最初の要素の形状を表示します。この場合、結果は(784, 1)です。print(list(training_data)[0:1])は、training_dataをリストに変換し、その最初の要素を表示します。この場合、結果は<class 'list'>です。
このコードは、主に配列やリストの形状や内容を確認するために使用されます。
現在、Zhiweiはデータの読み込み部分を終えたばかりで、これからも同じように数行をコピーして変数を出力する方法を使って、ニューラルネットワークの実際の部分を学んでいく予定です。進捗はこちらでフォローできます: https://github.com/lzwjava/neural-networks-and-zhiwei-learning.
私は進捗の中で何度か行き詰まりました。非常にシンプルなコードに見えるにもかかわらず、一度に一度理解しようと試みた後、失敗しました。そして、私は現在のコードの行から自分を引き離し、高いレベルからそれを見て、なぜ著者がその部分のコードを書いたのかを考え、突然理解しました。以下がそのコードです。
def load_data_wrapper():
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
上記のコードは、検証データを準備するためのものです。validation_inputs は、va_d[0] の各要素を形状 (784, 1) に変換したリストです。その後、validation_data は、validation_inputs と va_d[1] を組み合わせたイテレータを作成します。
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
上記のコードは、以下のように動作します:
test_inputsは、te_d[0]の各要素を形状(784, 1)に変形したリストです。test_dataは、test_inputsとte_d[1]を組み合わせたイテレータです。- 最後に、
training_data、validation_data、test_dataの3つのデータセットをタプルとして返します。
このコードは、機械学習のデータセットを準備する際に使用される典型的な処理です。
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e
ここで、変数の次元は複雑です。しかし、著者の意図を考えると、いくつかの手がかりがあります。見てください、コードは3つの似た部分で構成されています。そして、各部分は変数の名前が異なるものの、ほとんど同じです。今、私にとっては非常に理解しやすいものに見えます。zip、リストに対する「for」操作、そしてreshape関数。変数の値を何百回も出力し、なぜそのような値になるのかを理解しようとするうちに、理解が積み重なっていくのです。
そして、Zhiweiは常にエラーを非常に価値あるものと考えています。以下のコードのように、彼は多くのエラーに直面します。例えば、
- TypeError: 画像データに対する無効な形状 (784,)
- ValueError: シーケンスで配列要素を設定しようとしました。要求された配列は2次元以降で不均一な形状を持っています。検出された形状は (1, 2) + 不均一な部分です。
エラーのスタックトレースは、まるで美しい詩のようです。
また、Visual Studio Codeで値の出力をフォーマットすると、非常に読みやすくなります。
[array([[0.92733598],
[0.01054299],
[1.0195613],
...
[0.67045368],
[-0.29942482],
[-0.35010666]]),
array([[-1.87093344],
[-0.18758503],
[1.35792778],
...
[0.36830578],
[0.61671649],
[0.67084213]])]
このコードブロックはPythonのNumPy配列を示しています。各配列は2次元の数値データを含んでおり、それぞれの要素がリスト形式で表示されています。このようなデータ構造は、機械学習やデータ分析の分野でよく使用されます。
読んでくれてありがとう。Thank you for your reading.
注:一部の画像は書籍「Neural Networks and Deep Learning」から引用しています。